Internet Archive���� (web.archive.org) #2�@©2ch.net
���X����1000���Ă��܂��B����ȏ㏑�����݂͂ł��܂���B
�@
�@�O�X���b�h
Internet Archive���� (web.archive.org) #1
http://echo.2ch.net/test/read.cgi/esite/1189771222/
�@ �@
�Ȃ��ł����b�ɂȂ��Ă�Internet Archive�ɂ��Č��܂��傤
Internet Archive
ttp://www.archive.org/index.php
�C���^�[�l�b�g�E�A�[�J�C�u - Wikipedia
ttp://ja.wikipedia.org/wiki/InternetArchive
�@�@------------------
�p.Internet Explorer�œ��{��Ȃǂ�2byte����̃y�[�W��Web Archive�L���b�V�������悤�Ƃ��Ă�
�^�����ȃy�[�W�������������N���違�ɒ[�ɏd���Ȃǂ̏Ǐo�Ă��܂�
�`.[�\��]�������͉E�N���b�N��[�G���R�[�h]��[���{��(�����I��)]�₻�̌���̕����R�[�h�ɑ��������̂��N���b�N
�p.Web Archive�Ń_�E�����[�h����zip�Ȃǂ��J���Ȃ���CRC���Ⴄ�ƕ\�������
�`.�悭Web Archive��1byte�������N�����̂Ńo�C�i���G�f�B�^�ȂǂŊY���t�@�C�����J���A
16�i���̍Ō�̖����Ɂu00�v��t������Ɛ���ȃt�@�C���ɂȂ邱�Ƃ�����܂��B
�@ �e���v���̂p���`�A�܂�����Ȃ������ʗp����Ǝv���Ă�z����́H ����ŃC���t�H�V�[�N�̏������y�[�W������@�Ȃ��́H Internet archive��Youtube�̓�����_�E�����[�h����̂ɊȒP�ȕ��@�͉�������܂����H >>9
�C���t�H�V�[�N���g�̓��{�b�g������ robots.txt ��u������
�R���e���c�� Internet Archive ���炲������폜��������Ƃ������Ƃ�
����Ă��Ȃ��̂ŁA�A�[�J�C�u�����c���Ă���Ζ��Ȃ������܂��B >>11
���R���e���c�� Internet Archive ���炲������폜��������
����ǂ��������ƁH�@�폜�Ȃ�Ăł���́H Youtube�Ƃ�robots.txt�ŕۑ��ł��Ȃ��T�C�g�́A
Archive.is���E�F�u����ƌo�R������ƕۑ��ł����
���ꌋ�\����Ă铤�m�� robots.txt��
Disallow: /
Allow: /nullpo/
�Ƃ��A���E�w�肳��ĂĂ������ĂȂ��Ĉꊇ�ł͂���������ɂ� >>15
�ꕔ�̃N���[���� Allow ���̎������n�߂�O�́A
������ robots.txt �̎d�l�œ��삵�Ă���Ă��Ƃ��ˁB �T�[�r�X�I������nifty�̕ۑ����Y��Ă��T�C�g��Internet archive��
�T���x�[�W���悤�Ǝv�����̂ɏo����T�C�g�Ƃł��Ȃ��T�C�g�������
homepage2.nifty.com��This URL has been excluded from the Wayback Machine.���o�đS���_����
homepage3.nifty.com�͂����� ����2�̕��̓A�[�J�C�u����ĂȂ����Ă��Ƃ�
�f�[�^�x�[�X�n�T�C�g�̏������ܑ̖��� $50�̕���H���K�v�H
1000�~���炢�Ȃ略���Ă��������ǁB �O��500billion�y�[�W�����Ă��C�����邯�Ǖۑ��y�[�W�ւ��ĂȂ��H
�������ȑO�ۑ��������̂������Ă݂���ۑ��ł��ĂȂ��� >>21
ttp://web.archive.org/web/20161015012725/archive.org/web/web.php
510 billion web pages saved over time.
���ꂪ�ō��l���ȁB10 ����ɂ͔������Ă�B paypal�Ŋ�t���悤�Ƃ�����JP���炶��_������ꂽ >>23
����˂��B�^�c�ꂵ���̂��� ��Chrome�ŃA�N�Z�X���ĉߋ��y�[�W����Ƃǂ������Ă��t�@�r�R�����u�����܂ɂ����v�ɂȂ���lj������H �\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\ �\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\ �P��Ō����ł�����ō��Ȃ̂ɂ�
URL��������Ȃ��Ⴙ�������ۑ�����Ă�ߋ��̈�Y���i���Ɍ���Ȃ��܂܂Ƃ��� �̂��������ǂ���ς�d�������̂��� >>23
�܂��umore than�v���Ă��ƂŁc �ߋ��ɂ������t�q�k���L�b�`������ĂĂ��ς�Ȃ��T�C�g���Ă���ˁB ������̎��Ԃ�9���Ɏ擾���ăA�[�J�C�u���������Ƃ��̕\���ɂȂ���62�y�[�W�̂���
20������Ƃ����s���Ă邱�Ƃ����m�F���ĂċC�t����
�g���Ă��[���Ƃ��̊����擾�Ώۂɂ����h���C�������U���Ă邩�炠����̖��ۂ�
���̂�����Ɏ�����l�͐������Ă邩�`�F�b�N�����ق����������� ���������Ƃɂ悭�����Ȃ��������� http://page.freett.com/brave_heart/atm_inspire/
�������̃T�C�g��Flash�����悤�Ǝv���āA�ŋ߂̓����̂���ƕ\������Ȃ�����Â������̂���悤�Ǝv�����珟���infoseek�̃g�b�v�ɔ����Ă��܂��c
�����Ȃ��悤�ɂ��邱�ƂƂ��o���ʂ̂�
(�u���E�U��edge�Achrome�AFirefox) ���Ă݂�����Infoseek�g�b�v����Ȃ���http://binyudaisuki.hp.infoseek.co.jp/�ɔ�����Ƃ��Ă�(������infoseek�����g�b�v�Ƀ��_�C���N�g���Ă�)�B
Flash�̂��Ƃ͒m��Ȃ����ǁA���T�C�g(���̏ꍇweb.archive.org)����̍Đ������o���Ă����ɔ���A�݂����Ȃ̂��g�ݍ��܂�Ă��Ȃ��́H �o�C�i���G�f�B�b�^���ĕ����������摜�������ł����A����Ă����_�l���܂����H
�ׂꂽ�B�e��n�T�C�g�̃A�[�J�C�u�f�[�^�Ȃ�ł����A��A�̉摜�̂����A�قڔ���������ĊJ���܂���
�i�킢�������W�|�����F���̃s�`�s�`�Ƃ������t�Ƀn�}��Ȃ��N�\�܂�Ȃ��摜���Ƃ����͈̂�A�̉摜�Ȃ̂ł킩��܂��B�j �ŋ�robot.txt�Œe�����̑�������
�������̓���Ƃ��݂�Ȃǂ�����ĕ⊮����낤
>>29
�����̃t�@�r�R���͂�������イ������@�����͕s������
�ŋߎ����������T�C�g�̂��̂Ɠ���ւ�邱�Ƃ�����
archive���̂̃t�@�r�R���͂����Ƃ���̂ɂ� ������璲�q�����Ĉ�Ք��@������Ȃ���
�����e�ł�����Ă�̂��� ������������Ȃ��ėǂ������B
���炭�l�q���Ă݂邩�B ���Ƀc�C�b�^�[�{�^���Ƃ������̂�
�����ƌ����悤�ɂ��Ă��� �u�N�}���Ă�IA�̒��̖^�T�C�g�����ꂢ�����ς���ł��Ă� �����̃T�C�g�����r���[�ɃA�[�J�C�u����Ă��Ēp����������������
�Ȃ��txt���ꂽ��ߋ��̕����A�N�Z�X�ł��Ȃ��Ȃ��������ꂶ��Ȃ��̂� nifty���p�������������̂��� �Ȃ����O����ˑR�c�C�b�^�[�Ƃ����̃T�C�g���F�Xrobot.txt���]�X�ŕۑ��ł��Ȃ��Ȃ��ĂĐ�]���Ă����ǁA�݂�Ȃ������������̂�
�F�X�ȃT�C�g���d�l�ύX������Ȃ���InternetArchive�̕����������������̂��H >>54
�����̃u�N�}���Ă��ߋ��ɃA�[�J�C�u���Ƃ����͂��̃y�[�W������Ȃ��Ȃ��Ă��c���̂܂܂�������ň��� ��{�{�b�g�d����Ŏ擾NG�ɂ��₪���� �t���[�����g�p���Ă��y�[�W���S�Č���Ȃ����� firefox10�ŕ\���ł��Ȃ��Ȃ����B
����Ƃ͕ʂɁArobots.txt�̂����ŕ\���ł��Ȃ��T�C�g������̂��đS�̓I�ɂ����Ȃ́H �t���[���̌��̓T�C�g�����^�u�ɏo�邩�璼��\�������邯��
biglobe�n�̃T�C�g���S��?���Ă��܂����̂��ɂ����� �Ȃ�Ƃ��A�[�J�C�u�ł���T�C�g�ł��\�����������ςɂȂ��Ă� co.jp/�@�̕\�����@co.jp:80/�@�ɂȂ��ĂȂ��H
���n���k���URL�����������Ȃ�� ����͑�̂���̎d�l
�ߍ��̕s��ƈ�؊W�Ȃ� ��͂�s��������ł��ˁB
�ۑ����悤�Ƃ����u���O�������������Ă��܂��B ������@��ˑ�����������������Ƃ������Ȃ�
2014 �N 7 ���ɂ��łɎn�܂��Ă���͂��B
���� Shift_JIS �� Windows-31J �ȕ������A�����܂Ō����� Shift_JIS �Ƃ���
UTF-8 �ւ̕ϊ����|���Ă��܂��Ă��ˁB biglobe�n������ꂽ�̂͒n���Ƀ_���[�W�ł����� �t���[���̃y�[�W�͌����悤�ɂȂ������A�ʏ�͏�ɕ\�������_�O���t���o�Ȃ��ȁB
�t���[������Ȃ��y�[�W�ł��_�O���t�̂Ƃ��낪�^�����ɂȂ�̂�����B >>74
���������ǁA�����^���T�[�o�[�Ɏ����̃y�[�W������č폜���h���C�����ƌ���Ȃ��Ȃ邾�Ǝv��� �Â��T�C�g�̋�����Ƃ�ꍇ��Google�L���b�V����archive_is�������������Ȃ�����m�����Ǝv�� IA�ƈ���ĉ��N����̑����ɂ͂�����ƕs���͂��� IA���N�����폜�˗�����h���C�����ƌ���Ȃ��Ȃ�Ƃ������_���邩��Ȃ�
�h���C���i�T�u�܂ށj�ۗL�҂Ȃ�robot.txt��ݒu���邾���Ō���Ȃ����邱�Ƃ��ł��邵 IA�Ȃ甼�i�v�I�Ɏc��Ǝv���č��܂ňꐶ�������Ă����̂��قڑS�ł��ċ������c �ŋߋ�opera���Ƃ��܂��@�\���Ȃ��Ȃ������炨�������Ǝv�����瑼�̃u���E�U�������Ȃ̂�
�A�h���X����������������J�����_�[��ʏo���Ȃ��Ȃ�����
JS���1���������o�Ă���(��������o�^����ĂĂ�)
�V�X�e���߂��Ăق��� �{���ɑO�Ɣ�ׂĂ��Ȃ�̃T�C�g������ł��Ȃ��Ȃ��Ă邵�\�����������������܂ł̋�����啔������Ȃ��Ȃ��Ă邵�ŃC���C������ �����_�������̃T�C�g�g�����ɂȂ��c Bummer
Hrm
robot.txt
���������ō��l�b�g��9���ȏ�̃T�C�g������őS���ۑ����{�����ł��Ȃ��Ȃ��Ă銴���Ȃ��ǁH
InternetArchive�̓l�b�g�̕ۑ����W������߂��́H�o�J�Ȃ́H �u���������ƃn���}�̓����[�h�����玡�邱�Ƃ������C������ ����T�C�g(�W�I)��10����T�C�g�������N�̂���6���u7d6 0�v�Ƃ����\������Ȃ����ǁA
������ĉ��ł�������܂����H
��4�͐���ɕ\��������ł����c�c �uHTML �̓A�[�J�C�u����Ă��邯�ǁA�����Ŏg���Ă���摜�̓A�[�J�C�u�����v
�Ƃ����̂Ƃ��A���̉摜�ɂ��ĈȑO�� /save/ �� URL �Ƀ��_�C���N�g����
�I���W�i���T�[�o�֓ǂ݂ɍs�����Ă����̂��A���� 404 ��Ԃ������ɕς�����B >>89
Sorry. This URL has been excluded from the Wayback Machine.
���ꂪ�����Ă� ���̊ۃ}�[�N�����邮�������܂܁A�y�[�W���J���Ȃ� ���H
����������firefox10�������́H
������܂Ŏg���Ă��̂ɁB �����y�[�W�̏�ɕ\�������O���t��玞�Ԉړ��̍��E���������Ă�̂�IA���̕s��ł����H
��ԐV�����o�^����ړ��ł��Ȃ��͕̂s�ցB�u���E�U�ς��Ă��_�� �Â��u���E�U�ł͓��삵�Ȃ��Ȃ��Ă��܂��ˁB
Firefox 13.0.1 ttp://i.imgur.com/D8ugVF8.png
Firefox 14.0.1 ttp://i.imgur.com/3VhIJse.png
Firefox 21.0 ttp://i.imgur.com/OqutIJD.png
Firefox 22.0 ttp://i.imgur.com/GFL3Imq.png
14.0.1 �` 21.0 �ł̓J�����_�[�͈ꉞ�\�������̂ł����A
���t���c�ɕ��сA���̌��̐����Əd�Ȃ��Ă��܂��̂Ŏg�����ɂȂ�܂���B >>82
���̂����S�T�C�g��robots.txt��excluded�Ō���Ȃ��Ȃ肻�� �悭����ȃe�X�g�����������Ă�Ȃ� >>101
PortableApps.com �̃|�[�^�u���łł���B
Windows XP ���̂����z���ł��āA���̉��z�}�V�����p�ӂ���
�f�� Firefox �̊e�o�[�W�������ʂɃC���X�g�[�������Ƃ��Ă��A
�����_�����O�Ɋւ��Ă͗L�ӂȍ��͏o�Ȃ��Ǝv���܂��B 2000���ƁA�܂Ƃ��Ɏg����ŏIfirefox��10�Ȃ�B �Ȃ�ق�2000
�������ǂ�����2000��Internet Archive Windows 2000 SP4 + Opera 12.02 ���ƃJ�����_�[�͏o��̂ł����A
���t���c���ɂȂ��Ă��܂��܂��ˁB
�f�� Windows 2000 �ł͂��̕ӂ����E�ł��傤���B
ttp://i.imgur.com/QxJpn2k.png
�������͖������� Windows 2000 (^_^;)
ttp://i.imgur.com/WTJsWcj.png ���t�[�̃j���[�X�L���Ƃ��L�^�ł��Ȃ���
�g�b�v��ʂɖ߂���� >>107
ttp://echo.2ch.net/test/read.cgi/esite/1189771222/823-834 ���܂Ŏ����̓��L�u���O�����Ƃ��Ă��������������Ă���
���Ƃ��T�[�r�X�I�����Ă�IA�̒��ɂ͎c�葱���邾�낤�Ǝv���Ă��̂�
�ˑRrobot.txt�ɂ��֎~�ō��܂ŕۑ����Ă�����������ׂČ���Ȃ��Ȃ���
�����̂��Ă������͉��̈Ӗ��������������lj����c��Ȃ��Ǝv���ƂƂĂ��������c���Ȃ̎d�ł��� �C�~�t
���l����Ȃ����g���A�J�E���g�Ǘ����Ă�u���O�Ȃ���
���J/����J�̐ݒ��킸���̋L���ł��{����ҏW�ł��邶���
�ʋƎ҂̗ގ��T�[�r�X�ֈ����z���Ƃ������R����
�Ȃɂ��I�t���C���œǂݕԂ���_�C�A���[�Ƃ��ĒԂ��Ă������Ă���
���҂����Ă�̂ɏ���������߂ȓr������̂� ������ɂ���u���O�T�[�r�X���I�����h���C����������ꂽ�Ƃ��ɂ͕s�����̂悤�ɑh�邱�ƂɂȂ�ł��낤 >>110
�l��ƂŗV��ł邾���Ȃ̂ɉ�������Ȃ��ƌ����Ă��?
�����܂ł�肽�������玝���Ɣ�����B
���[�U�p�̋�Ԃ��f�B���N�g���`�� (blog.example.com/user/) �Œ��Ă��鏊��
robots.txt ���猩��u�Ǘ��������̎؉Ɛl�v�����炵��[�Ȃ���ȁB 1������܂ł̓t���擾�ł��Ă��T�C�Y�̃t�H�g�M�������[�I�ȃy�[�W��
�ŋߎ��ƂƂ���ǂ��뎕�����ɂȂ�
png��jpg�̌ʃA�[�J�C�u�߂�ǂ������邾���ǂ��� ���������robot�ŋ���ł��Ȃ��Ȃ��Ă��T�C�g���܂��ł���悤�ɂȂ��Ă�I�������I ���g�̃u���O�Ȃ�IA�łƂ��Ă������
�������L����
�����̎��Ȃ�đ��҂͂����Ȃ����Ă̂�
��ɂ��u�������v�Ƃ��E�E�E�a�I�Ȏ��ӎ��ߏ���
�댯�l�� ����ł��������Ɏ��炪�c����������@��N������ċ���������̂͂������g
���Ǝ��� �u���O = ������ĕ��Ζ��̔��z����� �����c�������l�̏���
IA�̎�|�ɂ͉����Ă邵 ����A�����c���Ă������Ǝv������
�˂����ނȂ��
�厖�ȕ������܂ł��c���Ă�����i��IA���g��
�Ƃ������ł�^_^; ���E�z�M���Ď�����܂��������ƌ����Ďc�����u���O�����U�ŏ����ꂽ���ǒN����IA�ɕۑ����Ă��������œǂ߂��� ameblo��IA�ŊJ���ƁA�g�b�v�y�[�W�̓A�[�J�C�u����Ă��邯�ǁA
���ʂ�X��URL������ƃA�[�J�C�u����Ă��Ȃ����Ƃ������B
�܂��Aameblo�Ɍ������b����Ȃ����B HTML�����ʼn摜���S�ł��Ă����Ăǂ������A�[�J�C�u�̂��ꂩ���Ȃ� >>125
���ʂɗL�蓾���Ƃ��ẮA���̃T�C�g�ɒ������������|�����Ă���
�摜�����̃��t�@���[�̃`�F�b�N���s���Ă����Ƃ��B Alexa�͉̂摜�Ȃ������肷��݂����� �f���̏����ƃN��ver1.0��2003�N�̃t�@�C�����Ƃ�����
����2007�N��2008�N��2015�N�̓��t�̃t�@�C���������Ă��� �����Ӗ�����̂��ȁB
�u���O�Ńg�b�v�ɕ\�������邽�߂�2050�N�Ƃ��̋L��������悤�Ȃ��̂������肷��́H �����܂�����Ȃ��Ȃ����T�C�g�������
�]�v�ȉ������Ă��� ���N���O����URL�Ɂu:80�v������o�O�Ō���Ȃ��p�^�[���o�Ă���� ����A�����������S�Ƀ_���ɂȂ肻���� �ߋ��̕ۑ��A�[�J�C�u�̑唼������ł�B�����@�\���ʖڂ����c
�~���[�I�͎�͌����@�\�Ńq�b�g���邪��͂肠��͂��A�[�J�C�u�ɂ̓G���[�Ȃ̂����ǂ���Ȃ��B �A�[�J�C�u�σy�[�W���疢�A�[�J�C�u�y�[�W�ւ̃����N���ނ�
�O��save this url��ʂɂȂ����̂�
���Ȃ�������404�ɂȂ��Ă��������{�b�N�X��url����Ȃ���Ȃ̂Ŗʓ| �Ƃ��Ƃ��~���[��top�܂ŗ������c ��߂ď��߂ė������A����Ȕ������̂��c�c
�q����Ȃ��͉̂���������Ȃ������ȁc�c
�����g���Ȃ��ƃ}�W�ō���܂���c�c �g�b�v�i�z�[���j�y�[�W�������������B 503��504�őS�R�Ȃ���Ȃ�
����1�N�ŏI���낤�� �������v���Ԃ�Ɏg���Ă����A�S�R�Ȃ���Ȃ��Ȃ����̂Œ��ׂĂ���
�����ƒ��q���������̂�
�֗��Ȃ��ǂ� �����X���[�c����
�L���Ɋւ��ĐV�������̂��擾�ł��Ȃ��Ȃ��Ă�I�H
2�`3���O�܂łɎ�����L���͕\���ł����
����Ŏ擾�s�\�ɂȂ�������i�g�b�v�y�[�W�͏����j
�������g���Ȃ��Ɖ��C�ɍ��� �y�[�W�ɂ���Ď��n��\�����o��̂Əo�Ȃ��̂����邯�ǁA�����Ⴄ�낤�H >>146
/save/ �ōs���Ă�݂��������ǂȂ��B ���t���ς���č���ɂȂ邪�A18�����납��1���Ԃ��炢�A
�^�C���A�E�g�Ƃ������āA�g�����ɂȂ�Ȃ������B
���̎��ԑт�1���Ԃ��g���Ȃ������̂��āA�ق�ƍ�����c�B ������ƌÂ��u���E�U�œ����Ȃ��y�[�W���Ăǂ�ȍ����Ȃ́H IA���ɗ����Ȃ�URL���Ƃ���
�Z�[�����Ȃ��Ƃ����I���Ȃ�������
������Ɗy����ɂȂ��� >>153�����ǁA���̂��������悤�Ɏd�l�ύX�Ǝv������
�ȑO�Ɠ�����404�f���̂ɖ߂��Ă���
���Ȃ݂ɍ���擾�����y�[�W�́A�^�����l�̃u���O2017.8.29�[���A�b�v�L��
���傤�擾�����̂́A����Ɠ��A�J�̃u���O���̍�ӃA�b�v�L�� ���������낱��ς��Ƃ��͂���C������ˁB > IA���ɗ����Ȃ�URL����
�ł݂�����
�N���b�N�Ɠ�����"Saving page now..."�ɂȂ�y�[�W��404�̃����N�b�V���������y�[�W�Ƃ����݁B
���̐l�炪�ǂ����ǂ��������Ă�̂��m������͕s����ȏ�Ԃ����������B
�܁[�ǂ��ɂ������ɂ��擾�ł��Ă��ł��肪�����t���[���p�����Ă��炢�܂� �����i�W���R�P���j�A�uWayback Exception�v�Ƃ����\�������x���o�āA
�T�C�g�̎擾��W���Ă������ǁA����ꂽ���͂��܂����H
�uException�v�́g��O�h�Ƃ����Ӗ��炵�����ǁA�����̂悤�Ɏ���Ă�T�C�g��
���̂悤�Ȍ��ۂ��N�����̂ŋ����Ă�B
���݂ɍ���i�X���P���j�͋t�ɁA���̕\������،��Ă��Ȃ��B >>158
������v���O���~���O�p��́u��O�v�ł���?
�ǂ����ė�O�����������̂����ĂȂ���?
 >>159
>>159
�����A�m���ɂ��̕\���Ȃ̂����A
���ǂ����ė�O�����������̂����ĂȂ���?
�����܂ł͌��Ă��Ȃ��A�Ƃ�������������Ȃ��B
������A���i����擾���Ă��镡���̐V���Ђ̃j���[�X�T�C�g��
����Ƃ����Ă����ۂɁA���̌��ۂ��N��������B
�ǂ��ɂ��������v�����Ȃ��B Shift_JIS ���錾����Ă��Ă� Windows-31J �Ƃ��ď����������悤��
�Z�ʂ͗������Ă���Ȃ����̂��낤���B
http://web.archive.org/web/1/mevius.2ch.net/test/read.cgi/esite/1475246713/161
�@�A�B�C�D�E�F�G�H�I�J�K�L�M�N�O�P�Q�R�S�T�U�V�W�X�Y�Z�[�\�]�_�`
�a�b�c�d�e�f�g�h�i�j�k�l�m�n�o�p�q�r�s�t�u�~��������������������
�����������������
�@�A�B�C�D�E�F�G�H�I�U�V�W�\�]�^�_�`�a�b�c�d�e�f�g�h�i�j�k�l�m�n
�o�p�q�r�s�t�u�v�w�x�y�z�{�|�}�~��������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
��������������������������
�@�A�B�C�D�E�F�G�H�I�J�K�L�M�N�O�P�Q�R�S�T�U�V�W�X�Y�Z�[�\�]�^�_
�`�a�b�c�d�e�f�g�h�i�j�k�l�m�n�o�p�q�r�s�t�u�v�w�x�y�z�{�|�}�~��
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
��������������������������������������������������������
�@�A�B�C�D�E�F�G�H�I�J�K >>161 �� (0x8794) �� �� (0x9487) �ɉ����Ă邯�ǁA����� 2ch ���̖�肾�ȁB
��̓I�ɂ́A �̕����� 1 �ȏ�̘A���̂����A�擪�o�C�g������
�Ȃ��� HTML ��ł͒E������B
��u���� dat �ړǂ�ł���ΒE���͋N����Ȃ��B
�o�C�g��ŕ\������Ƃ���Ȋ����B
41 41 87 94 87 94 87 94 87 94 41 41 (AA�������AA)
��
41 41 -- 94 87 94 87 94 87 94 41 41 (AA�������AA)
http://web.archive.org/web/1/mevius.2ch.net/test/read.cgi/esite/1475246713/163
�Z�p�L���� �ł͂Ȃ��āA�M���V�������� �� (0x83B0) ���ƋN����Ȃ��B �ق�Ƃ����A�N�Z�X�ł�����Ȋ������� �擾�����y�[�W�㕔�̃f�U�C�����܂��ς�����Ȃ�
�������Ȃ�����傫���Ȃ�����ɒ[�� �i�ߋ��ɂ����������ǁj
�ꕔ�̃T�C�g�ŁA�ȑO������A�h���X���A���Ȃ��Ȃ��Ă�ȁB
����Ă��A�����_�ōŐV�̂��̂����o�Ă��Ȃ��B
https://web.archive.org/web/20170913155359/https://www.daily.co.jp/gossip/
https://web.archive.org/web/20170913094650/https://www.nikkansports.com/battle/ �����ЂƂ���������ė���
�݂�Ȃ��E����
���R�Ȃ�ĊȒP��
�����Ɏア�ЂƂ�������������
���B�͔Ƃ���
�V�l�Ǝq���͔R�₳�ꂽ
�����ЂƂ����͂��̓y�n��
�Ƃ����ĂĎq����
�����ĊX���ł�
�����ЂƂ����̎q���͑���������
���N�i���R �֓���k�� ���{�l��s�E
https://goo.gl/1ntWvZ
https://youtu.be/D0vgxFC04JQ
https://goo.gl/h1o4eV
https://www.youtube.com/watch?v=sYsrzIjKJBc
https://goo.gl/FTqHJ1 ���������̂������Ɠǂ�Ŕ������Ă�낤��
�ⓚ���p�Œe���Ă�悤�Ȉ�ۂ����邪
http://yahoo-mbga.jp/robots.txt User-Agent: *
Disallow: /
�������ꂾ���ǂ�ł�߂Ă�C�����ĂȂ�Ȃ� 10�����炢�O����g���Ȃ��Ȃ��Ă�
�����N���� ���ށA�܂���
�����e�̗\���͂Ȃ���ˁH �����Ă��
���̂Ƃ��돇������������ �l�b�g���[�N�f�f����
�f�o�C�X�܂��̓��\�[�X�iweb.archive.org�j���������Ă��܂���B �����A�}�ɉ��q�X�N�����Ă��c >>168
�ⓚ���p�������A���� robots.txt ���K���ʂ�ɉ��߂�����
Internet Archive (ia_archiver) �̏ꍇ�͑S���ۂɂȂ�̂����B
| User-Agent: ia_archiver
| Disallow: /
���̏������� "User-Agent: *" �Ŏn�܂�O���[�v�����邪�A
��� "User-Agent: ia_archiver" ��D�悷�邽�ߖ��������B
| User-Agent: *
| Disallow: /
| Allow: /sitemap
| Allow: /$
| ...
���ɏ�� "User-Agent: ia_archiver" �Ƃ��̎��̍s�����������Ƃ��Ă��A
Internet Archive �� Allow ���߂ɂ͑Ή����Ă��Ȃ��B
�܂�A"User-Agent: *" �Ƃ��̎��� Disallow ���߂��������߂���āA
�ǂ����݂��S���ۂƂȂ�B ���x��Yahoo�X�|�[�c�̐��b�ɂȂ��Ă������A�v���Ԃ�ɌÂ��y�[�W��
���悤�Ƃ�����f�[�^�����Ȃ��Ȃ��Ă�ȁB �擾�����b�T���Əd�������ǎ��ԑт̂������� Saving page now...���������Ǝv������܂��\������
Saving page now...�����x�����������Ǝv������܂��\������
Saving page now...���i����
���̎������[�v�Ɋׂ��Č��ǎ蓮�Œ�~�������
�ォ��m�F���Ă݂�Ǝ��Ă�̂Ǝ��ĂȂ��̂�2:1���炢
�߂�ǂ��� �摜���S�R�ۑ��ł��ĂȂ���
���肷��Ƃ������ۑ��������̂��������y�[�W��2009�N���炢�̃X�i�b�v�V���b�g�̂ق�����������摜�����ꂽ�肷�� >>184
Bummer��3�`4��J��Ԃ����̂�
���ɍ��C�������������Ȃ��Ă��
����19���䂪�����C�����邯��
�P�ɋC�̂������� �C�̂�������
�S���ԑт܂�ׂ�Ȃ����� �E�F�u������u�X�J�v�������Ȃ�����
����̗ނ�����Ȓ��q���Ɩ{���ɍ��� ����Bummer�o��̂��f�t�H�ɂȂ��Ă��
���P����鎞�͗���̂��낤�� URL�����@�\�����ς�炸���܂�܂�c �����@�\����/*/�`*�݂����Ȃ�H �͂��H
 ��{�͐挎��肾���Ԓ��q�悩�������������܂��_���_�� ���N�~����擾�����̂�"/"������ɉ������Ă�404���������� �����ЂƂ���������ė���
��{�͐挎��肾���Ԓ��q�悩�������������܂��_���_�� ���N�~����擾�����̂�"/"������ɉ������Ă�404���������� �����ЂƂ���������ė���
�݂�Ȃ��E����
���R�Ȃ�ĊȒP��
�����Ɏア�ЂƂ�������������
���B�͔Ƃ���
�V�l�Ǝq���͔R�₳�ꂽ
�����ЂƂ����͂��̓y�n��
�Ƃ����ĂĎq����
�����ĊX���ł�
�����ЂƂ����̎q���͑���������
���N�i���R �֓���k�� ���{�l��s�E
https://goo.gl/FTqHJ1
https://goo.gl/1ntWvZ
https://youtu.be/D0vgxFC04JQ
https://goo.gl/h1o4eV
https://www.youtube.com/watch?v=sYsrzIjKJBc �y�[�W���̂��\������Ȃ����A���͂ǂ������H�@�����e���H Wayback Exception
An unknown exception has occurred. Unexpected Error
������� �A�[�J�C�����ꂽ���ƂȂ��y�[�W�ւ̃����N����
�v�X��404�ɂȂ炸"Save this url in the Wayback Machine"������ăN���b�N�擾���ł���
����펞�ł��Ă��̂��ĉċx�ݑO���������犴������o���� >>201
�ċx�݂����B�Ⴂ���ėǂ��Ȃ��B �T�C�g�ŗF�B���҂���悤�ɂȂ������Ƃ�
�ˁ@http://rprpe093w.sblo.jp/article/181823411.html
����������l���������������B
SOF53Y4MWW �������劮�S�Ƀ_�E�����₪�����A�A 2h�O�ɂ��������n�̒�d�̉e��
�������ɉ��s�\�����C�����Ă����傤���Ȃ�
��l����������҂Ƃ� ���[�[�[�[�����������[�[�[�[
 >>211
>>211
�擾���悤�Ƃ�����A��U�����͂�����̂́A
�Ȃ����擾����O�i�K�̉�ʂɖ߂��Ă��܂��Ă����ȁB
���ǁA1��1���͏I�n����ȏ�Ԃ��������A
1�����g���Ȃ������̂͂��܂�ɒɂ�����B ���N10���̑��T�Ɏ擾���Ƃ����̂��������炢�ʖڂɂȂ��Ă�
�d�v���Ǝv���y�[�W�͎��Ă邩�m�F���Ă݂��ق������� >>213
2015 �N���X�N���v�g�Ŗ�����ۑ������Ă�����̂�������ǁA
��N 10 ���͑��T�Ɍ��炸�|�c�|�c�Ɣ����Ă���B
URL �͌��J�������Ȃ��̂ŃX�N�V���ł����فB
ttp://i.imgur.com/4qDvnsI.png
ttp://i.imgur.com/l0lfBpa.png
ttp://i.imgur.com/ZKixGUA.png >>214
�X�N���v�g���Ăǂ�Ȋ����́H�Q�l�ɂ�����������������ĉ�����m(__)m >>215
403 �y�[�W���J��Ԃ��L�^����Ă���̂� Internet Archive �̖��ł͂Ȃ��B
���Ȃ݂ɃX�N���v�g�� /save/ �Ƀ��N�G�X�g�𓊂��Ă���A���_�C���N�g����������
�ŏI�I�� 200 �Ԃ� 504 �Ԃ̉������Ԃ��Ă���Εۑ��ł����Ɣ��f�A
����ȊO�Ȃ�v 10 ��܂Ŏ��s����悤�ɑg��ł���B
���O�͎���Ă��Ȃ��̂ŁA�ۑ��ł��Ȃ��������ɂǂ�����������
�Ԃ��Ă��Ă����̂��͔���Ȃ��B 10���U�X���ȁE�E�E�����̃��O�ǂ�ł�9��������10���܂ł͑啪������Ȋ��������A�������Ă݂邩 >>214
�X�N���v�g���쐬����Z�p������̂Ȃ�A�A�[�J�C�u�������
���̃y�[�W�ڃn�[�h�f�B�X�N��html�i�܂���mhtml�j�ŕۑ�
����ق����m���ł͂Ȃ��̂��H �ȉ���������B
>>219
������u�؋��ۑS�v�̖ړI�ŁA�u���O�Ȃǂ�ۑ������邱�Ƃ�����ł��傤�E�E�E�B
>>216
������ł� Windows Scripting Host �p�̃X�N���v�g�� JScript �ŏ����A
����� Windows �̃^�X�N�X�P�W���[���Ŏ��s�����Ă���B
�ȉ��AInternet Archive �֎d�|����A�N�Z�X�̓��e�ƁAHTTP �̉����R�[�h�̈����ɂ��ĊȒP�ɁB
1) �ۑ��������� URL �̑O�� https://web.archive.org/save/ ��t���āA
���� URL ������ HEAD ���N�G�X�g�𓊂�������B
2) 300 �ԑ�̉��� (���_�C���N�g) ���Ԃ��ė����ꍇ�A�����ǐՂ��� HEAD ���N�G�X�g�𓊂�������B
����́A�g�p���� API �ɂ���Ă͓��ɋL�q�����Ƃ�����ɂ���Ă����B
3) �ŏI�I�� 200 �Ԃ̉������Ԃ��Ă���A���Ԃ�ۑ��ł��Ă���B
�ۑ����ۂ� HTTP �̉����R�[�h�����łقڔ���ł���B
�R���e���g�{�f�B�͕s�v�Ȃ̂� HEAD ���\�b�h���g���Ă��邪�A
HEAD �������Ȃ����Ȃ� GET ���\�b�h�ł���薳���B
���S���K�o�C�g�̋���t�@�C����ۑ������悤�Ƃ����ꍇ�ȂǁA
�I���W���T�[�o���� Internet Archive �ւ̓]���Ɏ��Ԃ��|�����Ă��܂���
�r���Ń^�C���A�E�g�ƂȂ�A504 �Ԃ̉������Ԃ��Ă��Ă��܂��B
�X�N���v�g��ėp�Ƃ��� (URL ��ʓr�p�����[�^�Ƃ��ė^����) �̂ł���A
������ꉞ�u�ۑ��ł����v�Ƃ��Ĉ�������������B
504 �ł��ۑ����L�����Z��������ł͖����悤�ŁA
������G���[�Ƃ��Ĉ����Ď��s�����Ă��܂��������߂�
����t�@�C����Z���Ԋu�ŏd�����ĕۑ������Ă��܂������Ƃ�����B >>220
�����J�ɂ�������肪�Ƃ��������܂���m(__)m
����ۑ��̕��@�͑�̗����ł����̂ł���
����JScript�ɏڂ����Ȃ��̂ŃX�N���v�g�̋�̓I�ȏ��������킩��܂���(�m�D`)�E�K�E�B
�������͏��m���Ă���܂���
Pastebin.com�ȂǂɃX�N���v�g�̃T���v����\���Ē�����ƗL���̂ł����E�E�E
���ЂƂ���w�ׂ̈ɂ�낵�����肢�v���܂��B�io_ _)���j�j �X���Ⴂ
���������ǂ�m(__)m�@(�m�D`)�E�K�E�B�@�io_ _)���j�j�̊當��
�L�����L�������� �����Ď��Ԃ̗��ꂪ�Ⴄ�l������� ���Ԃ̗�����͐l���ꂼ�ꂾ���A�當���Ƃ���������͕̂ʂɂ�����Ȃ�
Internet Archive�Ɋւ���X�N���v�g�Ȃ疞�X�X���Ⴂ�Ƃ������Ȃ����낤��
Pastebin�w�肵�Ă��鏊����ƁA�ɗ̓X���ɖ��f������Ȃ��悤�ɍl�����Ă���݂�������
��̂��̃X���A1�N�߂��Ă�1�X����1/5���炢������ĂȂ����炢�b��Ȃ�����
�����̃X���Ⴂ�͖��Ȃ������� ���X�N���v�g�̋�̓I�ȏ��������킩��܂���(�m�D`)�E�K�E�B
���画��̂�"�Q�l"�܂łɖ₤�Ă݂�Ȃ�ă��x���ɂ�
�w�L�т��Ă��B���Ȃ�������B����>>216������
���X�������ƌ����x�[�X�ۃR�s�̐����Ō�H�����^���e�B������
���ꂽ���Ȓ��ڸڐ~�Ƃ������� ���̂����ŃX�����r��Ă��܂��Ă��݂܂���(>_<)
���ׂĖ��m�Ō�H�ŐS���n�����������̂����ł��B�B�B
�C�����Q���ꂽ���X�A�{���ɐ\����܂���ł���m(__)m >>223
�ЂƂ����ɐ��Ƃ����Ă�
���̔ƃV�����[�g�C���╶�[��ł͕��͋C���܂������Ⴄ�B �����������烁���e�i���X�ɓ�����
�����͗[�������肩��u�T�O�R�v��������������d���Ȃ����c
�Ƃ���������E��������������Ă���ۂ����̂�����̂��� �Ă�1��10���y��11���̕�
����ς�����Ă�� �ߋ��Ɏ擾����Ă�URL�����݂̕\�����e�ɍX�V����ׂɍēx�ۑ�����ɂ͂ǂ��̃{�^��������������ł����H >>232
����ȃ{�^���͂���܂���B �� ���{�́A�������s���܂��傤�B���݁A�O�c���ƎQ�c�@��
���@�ŁA�����c�����R���̂Q���Ă���܂��B
�w���@�����������[�@�x�A�ŃO�O���Ă݂Ă��������B����̔��c��
���łɉ\�ł��B���a�͏��������̂ł��B���肢�v���܂��B���� >>232
https://web.archive.org/ �́y Save Page Now �z�Z�N�V������
URL���͗��ƃ{�^�������邶���
Capture a web page as it appears now for use as a trusted citation in the future. >>235
��炪�x��܂��������肪�Ƃ��������܂���
�M���ǂ��l�� �擾��0�̃y�[�W��V���ɃZ�[�u���Ă�"2 captures"�ɂȂ�̂��ĉ��Ȃ� ���N�ۑ�����Ă��炭�͊��S�ɕۑ�����Ă��y�[�W��
���̊Ԃɂ����̃y�[�W�̉摜�̑唼�������Ă� This URL has been excluded from the Wayback Machine.
�ȃT�C�g����������������Ă���H
BIGLOBE�̗�Ƃ�����ɕK�������^�c�҂�������킯����Ȃ��悤�����A�₢���킹���畜�������肷���Ȃ����Ǝv������ Archive.is �� Facebook �̃A�[�J�C�u�����Ȃ��Ȃ��Ă���B
Archive.is �̃N���[���� Facebook ��ł͓o�^���[�U�Ƃ��ĐU�����Ă��āA
�p�u���b�N�ł͖����R���e���c�̃A�[�J�C�u������悤�ɂȂ��Ă���̂���
�����Ŏg���Ă����A�J�E���g���u���b�N���ꂽ���ۂ��B
ttp://Archive.is/TT0nA
Masha �Ƃ� Nathan �Ƃ��A�ߋ��ɃA�J�E���g�����ς�������Ƃ�������̂�
�����߂Ăł͖����̂����B
>>239
���������Ƃ������ł��ˁE�E�E�B �����[�邸���ƌq����Ȃ����lj����������H Archive.is��web.archive.org�ƈ���ă\�[�X����ƃ����N���ʂ̕�����ɒu��������
������L�^���������N�̃A�h���X���\�[�X�Œ��ׂ悤�Ƃ��Ă��킩��Ȃ�
�����N�A�h���X�����ڃT�C�g��ɂ��ׂĕ\�����Ă���Ȃ���v������
web.archive.orgt���֎~���Ă�T�C�g���L�^�ł���̂͂��肪���������r���[ �����ЂƂ���������ė���
�݂�Ȃ��E����
���R�Ȃ�ĊȒP��
�����Ɏア�ЂƂ�������������
���B�͔Ƃ���
�V�l�Ǝq���͔R�₳�ꂽ
�����ЂƂ����͂��̓y�n��
�Ƃ����ĂĎq����
�����ĊX���ł�
�����ЂƂ����̎q���͑���������
���N�i���R �֓���k�� ���{�l10���l��s�E
https://youtu.be/iBIA45CrE30
https://youtu.be/D0vgxFC04JQ
https://www.youtube.com/watch?v=sYsrzIjKJBc
https://www.youtube.com/watch?v=SiHp41uWo1I
https://www.youtube.com/watch?v=zYBCTRryFP8
https://youtu.be/-wF31xbwqPM ���[�d���d��
 �ʂ̂Ƃ���Ŏ��ɂ����̂Ŗ{�����ǂ����킩��܂���
�ʂ̂Ƃ���Ŏ��ɂ����̂Ŗ{�����ǂ����킩��܂���
webarchive��p���ď����Ă��܂��������N
�Ⴆ��http://www.chinpoppo.ne.jp/images/xxxx.jpg
���̂�����������images�ȉ����\�̃y�[�W����̃����N�������ꂽ�Ƃ��āi�T�[�o�[���ɂ͑��݂����j
���̉摜�ꗗ��Webarchive��p����ƌ��݂̃y�[�W��������Ƃ���ƕ��������{���ł��傤���H
�����\�Ȃ炻�̕��@���C�܂�Webarchive��p���Ȃ��ŏo������@����������Ă�������
�X���Ⴂ�Ȃ炱�̎���ɓK�����X���������Ă������� >>246
���{��ł�k�B
�uWayback Machine �ɕۑ�����Ă���t�@�C���̈ꗗ�v�͏o�͂ł��Ă��A
�u���T�[�o�ɂ͒u���Ă����Ă� Wayback Machine �ł͕ۑ����Ȃ������t�@�C���̈ꗗ�v�Ȃ�
�o�͂ł���킯������B ���̃A�[�J�C�u�ăf�[�^��SSD�ɑS������ւ�����
�A�N�Z�X�����������Ȃ�낤�ȁA���z���Ԃ�
�l������r�����Ȃ��b���낤���� �X�g���[�W�̑��x���厖�Ȃ낤�����
�f�[�^�x�[�X�n�̓�����������Ȃ��ƃ_���Ȃ낤�Ȃ��ċC������
���ꂱ���J�l��������b������ǂ��� �������� /save/ �ŕۑ������݂Ă����s���邱�Ƃ������Ȃ����B
����Ȃ����\�����[�h����Βʂ邯�ǁA�{���ɟT�������B
>>252
�E�ɓ����B
�������A
������Ȃ����\�����[�h����Βʂ邯��
���ꂪ�܂����\���Ԃ����X����B
�ӊO�Ƃ��̃T�C�g�̏d�v���͍��܂��Ă���̂ŁA
�������@�\���Ȃ�������{���ɍ���B �Ƃ�������{�I�Șb�����A
�����T�C�g������ꍇ�i�p�ɂɃg�b�v�y�[�W���ς��A�V���Ђ̌����Ƃ��j�A
Internet Archive�́w�P�O�����x�x�A�ԁi�������j��u���Ȃ���_���Ȃ�ˁB
�uWayback Exception�v�Ń^�C�����X�������Ă͏��X������B ���̃A�[�J�C�u�����p�����
�₽��d���Ă����˂� ������̂Ƃ�������p���Ă邯�ǁA
1��20����肾������A�T�C�g�̕����狑�ۂ����������ł˂��c
����ɂ��Ă͂��������A
�hnternetArchive�ɃA�N�Z�X���W���������Ă���̂��H �Ȃ悭�������G���[�o�Ďg���Ȃ��Ǝv���������ϕs���Ȃ̂� �Ƃ������D���̂Ƃ����Ă���̂����� �ߌォ��{���ɁuSorry�v����ŃK�`�ŕs��
�ꎞ���̃E�F�u�����������������
�s���ȉ摜�𑽗ʂɃA�[�J�C�u����悤��
�����������u�r�炵�v���o�Ă��Ă�̂��H �������˂��B
 �����͂��������B
�����͂��������B
 ������
������
�����̒~�ς̑ւ��������Ȃ��Ƃ����Ӗ��ł�Google�Ƃ�������ۂǏd�傾�� �������O�[�O�����������Ă��̋��Ђ̃��J�j�Y����
�E�F�C�o�b�N�����[�h�����ł�����A���ׂ��y��������v���O�������č\�����Ă���Ȃ����� >>266
�u���l�̒��앨������ɕۑ����Ă��̂܂���ɍČ��J����v�Ƃ���
�C���^�[�l�b�g�E�A�[�J�C�u������Ă���s�ׂɂ��đi�ׂ��N�����ꂽ���ǁA
��c���g�D�ł��邱�Ƃ��č����쌠�@�̃t�F�A���[�X�K���K�p�ł��邩�ǂ�����
���ƂȂ��Ă����͂��B
�����ʼnc���g�D�̎P���ɓ���ƁA�����炭�����������
�ۊǂ���Ă���A�[�J�C�u�̖w�ǂ���@�R�s�[�ɐ��艺����B >>267
�������ǖʂ��}���Ă����
���̑i�ׂ͌p�����Ȃ̂��ȁH
���ʎ���ł͑��̗ގ��T�C�g�ɂ��m���ɉe�����o��c �ŋߐ��T�Ԃ����ƒ��q�悩�����̂�
������1�x�߃g���C�Ő�������y�[�W��2�����炢 �����Ƃ��̊����ƍ�����
�D�����DŽ��������s��
�@�@�@��
�@���̕ӂ� �����̂�Internet Archive�������Ȃ��c�I �W�I�V�e�B�[�Y���łł����ԋM�d�ȃf�[�^���������
�����j�T�C�g��������`���Ċ��ł�̂����邪����Ȃ����葹�����傫���̂�
�A�[�J�C�u�����Ⴂ�����ǃj�t�e�B�ȂA�[�J�C�u�Ō���Ȃ��T�C�g�����S��
���ł͒N�������Ă��Ȃ����[�}�j�A�b�N�ȃf�[�^��~�ς����T�C�g�Ƃ� �ܑ̖��� ����Ȃ�
�h���C�����x���Ō����Ȃ��Ȃ��Ă���ۂ��̂���Ȃ�Ȃ낤�� https://archive.org �̏�̓��͗��� URL ��˂�����A
�ŏ��ɏo�Ă���͂��̃J�����_��ʂ��^�����B �S�y�[�W�����͂܂��H
�ł��������㌵������ �W�I�V�e�B�[�Y�폜�܂łɏo�������A�[�J�C�u���Ƃ���ƂȂ�
�A�[�J�C�u����Ă����ňӊO�Ƃ���ĂȂ������肷�遄�W�I 18���ȍ~�ɂƂ����L���b�V�����S������Ȃ��Ȃ��Ă� ���������� ���߂Ċm�F�����17���̖�ȍ~�����݂�24���Ԉȏ�O���炢�̂͑S�ď����Ă��
�T�C�g�ɂ����̂��� ��ׁ[ �����A�����Archive is�Ɣ�ׂ���A�A�[�J�C�u�T�C�g�ł͈�ԏ����ȂƂ���Ȃ̂ɁB
���Ő����O�ȍ~�̂��̂������邩�ˁI�H
�Ǘ��҂͋C�����Ă�̂��I�H >>288-289
�E�`�͂ǂ����낤�A�Ǝv���Č��Ă݂���E�E�E���� 6 ���ȍ~�̕����S���ۑ�����Ă��Ȃ��B
ttp://i.imgur.com/cEWjNjz.png
�ǂ��������̓T�[�o�s���Ƃ͕ʂ̂悤�B�Q�l�ɂȂ炸�\����Ȃ��B
>>220 �ŏЉ���菇�̂܂܉����ς��Ă��Ȃ��̂����A���炩�ɂ��������̂�
�ʐM���e��ǂ��Ă݂��Ƃ���A�����炪������ HEAD ���N�G�X�g�ɑ��� 404 ������Ԃ��Ă���B
������ GET ���N�G�X�g�ɐ�ւ��Ă݂�ƁA������� 200 �������Ԃ�B�����ۑ��ł��Ă���B
(�ȑO�͓r���Ń��_�C���N�g���������͂������E�E�E�ǂ�����������?)
�����炭�d�l���ύX����āAHEAD ���N�G�X�g�͎g���Ȃ��Ȃ����A�Ƃ��������Ǝv���B
�ȉ��]�k�B
>>214 �� 3 �̃X�N�V���Ɠ��� URL�A�����N�̃J�����_�[���ēx���Ă݂��B
ttp://i.imgur.com/71H5nOH.png
ttp://i.imgur.com/8aO7RgA.png
ttp://i.imgur.com/dUdgy82.png
>>214 �̎��_�ł͎������ɂȂ��Ă��� 10 �������A���Ȃ薄�܂��Ă���B ���j���I���ɂȂ��Ă����ɉ��P����
��������1���ȏ�O�̕��͂��ׂď��� �O�v���o�����悤�ɕ����������Ƃ����Ȃ�
����͂ǂ��Ȃ낤 ���������͂肫����geocities�̃A�[�J�C�u�ۑ����Ă��̂ɏ����Ă邶���...�ň�
��\������Ȃ��ăA�[�J�C�u���Ə��ł������Ă��ƁH���܂�ڂ����Ȃ�����킩��� �Ηj���I���ɂȂ��Ă������ɏ��Œ�
�ȂA�i�E���X�ł��~������ ������CNN�̃A�[�J�C�u���m�F���Ă݂��
https://web.archive.org/web/*/http://us.cnn.com/
����ς�17���̒����炢���炳���ς�L���b�V���������Ȃ��Ă�
�ꉞ�S���E�I�Ȃ̂�������A�O���̐l�͋C�Â��Ă���̂��낤��? �ǂ���畜�������͗l �ߋ��̕����܂߂ă����N���\�������悤�ɂȂ���
�ǂ����ɃA�i�E���X�Ƃ��オ���Ă��邾�낤���H �������̂��@�ǂ������ǂ����� �W�I�S���̍����ėݐσA�N�Z�X���ŃL���ԓ������悤�����Ă�l���\�����Ȃ�
�߂�ǂ��Ė���X���[���Ă����œ��ݓ�����K�҂Ƃ��ĎN����Ă��肵��
���������Ċm�F���Ă݂���A�[�J�C�u�擾����Ă�(Ɂ�`)���� �[�W����������ƃG���[�ɂȂ�H �S�y�[�W�����͂܂��������Ȃ���ł����H >>304
�挎�A�����ۑ��Ɏg���Ă���Web�u���E�U����
https://web.archive.org/save/�c
�ł��Ȃ��Ȃ����̂́A�u���E�U��Cookie���폜������ł���悤�ɂȂ����B Wayback Machine does not have this page archived.
�����������y�[�W���悤�Ȃ� �܂������Ă�y�[�W������I�H
����i11��12���j�p�ɂɁu�ēǂݍ��݁v�𑣂���ʂ����x���o�Ă������c�B �ŋ߁Agoogle chrome�ŃA�[�J�C�u�����悤�Ƃ����
�uThe Wayback Machine is an initiative of the Internet Archive, a 501(c)(3) non-profit, building a digital library of Internet sites and other cultural artifacts in digital form.
Other projects include Open Library & archive-it.org.
Your use of the Wayback Machine is subject to the Internet Archive's Terms of Use.�v
���Ă̂��o�Ă��āA��ɐi�߂Ȃ�
�ʂ̃u���E�U���ƕ��ʂɌ�����̂� ����Atwiki������Ƃ낤�Ƃ���ƃX�p����������Ăł��Ȃ� >>316
�X�p���������ꂽ���\���Ƃ�
http://web.archive.org/web/20181205074744/http://www26.atwiki.jp:80/gcmatome/pages/1017.html >>317
�����낤�˂��B
http://web.archive.org/web/20181211002734/www26.atwiki.jp/gcmatome/pages/1017.html
�O�̂��߁A���̎��Ɏg���� User-Agent �������\���Ă����B
Mozilla/6.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0 Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0
����ł���Ă݂���e���ꂽw
http://web.archive.org/web/20181211005436/www26.atwiki.jp/gcmatome/pages/1017.html atwiki��Firefox 52�Ƀg���E�}�ł�����̂� �ӂނӂ�
http://web.archive.org/web/20181211102115/www26.atwiki.jp/gcmatome/pages/1017.html
Mozilla/6.0 (Macintosh; Intel Mac OS X 10.13; rv:60.0) Gecko/20100101 Firefox/60.0
>>320
/save/ ��@�������Ȃ��ǁA�����_�������Ŕ��肷��Ȃ�
�� IP �� archive.org �̎擾�p�T�[�o�Q�̒��̉��ꂩ����g����B
�č��� IP �ł��邱�ƁA�܂����O�� www �������Ă��邱�Ƃ͉��_�ΏۂɂȂ�\������B
���� IP ����̌J��Ԃ��A�N�Z�X�����_�ΏۂɂȂ�\������B
�� User-Agent ���܂߁A���N�G�X�g�w�b�_�̓N���C�A���g�̂��̂����̂܂ܓ]�������B
�Â��u���E�U���g���Ă���Ɖ��_�ΏۂɂȂ�\������B
�� ����� Via: HTTP/1.0 web.archive.org (Wayback Save Page) ���lj������B
����͊ԈႢ�Ȃ����_�ΏہB
���̕ӂ������I�ɔ��f����Ēe����Ă���̂��낤�B
�ۑ��ɐ������邱�Ƃ�����̂ŁAWayback Machine ������ƌ����Ĉꗥ�ɔ��f���Ă���̂ł͖����Ǝv���B ���������{���������̂��ăX�p�����Ă����̂��낤��
����{�ƊW�Ȃ��� ��T���炢����A��̂ق��Ɋ�t����W�̃o�i�[���o��悤�ɂȂ����ȁB
������IE���ƁA�E��́u�~�v���N���b�N���Ă��A�ǂ������킯���o�i�[�������Ȃ��B
���̕�W�͖{�C���ȁB �����������Ȃ������̂��߂ɂ���̋�����B���Ƃ��Ă��� �t�B���^�ɂԂ�����ŏI��
���������� �E�B�L�̃R�[�q�[1�t�݂����ȟ������W���[�N����Ȃ��Ƌ����W�܂�� �A�[�J�C�u���͈��H�֎~�ł��̂Łc http://web.archive.org/web/20181223223511/https://www26.atwiki.jp/gcmatome/pages/2928.html
http://web.archive.org/web/20181223223509/https://www26.atwiki.jp/gcmatome/pages/686.html
�܂��X�p����������Ă� 221 ���O�F�����������������ς��B[] ���e���F2018/12/22(�y) 16:36:12.78
���������C�O�T�[�r�X�������B
�܂����傱���Ƃ��������Ă��Ȃ����B
Archive.st
https://archive.st
Time Travel
�i�u���E�U����u���̃T�C�g�͂����������Ȃ��v
�Ƃ����x�����o�����A�����邨����s���Ă݂��
���ɂ܂������Ƃ͂Ȃ������j
http://timetravel.mementoweb.org 12��30���Ɏ�������������Ă�I�H �������̃T�|�[�g�͂���Ȃ������� Wayback Everywhere���ăA�h�I���g���Ă邯�Ǒ��ɕ֗��Ȃ̂Ȃ����� �ȑO�̂����Ɠ������A18�N12��29���[�邩�猻�݂Ɏ���܂Ŏ擾�����A�[�J�C�u�̏������N���Ă���
���ӂ��ꂽ�� ���O�オ��Ȃ�����Webrecorder�Ƃ�InterPlanetary Wayback�Ƃ��m���Ă�H
�������`���� >>343
�N���E�h�ۑ��łȂ����[�J���ۑ��H Webrecorder�́AWeb�y�[�W����warc�t�@�C��������Web�A�v���P�[�V����
��������warc�̓R���N�V�����ɕۑ�����A���̂܂ܕ\��������A
����Ȃ���J�R���N�V�����ɂ��邱�Ƃ�URL��\���Č��J�ł���
+ New Session�ׂ̗́u�c�v����uDownload Collection�v�ŃR���N�V��������warc�t�@�C�����_�E�����[�h�ł���
warc�t�@�C���͋���̋K�i�����ꂽ�`���ŁAHTTP�̃X�e�[�^�X�R�[�h����摜�⓮��܂ł��̃y�[�W��\������̂ɕK�v�ȏ����i�[���Ă���
�Ƃ肠����warc�t�@�C����������Όォ��ǂ��ɂł��Ȃ邩��c�������T�C�g�͍�����capture���Ă���
warc�t�@�C����\������ɂ́A�uWebrecorder-player�v�Ƃ����A�v�����g����
�܂�Webrecorder�̃R���N�V������warc�t�@�C�����A�b�v���[�h���Ēlj����邱�Ƃ��\�Ȃ̂ŁA��������ĕ\������J�����Ă�����
InterPlanetary Wayback�͂���������ƍ��x�Șb�ŁAIPFS�ƘA�g���邽�߂̂��̂Ȃ��ǂ���͌�ł��� 19/01/13�̕�����擾�����A�[�J�C�u���m�F�s�\�ɂȂ��Ă��� �ŋߖ����ꒃ�d���������
���ԑтɂ���邯�� >>214 �Ɠ��� URL �� 2018 �N�J�����_�[��\���Ă݂܂��B
10 ���ɘA�����Č����Ă���̂́AInternet Archive �̎d�l�ύX�ɑ�
������̑Ή����x�ꂽ (>>291) ���Ƃ������ł��B
ttp://i.imgur.com/aYSmomB.png
ttp://i.imgur.com/35RP1No.png
ttp://i.imgur.com/fRsG33D.png
������� URL �����J���������������B
���̐l�̑����ɂ��Čl�I�ɋ����������Ȃ��Ă��Ă��邱�ƁA
�܂��ʓr�擾�����Ă���ʃG���g���̃A�[�J�C�u�ŏ\���Ȃ��Ƃ���A������~�߂邩������܂���B
ttp://web.archive.org/web/*/blog.goo.ne.jp/chimaki-1014
��N 3 ���ȍ~�A��� 2 ��̎擾�ɑ��v 4 ��̃X�i�b�v�V���b�g���L�^����Ă���̂́A
HTTP ���� HTTPS �ւ̃��_�C���N�g�� HTTPS �Ŏ擾�����u���O�R���e���c��
���ꂼ��v�コ��Ă��邽�߂��Ǝv���܂��B ��T�ӂ肩��
�u502 Bad Gateway�v��
�\������邱�Ƃ������Ȃ��� NHK�j���[�X�����̃X�N�V����
�����ƕۑ�����Ȃ��|���R�c�т�ɂ�
�����ꂽ �~�|���R�c�т�
�Z�|���R�c�Ԃ�
���[�{���ɕ������� �߁X��NHK NE��S W��B�̃g�b�v�y�[�W��
InternetArchive�o�R�ŋ����������l��
��x�m���߂Ăق���
�Ȃ�����ʂ��u�{�����݁v�̏�ԂɂȂ��Ă��邩��
�E�F�u����ł�META�^�O�������������đʖ�
ArchiveToday���ςȉ摜�i���n�ɍ������̒��ӏ����H�̂݁j
�����ʂƂ��ĕԂ��Ă���̂őʖ�
�܂������݂̍j��InternetArchive�ő厸�s����Ƃ͎v��Ȃ�
�ǂ����Ă�N��K NEWS ��EB�̃g�b�v�y�[�W���c���������
��ʂɎB�e���邵�����@�͖����悤�� html�ɖ{���������ĂȂ��āAajax�I�ɕʂ̃t�@�C������ǂݍ��ނ�͂�����ȁB
wix���������R�ŕۑ�����ĂȂ��B
�{���t�@�C���̃L���b�V�����c���Ă��Ƃ��Ă��A�����ǂݍ��݂ɍs���Ă���Ȃ��̂�� �ŁA�����webrecorder�ł��ۑ��ł��Ȃ��̂����H >>361
�g������������ɂ�����
�L�^�i����j�͎��Ă�
���̎��o���������܂���������h��
����Ɏ��o���Ă��̓����̏�Ԃ�
�Č��ł��Ȃ���ΈӖ����Ȃ��� >>360-361
���ŁuNHK NE��S W��B�v�̃g�b�v�y�[�W�̘b���o�������Ƃ�����
��T���j�i1��27���j�ɂ������^�u�����I�v�O���[�v�̊����x�~���\���炾����
���̎��uN��K NEWS ��EB�v�̃g�b�v�y�[�W�ł�
�ŏ㕔�́u����v�E���̂������́uJUST IN�v�E�{�L����
������3�̌��o���Łu�������x�~�v�̕��������ԂƂ���
���Ƃ��H�ȏ�ԂɂȂ��Ă���
������InternetArchive�Ńy�[�W�̋�������
������I��fanview�o�R�ŃX�N���[���V���b�g��������g�͂��h�������̂���
���̉摜�����炩�̌`�ŕۑ����邱�Ƃ���������Y��Ă��܂��Ă���
�����ė����ɂȂ���InternetArchive���m�F������c
���̂悤�ȏɂȂ��Ă���
https://i.imgur.com/IBOpfrs.jpg
���Ȃ킿������1��28���ɂȂ�����
�O��27���Ɏ�������̂��\������Ȃ��Ƃ������
�ꉞ�͗ގ��̉摜���������Ă݂�������Ȃ̂����o�Ȃ�����
https://pbs.twimg.com/media/Dx56MVSV4AEsqgB.jpg ����Ȃ킯�Ŏ�����1��27���ȑO�Ɏ��ꂽ���̂��\�����Ă݂���
���ǂǂ̓��ł��\�������̂́g��Ɠ����h�̉�ʂ�����
�܂�͓�d�O�d�Œɍ��̃~�X����炩�������ƂɂȂ�
�{���ɍ��T�͂���������������c
���̂܂܂ł͉���ᛂɏ��̂�
���܂����ߖłڂ��ɒu���Ă���
�i1��31���j
https://i.imgur.com/E96yEeA.jpg
https://i.imgur.com/bCjdPXO.jpg
https://i.imgur.com/EAUNldo.jpg
�i��2��1���j
https://i.imgur.com/hpvfmr9.jpg ���X�o�Ă��邱��A��̓I�ɉ�������Ă���Ƃ������A
503 �����̃G���[�y�[�W�����̂悤�ɏ�����Ă��邾���Ƃ����v���Ȃ����ǂȂ��B
 >>366
>>366
�����ʂ胁���e�i���X���Ǝv�킹�邭�炢��
�����ԕ\�������ꍇ������c
���̉�ʂ��o����ōēǂݍ��݂�������
�����Ƀg�b�v��ʂɖ߂�ꍇ������ �����N�悪�Ȃɂ��Ȃ��^������ȃy�[�W�����������Ă������߂��ق��������ł����H ���2��19���Ɏ�������̂��ď����Ă�I�H ��������2/19�ɂƂ�����������Ă܂���
�O������Ȃ���1�T�Ԃ��炢���������ǖ߂����Ƃ����������̂ŗl�q���ł����� �A�[�J�C�u�̃T�C�g������������������
���T�C�g�͍���uSorry,we are busy�v�Ȃ�Ă���
���߂Č����\�����o��
�E�F�u����͍����̌ߑO���d������
Archive is�͒f���I�ɃL����
��̑S�̂ǂ��Ȃ��Ă�̂� yahoo!�u���O�܂ŃT�[�r�X�I����
�ǂ�ǂ�V�܂������Ă����Ȃ� �l�b�g�̃f�[�^�͙R�� ����3���Ԃ��炢�͑S���A�[�J�C�u�����Ă�� Yahoo!�u���O������̂�Yahoo!�n�͂Ȃ���Internet Archive�ŕۑ����Ă��S���g�b�v�y�[�W�ɓ]�����ꂿ�Ⴄ����ۑ��ł��Ȃ���ȁc �������d���Ȃ��Ă邼
20�����炢�O�ɂ̓A�N�Z�X�s�\�ɂȂ��Ă����� 2���O���炢����archive.org�̍Đ�����ʂ��������Ȃ��Ă��܂��Đh��
�S��ʂ��ƍ�Ƃ��o���Ȃ����Ȃ� >>379
���̃g�b�v�y�[�W�]���{���ǂ��ɂ��Ȃ��̂��ȁB >>383
���Ȃ낤�Ȃ���
���O��Heritrix�Ƃǂ�Ȋ����ɂȂ�낤
Yahoo�u���O�A�[�J�C�u�����̖{�X��
http://mevius.5ch.net/test/read.cgi/blog/1554380939/ �����Internet Archive�������|����Ȃ��X���^�C���� >>388
�T���N�X�B
adblock�̏ڍאݒ�̃}�C�t�B���^�[���X�g�Ɂu*/yjsecure.js�v��o�^����adblock�L���œ]������Ȃ��Ȃ����B http://mevius.5ch.net/test/read.cgi/internet/1554553882/78-79
/save/ ��m���Ă� /web/2/ ��m��Ȃ��Ƃ́B
���ƕۑ��̍ۂ� http:// �� https:// �����ɊO���̂��l�����B
HTTP ���� HTTPS �փ��_�C���N�g����T�C�g���ƁA���̃��_�C���N�g��
�ۑ��Ɍv�コ��Ă��܂��B >>392
���̃u�b�N�}�[�N���b�g��������l�Ԃł͂Ȃ����ǁAWayback Machine���S�҂̎�����/web/2/�����Ȃ̂������ĉ�����
���ƕۑ��̌v�オ������Ɖ�����肪����́H /save/�m���Ă�̂�geocities�̃X���̕��ő��p����Ă����炶��Ȃ����� /save/��/*/�͂�肩���L�����Ǝv�� >>395
����
/web/2/�͏��߂ĕ��������ǂ��̓�͌����قǓ��ʂȒm���ł͂Ȃ��Ǝv���� /0/��/1/�͒m���Ă邯��/2/�͏��߂Č����B ���N��2����
�S�b�\��������I�H >>398
���ۂ��ł��ˁB
https://i.imgur.com/gZyzB5u.png
�����A�A�[�J�C�r���O�ƃC���f�N�V���O�͂��ꂼ��Ɨ����Ă���݂����Ȃ̂ŁA
��҂����Ńf�[�^�̌������������Ă���Ƃ����\��������Ǝv���܂��B �S�y�[�W���S�������͂܂��H
�Ȃ��ł�����̂��H �̂���Ă����ǂ����������������炫��������� Scheduled Maintenance
��قǂ��炱�̕\��
�����Ȃ肻�����H >>406
�@�B�|��g�����̂��ǂ����m��A���͂̈Ӗ���ǂݎ��Ė���������B >>406
�č����{�̃T�C�g�ƕČR�̃T�C�g������ď����Ă����
�����܂ŋ������ď����Ă����ł͂Ȃ��Ƃ͌�������������ƐT�d�ɓǂ���
�������Arobots.txt���ז��Ȃ�S�T�C�g�Ŗ���������Ηǂ��̂ɂ�
�ǂ����@�I�S���͂͂Ȃ��� �ߋ������X�g����������i�H�j�}�C�i�[�`�F���W���Ă��錏 �����I�ɍŐV���O�̔N�ɔ�Ȃ��C������B2019�N�B �����łȂ����̘^�ꂽ�狳���Ă������� �����O����uHTTP ERROR 400�v�Əo�Ďg���Ȃ� �蓮��1�y�[�W1�J�e�S���[�Âۑ�����̖ʓ|��������ł����ǁA
��������Ŏw��̃T�C�g��u���O��https://web.archive.org/�ɕۑ��o������@�Ȃ�Ė����ł���ˁH
���������O��ŕۑ����Ĕ�ꂽ�c�ۑ����Ă��ۑ����Ă��L�����Ȃ��c >>413
�����������O��ŕۑ����Ĕ�ꂽ�c
���ۑ����Ă��ۑ����Ă��L�����Ȃ��c
�A�[�J�C�u�T�C�g�S�ʂ̃��[�U�[��
�ő�̔Y�݂ł������
��x���n�߂��狭���ϔO���o�Ă���
�������˂Ȃ�Ȃ��Ȃ�
�������N��������Ă���킯����Ȃ�����������
�������x��ł����̐l���⊮���Ă����ۏ͂Ȃ����� ��낤�Ǝv���v���O�����g��ŏo�����A�l�b�g�T���ΐF�X������
������Web�A�[�J�C�u�����X���ɓ��e���ꂽ���]��
0175 py ��o3kzHb/in8w0 2019/05/14 19:06:58
https://u1.getuploader.com/irvn/download/1657
web2IAWBM.dms ver0.000.007�@WayBackMachine�ɕۑ��@(web.archive.org) 2019/05/14
web2IAWBM.dms��Irvine��Dorothy2���g����Internet Archive WayBack Machine�Ɏ����o�^(�ۑ�)���邽�߂̃X�N���v�g�ł��B
�����őS�Ẵ����N�����ǂ��ĕۑ����Ă����͂��ł��B
web2IAWBM.dms�͑f�l����������Ȃ̂Ŏ���Ȃ��_�����X����܂����A
�ꉞ�g���鐅���ɂȂ����Ǝv����̂Ō��J���܂��B
�����̃E�B���X�X�L�����͂��܂������A�O�̂��߂�����x�X�L��������邱�Ƃ������߂��܂��B
������Dorothy2(�̈ꕔ)�͕ʂ̕�����������ł��B
�� Irvine����N���O�ɕK�� jword�t�H���_���폜���Ă��������B��
���쎎�����Fwindows10pro�@Irvine1.3.1 IA�w�r�[���[�U�[�������ł��낤�����̏Z�l�Ȃ�A
��������i���ς݂��X�N���v�g���삵�Ă�l�����邾�낤�Ǝv���Ă����A�ĊO����������ł��Ȃ��̂��� >>414-416
���肪�Ƃ��������܂��B
�E�C�o���ĕ����Ă悩�����c�撣�� archive.org�Ƀt�@�C���A�b�v���[�h���Ă�l���Ă���? �d�Ă����U���T�C�g�������Ă��܂����E�E
�A�[�J�C�u����Ă����̂ɉ��́H���������ł܂邲��
�����Ă��܂����H archive.org�Ƀt�@�C���A�b�v���[�h���Ă�l���Ă���? �x�[�^�ł̐V����Save Page Now���g���Ă݂����������烆�[�U�[�o�^���Ă݂�
�v���̂ق���������o�^�ł��ď��������� ���A�T�[�o�[�G���[�o�Ă�
503 Service Unavailable
No server is available to handle this request. �X�}�z����Save Page Now���g����Twitter���A�[�J�C�u���悤�Ƃ���ƕK���G���[��f���Ă���
PC�ł͂���Ȃ��ƂɂȂ����o�����Ȃ����lj������������낤
���ƁA����̓X�}�z��PC���W�Ȃ����A
Internet Archive�̏ꍇ�c�C�[�g��json�Ɖ��߂�
��Ă��܂��ꍇ������
Archive.today��megalodon�͕��ʂ�HTML�R���e���c�Ɖ��߂��Ă������AIA���Ɖ���json�ɂȂ��Ă��܂��낤 �G���[����܂����i���̕\���͏��߂Ă��j
500 Internal Server Error
nginx/1.10.3 (Ubuntu) �ɂ��Ă������܂Œ����Ԃ́u�����e�i���X�v�͂��ȗ��� �ŋ�400error�݂����ȕ\�������������̂͑O���������̂��E�E�E�H ���������e�i���X�I��������ȁH �~�b�L�[�}�E�X�̕����`���ă~�b�L�[�}�C�X�H >>424
> �x�[�^�ł̐V����Save Page Now
���� ���[�A���܂�B���Ⴂ���Ă����B �Ȃۑ��ς݃y�[�W��IA�J���ċL���Ƃ���2�y�[�W�ڂ���3�y�[�W�ڂɈړ����悤�Ƃ����2�y�[�W�ڂɈړ�����(�ړ��ł��ĂȂ�)�B
�Ȃ�����Ƃ��������B ���̃T�C�g
�X�N���v�g�Ńy�[�W��ւ��Ă��łˁ[��? imgur��������SavePageNow�o���Ȃ��Ȃ����B Twitter���A�[�J�C�u����ƕK���\���������l�������
������ĉ��Ȃ낤�� �ŋߕۑ����ĂȂ����ǃc�C�b�^�[����UI����̊O����ɂȂ��Ă��� >>451
���ꑽ��IA���o�R���Ă�T�[�o�[�̍��̌���ŕ\������Ă�Ǝv�� ����archive.vn���ƕۑ��ł��Ȃ��z���ۑ��o���邩��֗� ���ꂪ�����̂�Internet Archive Wayback Machine�̂��Ƃ���B https://web.archive.org/web/20190727084527/https://toyokeizai.net/articles/-/293979?page=2
���m�o�ς̋L���Ŗ��ۑ��L����1�y�[�W�ڂ�ۑ����āA1�y�[�W�ڂ̃A�[�J�C�u����2�y�[�W�ڂ̃����N���J����
�ۑ�����Ă��Ȃ����瓖�R�ۑ��p�̃����N���\������邯�ǁA2�y�[�W�ڂ̃A�[�J�C�u����3�y�[�W�ڂ̃����N��
�N���b�N�����2�y�[�W�ڂ̃A�[�J�C�u���ēx�\�������B
�ȑO��������A���ŕۑ��ł����̂ɂł��Ȃ��Ȃ��Ē���SavePageNow�ɑł����ނ����Ȃ��Ȃ������ۂ��B https://toyokeizai.net/articles/-/293789
https://toyokeizai.net/articles/-/294305
���� 2 �� Internet Archive �̓��͗��ɓ˂�����ł���Ă݂����ǁA
�ǂ�����擪����Ō�̃y�[�W�܂ŁA"This page is available on the web!" ���o�ĕۑ��ł������ǂȂ��B
https://web.archive.org/web/20190727093955/https://toyokeizai.net/articles/-/293789
https://web.archive.org/web/20190727094921/https://toyokeizai.net/articles/-/294305
�ǂ���������ł͌��ۂ��Č��ł��Ȃ��B >>462
��������Ă݂����ǁA�܂������Ǐ�ɂȂ����Bpage=2���ĕ\���B�ʖڂ��
Firefox�A�v�f���u���Ă��̂��������Ǝv���āA���̃^�u�����肵�Ă��炭�������Ƃ����
�A�v�f�O�ɂ�����킵����A���̂�page=3���ۑ��ł����B����H�ł����B�ǂ��Ȃ��Ă�H archive.today�܂������q����Ȃ����Ǔ����̐l���܂��H >>427
Heritrix�̎d�l�������Ȃ̂��ȁH
���O��Heritrix�����������ƂȂ�����f���͏o���Ȃ����� Chrome�ɂ�����ł����B�u���E�U�̖�肩�H �Ђ���Ƃ�����������s��ꂽ���H
�ȑO�Ȃ�A�i���܂������ł��Ȃ����j�Ⴆ�j���[�X�T�C�g�Ȃ�A
�{�L���ȊO�̋ߗL���Ȃ�Q�ƋL����URL���N���b�N����ƁA
�擾�O�̂��̂ɂ��ẮA�V�K�̎擾�𑣂���ʂ��o�Ă����B
���ꂪ��ʂɋL������肽���ꍇ�ɂ́A���ɏ������Ă����̂����c
�Ƃ��낪�������́A��L�Ɠ���������s���ƁA����������ʂ��o�Ȃ��Ȃ����B
����ɏo�Ă����̂����ꁫ
https://i.imgur.com/2mOTHmt.jpg
���̂��߁A������������uSave Page Now�v�̕�����
URL��ł�����ŁA�Ώ����Ă����Ԃ����c�B
����ς�ǂ��ɂ��ʓ|�������B
�uThis page is not available on the web�v�ubecause of server error�v
�Ƃ������Ƃ́A�ꕔ�̃T�[�o�[�������Ă��Ȃ��̂������ŁA
���ꂳ������A��ɐG�ꂽ�@�\����������̂��H
���̂܂܂ł͎d���ʂ������Ȃ���������A���Ƃ����Ăق������B ���݂�>>470�Ƃ̓��b�Z�[�W���قȂ�B
�uThe Wayback Machine has not archived that URL.�v
�uThis page is not available on the web�v
�ubecause request is invalid�v >>470
����A�N����T�C�g�ł͈ȑO���甭�����Ă��邯�ǂȂ��B
> ���̂��߁A������������uSave Page Now�v�̕�����
> URL��ł�����ŁA�Ώ����Ă����Ԃ����c�B
�A�h���X�o�[�� /web/���t��������/ �� /save/ �ɕς��邾���ł͑ʖڂȂ̂�?
�ʓ|�Ȃ��Ƃɂ͕ς��͖������B
���������u���E�U�Ƀu�b�N�}�[�N�c�[���o�[���o���Ă������
�����ۑ�������u�b�N�}�[�N���b�g��o�^���Ă��܂��B
ttps://pastebin.com/NA4c5krN >>473
������A�N����T�C�g�ł͈ȑO���甭�����Ă��邯�ǂȂ��B
�����X�|�[�c�̌����T�C�g�̂����u�o�b�N�i���o�[�i�{���̎��ʁj�v�Ɋւ��ẮA
�����������ۂ��m�F���Ă����� �A�{���ɂ���Ƃ�����̂��炢�ŁA
�����Ȃ�ΏۂƂȂ�͈͂��L�����Ă��܂�����ہB
���A�h���X�o�[�� /web/���t��������/ �� /save/ �ɕς��邾���ł͑ʖڂȂ̂�?
���ʓ|�Ȃ��Ƃɂ͕ς��͖������B
����������Ă݂����ǁA������Ƃ��y�ɂȂ����B����A���炭�����Ă݂܂��B
�{���ɂ��肪�Ƃ��������܂��B Twitter���ŋ߂��̌��ۂɂȂ��Ă��܂�����
�A�[�J�C�u��ւ̕��ב�Ƃ��Ȃ� >>470�Ɋւ��Ă��A���ɖ߂����݂������i�V�K�擾�𑣂���ʂ������j�B
�Ƃ͂���>>473�ʼn��i�̃u�b�N�}�[�N���b�g�́A�g���Ă݂���
���\�֗��Ȃ̂ŁA���炭���p�Ƃ������ƂŁB
�Ƃ����chrome�͂Ƃ������Ƃ��āA�������h�d�ł͂��Ȃ�g���h���Ȃ����B
�ۑ��̌�A�ȑO�Ȃ獶����̃��S�}�[�N���N���b�N����ƃg�b�v�y�[�W�ɖ߂��Ă����̂��A
�Ȃ����Ⴄ�y�[�W�ɔ�����悤�ɂȂ����B
����Ɏl�p�`������������ł���̂ƁA�����ȉp�����\�����ꂽ�y�[�W�����A
���̎l�p�`�͊֘A�T�C�g�ւ̃����N�炵���A���[�̎l�p�`���N���b�N����ƁA
����Ƃ������T�C�g�̃g�b�v�y�[�W�ɖ߂邱�Ƃ��ł����B
����Ɍ����A�uBROWSE�@HISTORY�v�i�ߋ��̕ۑ����X�g���\��������ʍs���j��
�h�d�ł͎g���Ȃ��Ȃ��Ă��܂��Ă�B IE���Ǝg���Â炢�ˁB�ߋ��̃L���v�`���ꗗ�������Ȃ��Ȃ������B
Microsoft Edge�Ȃ���Ȃ������邩�獡���Edge�Ō��悤���� �������֎~�T�C�g�̉摜���L���v�`���ł��Ȃ����ۂ� >>480
���X���������d�l�B
/save/ ���g���ĕۑ��������Ƃ��A�u���E�U���� Internet Archive �֑���ꂽ
���N�G�X�g�w�b�_�� (���Ɋ��ϐ��ƌĂ�Ă�����) ��
�ꕔ�̉��ρE�lj��݂̂Ō��T�[�o�֑�����̂ŁA
������U�����邱�Ƃɂ���Ē���������͉\�B
���t�@���[�̂݃`�F�b�N���Ă���T�C�g�ɂ��ẮA��������Ƃ�����B
�����A����� URL �ɂ��ĕ����̓��t�̃A�[�J�C�u�����݂��Ă���Ƃ��ɁA
������ /save/ �������̂����摜����A���l�� /save/ �������͉̂摜�����A
�Ƃ������ƂɂȂ�̂ł��܂���p���͖����Ǝv���B >>478-479
�����߂������Ė�����IE�g���Ă�́H
MS�����͂�T�|�[�g�������悤�Ƃ��Ă�̂� Internet Archive���ǂ����͕�����Ȃ����ǁA�ŋ߂̃T�C�g�͖ʓ|��IE�Ή���������Ă�Ƃ�����������A
�������ƌ���Ȃ�����Edge�Ƃ�Chrome�Ƃ�Firefox�Ƃ��ɏ�芷���������ǂ�
�Ƃ�����IA�������Ă���2,3�N��IE���Ⴟ���ƌ���Ȃ��Ȃ�Ǝv���� IE���Ƃ܂������g�����ɂȂ�Ȃ��Ȃ��Ă����̂��B
���������Č������Ă�������w�E���ĂȂ��̂Œ��ׂ���A5�����̂��̃X���ł悤�₭��������
�N���[���g�����Ă��B��������web.archive.org/web/*/�@�̕ۑ��ꗗ�������Əo��悤�ɂȂ���
�����Ȃ�����webarchive�ɖ��ʂɍC�Ƃ������������������E�E�E�E >>482
�}���قȂǂ̌����{�݂̃p�\�R�����ƁA
���܂��Ƀu���E�U�Ƃ�����IE�����p�ӂ���ĂȂ��B IE�͋Ɩ����ߑł��V�X�e���p�������ĉ���ɉ��ς��ł��Ȃ����������Ď̂Ă�킯�ɂ������Ȃ�������ߏ�ԂȂ낤�� >>481
���肪�Ƃ��BReferer Control��Inactive�ɂ�����摜���L���v�`���ł����B 429 Too Many Requests
You have sent too many requests in a given amount of time.
�c�����X�����������ĂȂ��� >>488
���ꉴ��������Ȃ������̂�
�Ă�����A�[�J�C�u���߂����������� ��������
�����Ɍ��ʂ��\�����ꂸ��
��ʂ��^�����ɂȂ錻�ۂ��N���Ă���
���̂Ƃ��돭�����Ԃ�u���Ε��ʂ̏�ԂɂȂ�̂�
�g���͂��邪�������� >>490
�������B
>>491
�g�b�v�ɂ����A�N�Z�X�ł��Ȃ��B
�u���E�U�ɂ���Ă̓g�b�v����A�N�Z�X�ł����B >>488
�X�N�V����JPEG�ŏグ�Ă鎞�_�Œ��x���m��Ă� �悤�₭�g�b�v�ȊO�ɂ��A�N�Z�X�ł���悤�ɂȂ����B >>479
URL�����������Ǝ��܂܂œ���T�C�g�̔N��ʃA�[�J�C�u���T��ɂ���
�����G���W�����̂̓T�N�T�N�ňꗗ�o�Ă����̂��A���N���O��UI�����j������Ă���A�����ƌ��d�ŕs�ɂ܂�Ȃ��������ǁc >>484
Chrome���Â��[�����ƍŏIver�ł��ʖڂ��ˁB
Edge���g���邮�炢�V�����@��łȂ��Ɓc 30���قǑO����T�C�g�ɂȂ���Ȃ� �������͕��ʂɖ��Ȃ��q�����Ă�
����Save Page Now�ł������ۑ����Ă���
�x�[�^��SPN��Save outlinks���ăI�v�V���������߂Ďg���Ă݂����߂��Ⴍ����֗����� �Ȃɂ���
�����Ⴀ���đS���ۑ����Ă����� >>501
> �x�[�^��SPN��Save outlinks���ăI�v�V����
�m��Ȃ� �x�[�^��SPN��Save outlinks�@
�������Ă݂����A���t�[�j���[�X�͂���ς苛��Ƃ�Ȃ������B >>504
�A�[�J�C�u�����Ė����̂ƁA��̃y�[�W�J�ڃX�N���v�g���������Ă邾���Ȃ̂�
�ǂ����Ȃ� Save outlinks���Ă̂́ASPN�ɓ�����URL�̃y�[�W�ɓ\���Ă郊���N����S�ēǂݍ���ŕۑ����Ă����I�v�V����
�������ɖ������Ƀ����N��H���ł͂Ȃ���1�i�K�����H���Ă���Ȃ����ǁA����ł����Ȃ��Ԃ��Ȃ���
�J�ڃX�N���v�g�̔����L�����Z�����Ă����悤�ȋ@�\�͂����炭�Ȃ��Ǝv�� >>506
>>504
���܂ŃC���^�[�l�b�g�A�[�J�C�u�Ń��t�[�֘A�̃y�[�W�̋����
����Ă����t�[�g�b�v�ɔ���ꂽ�����\������Ȃ������̂�
�����ł͋���͎��Ȃ����̂Ǝv���Ă������A���͎��Ă����ƒm
�b�܂ɏ����Ă������B
http://superbabooooo.blog.jp/archives/27043737.html �܂��N�\�d�ɂȂ��Ă�
�����Ǝ��ɂ����y�[�W������̂� �m��/web/1/���ŌÁA/web/2���ŐV�̃A�[�J�C�u�Ȃ��
����ȊO�ɉB���R�}���h�Ƃ������B���G���h�|�C���g�I��URL�͂���́H >>512
�����������̂�example.com�Ŏ����Ă݂����ŌÂ̂��̂��\�����ꂽ
/1/�Ɠ����Ȃ̂ł� >>514
/web/�N/ �Ƃ� /web/�N��/ �Ƃ��́A���݂� UI �� Beta ����{�����ƂȂ������ɔp�~���ꂽ�B
���ł��G���[�Ƃ͂Ȃ�Ȃ����̂́A�����̈Ӗ�����ʂ�ɂ͓����Ȃ��Ȃ��Ă���B
>>511
�����̌��ɕt����A�R�}���h�݂����Ȃ��̂͑O�X���łقڋ������Ă��邩��A
�����镶�����������ȍ~�̃��X�Ɉ�ʂ�ڂ�ʂ��Ă����Ɨǂ��Ǝv���B >>515
��肪�Ƃ�
��Ȃ��̂��܂Ƃ߂�Ƃ���Ȋ������낤���A�ԈႢ�┲�����������狳���Ă���
(�S��https://example.com�ŗ��p�\�Ȃ̂͌��؍ς�)
/save/�F�ۑ�
/web/*/�F�A�[�J�C�u�ꗗ�\��
/web/1/�F�ŌẪA�[�J�C�u
/web/2/�F�ŐV�̃A�[�J�C�u
/web/���t��������fw_/�F���n��E�N���[���[���̔�\���i�����R�[�h�ϊ�����j
/web/���t��������id_/�F�A�[�J�C�u���̐��t�@�C���i�����R�[�h�ϊ��Ȃ��AHTML�R�[�h����URL�̒u�����s���Ȃ��j
��������Q�Ƃ̂��ƁFhttps://en.wikipedia.org/wiki/Help:Using_the_Wayback_Machine#Specific_archive_copy
�܂������o���ĂȂ����ǂ������Q�l�ɂȂ肤�邩���Fhttps://github.com/iipc/openwayback/wiki �V����SPN��Save outlinks�Ȃǂ̃I�v�V�����̃I���I�t���͂�͂�HTTP���N�G�X�g�̒��Ɋ܂܂�Ă�̂���
���̃I�v�V�������g����/save/���������ł����炢���� �ǂ��ł��������Ƃ����A�O�X���ɔ�ׂ�Ƃ��̃X���͏������ݐ��������ԑ�����
�����̂��������Ől�����������̂����� �lWeb�X�y�[�X����������������� >>520
���t�[�u���O��v���O�܂ŏ��ł��邩��ȁB >>510
����2�`3�����������ˁB
�g���鎞�����邯�ǁA�����ɑ��ꂷ�邩�̂悤��
�A�N�Z�X�s�ɂȂ��Ă��܂��B
�u���Ɍ��o������e��ς����˂Ȃ��j���[�X�T�C�g�ɂ��ẮA
�������q������������A����̃X�s�[�h���������ɂȂ������A
�����̃T�C�g���҂�����ɂȂ��Ă邪�A�������_���ɂȂ�����{���ɒɂ��B ����E�Ƃ��������������邩�͒m��Ȃ����A
���N�͎��̔N���Ȃ��B �ނ�Ɉ����|����₷���������Z��ł����ȊE���� �����̊��ł͂��������̊Ԃ����ʂɕۑ��ł��Ă邩����Ƃ������Ă����܂�s���Ɨ��Ȃ� �����͂��A�N�Z�X���Ă����ɉ������Ȃ��ۑ��ł��Ă��邪�A�s����Ŏg���Ȃ��Ƃ����l������̂�
��������ԑт��}�V�����u���E�U���T�C�g���L�̖�肩�͂��܂��ʂ̉������A�������������낤�� �g���Ă��������Ɍ�ɂȂ��āu�A�N�Z�X�s�v�ƕԂ��Ă�����
����Ȃǂ͈�����������ł��Ȃ���������Ɖ�ʂ��ς������u�A�N�Z�X�s�v
�Ɩ{���ɗl�X����
�����ɂƂ��Ă͕K�v�Ȃ�
�N���V���Ђ̃j���[�X�T�C�g�Ȃ�Ď���Ă˂�����
���ɂ���Ďg���܂���Ƃ����b�Ȃ�N�������̑���ɂ���Ăق�����c �ǂ��̐V���Ђ̃T�C�g�Ȃ��
URL������Α����͎�`���悤������ ���Ԃ��o�ɂ�K�R�I�ɃA�[�J�C�u�̏d�v���͑����Ă����̂�
IA�ɂ͊撣���Ăق����� �����̊ԈႢ�ŏ��ł������ԃV���b�N�ȃT�C�g�ȋC�����Ă��� ��is���X�����Ă�
�����ɗ�������Ȃ�ɂ��o���Ȃ��č���E�E�E 14�`15���Ɏ�����������Ă�I�H >>532
�H�ɂ悭����
�����o������ɔ��f����� >>534
�܂��ɋH�ɂ悭����̍D�p�Ⴗ���邗
���̐}�����v���o����
��������������
��������������
��������������
��������������
������ �ŋ߂̐l����InternetArchive���Ēm���Ă�낤�� �m��Ȃ��N���҂������������邵�A�m���ĂĊ��p���Ă��҂�������������
�V�����Ⴋ���W�Ȃ��A�m���Ă�l�͒m���Ă邵�m��Ȃ��l�͒m��Ȃ��Ǝv�� >>517
id_�̃R�}���h�����߂Ēm�������������֗����Ȃ���Athx 30�����炢�O����A5ch�̃X���b�h��Aimgur�̉摜��
�n�l����悤�ɂȂ����ȁB
>>539
������Ȃ��B
�u��������v�Ƃ����s���̂��A�܂��܂���ʓI�ł͂Ȃ���ȁB twitter�Ƃ�����Ɣ����̏؋��ɃX�}�z�̃X�N�V���g���Ă�̂��悭������
����Ȃ��낤�Ǝv��������ł��������̂Ɂc ���̃X���ɂ͖����ɃX�N�V����JPEG�œ\��z���E�E�E >>543
�A�j���Ƃ����Ƃ������낤��
�X�N�V���̖ړI�̑����͍Č����ł͖����Ǝv������ʂɃt�@�C���`���͂ǂ��ł������̂ł� >>541
>�u��������v�Ƃ����s���̂��A�܂��܂���ʓI�ł͂Ȃ���ȁB
��������
�ߋ��̕����⏑�Ђ������̂��߂ɕۊǂ���̂��厖�����Ĉӎ����́A���{�ł͍��ЂƂ��t���ĂȂ�
�i�ǂ����̒n���}���ق������Ȃ��������ċp���������Ƃ����ŋ߂̃j���[�X���D��j
�̂��炠�鎆�̎����ł��炻��Ȉ����Ȃ���AWeb�A�[�J�C�u�����Ƃ����ӎ������t���Ă���͂����Ȃ����
����ɂ��Ă��A�X�N�V���̃t�@�C���`����jpeg���ƂȂ�肪����́H
�m���ɃA�j���̃L���v�Ƃ������掿���v��������ނ̉摜�Ȃ�m���Ƀ_�����낤���� �w�Z��web����̑��݂��������ׂ����Ǝv���� �l�������ė]�v�d���Ȃ�����ǂ����� ���ɏd�����瑽���l�����������Ăǂ�����ϓI�ȏd����͕ς���
�������炢�d���Ă��A�[�J�C�u���������������� �͂��߂܂��āB���m�ł������݂܂���B
�������������̃C���^�[�l�b�g�A�[�J�C�u�ihttp://web.archive.org/�j
�ǂ��URL�����Ă��A�����o���Ȃ��ł��B
�g�b�v���O�܂ł�����URL����闓���Ȃ��Ȃ��āi�E���search�Ȃ炠��j�A�������ȕ��o�Ă邵�B
���g�b�v��URL����闓���Ȃ��Ȃ�A���������������o�Ă܂����A�p��킩��Ȃ��̂œ��{��Ă��킯�킩��܂���B
�iThe Wayback Machine is an initiative of the Internet Archive,a 501(c)(3) non-profit, building a digital library ofInternet sites and other cultural artifacts in digital form.
Other projects include Open Library & archive-it.org.
Your use of the Wayback Machine is subject to the Internet Archive's Terms of Use. �j
�E�ォ�牽��URL�������Ă݂Ă��A���t�̂��o�ė����ɂ��̃g�b�v���̂܂܂ł��B
�ł��X�}�z����Ȃ�O�݂����ɕ��ʂɌ����o���邱�Ƃ��A�X�}�z�������āA���������m��܂����B�ł��ǂ����Ă��p�\�R�����猩�����̂ŁB
�������p�\�R������C���^�[�l�b�g�A�[�J�C�u�o���Ȃ��̂ł����A�X�}�z����Ȃ�o����̂ŁA
�o���Ȃ��̂͂����̃p�\�R�����炾���Ȃ̂��C�ɂȂ��Ă܂��B
����͂ǂ��������ƂȂ̂��킩�����������Ⴂ�܂��B���m�Ȃ̂ł��݂܂���B �u�u���E�U���Â��A�Ȃ����T�|�[�g�O�v�Ɉ�[�B
https://i.imgur.com/ir0AFD6.png
�ȑO Windows 2000 �Ŋ撣���Ă����l (>>94-106) ���v���o���B >>551
�Â��u���E�U�g���Ă܂��H >>552
����
�X�}�z�ł͌������Ď�������T�|�[�g�O�̌Â��u���E�U�̂����Ƃ������������� �y���t�[�zYahoo!�u���O�y�A�[�J�C�u�z
http://mevius.5ch.net/test/read.cgi/blog/1554380939/l50/
74 Trackback(774) 2019/09/30(��) 17:07:59.58ID:th5gp/Yr
Internet Archive��Yahoo�u���O��ۑ�����ƑJ�ڃX�N���v�g��������b�Ȃ��ǁA
web.archive.org/save �̃y�[�W����uSave outlinks�v�Ƀ`�F�b�N�����ĕۑ������
�ǂ���Yahoo�̃g�b�v�y�[�W�ɑJ�ڂ��ꂸ�ɃA�[�J�C�u�ł���݂�����
���������R�������ĉ����������Ǎ��̂Ƃ���S�ď�肭�ۑ�����Ă� >>555
> Internet Archive��Yahoo�u���O��ۑ�����ƑJ�ڃX�N���v�g��������b�Ȃ��ǁA
�j���[�X�Ƃ��m�b�܂� yjsecure.js �����ߍ��܂�Ă邪
�u���O�����ߍ��݂���������? save outlinks����URL���x���ł͎w��ł��Ȃ��́H
/save/�݂�����/saveoutlinks/�݂����Ȃ̂͂Ȃ��H >>556
���t�[�u���O�ɂ�yjsecure.js�����邩�͕�����Ȃ�
�ł��ȑOweb.archive.org�g�b�v�y�[�W��SPN�t�H�[������ۑ��������͉������Ă����_�C���N�g���ꂽ��
�������̃X���ł����ꂪ���ɂȂ��Ă��݂�������
>>557
�����炭�Ȃ�
����HTTP���N�G�X�g��save outlinks���L�����ǂ����w�肷��I�v�V�����͂������i�u���E�U�̊J���ҋ@�\�Ŋm�F�����j
���Ƃ������Ȃ�����save outlinks�ŕۑ�����X�N���v�g��g�߂�\���͂���Ǝv�� ✕���Ƃ������Ȃ�
���f���͂ł��Ȃ� �m�F���Ă���
�m����Yahoo�u���O�ɂ�yjsecure.js�����ߍ��܂�Ă��
https://s.yimg.jp/images/security/pf/yjsecure.js ���ă����N���ǂ̃u���O�ɂ������Ă� �����������ĕ�����������
�E���Ȃ��Ƃ�Yahoo�u���O�̏ꍇ�Ayjsecure.js�̓��o�C���ŕ\���̎��̂ݔ�������i�Ǝv����j
�Eweb.archive.org�g�b�v�y�[�W��SPN�t�H�[�������o�C���[���i�X�}�z��^�u���b�g�j�̃u���E�U����g���ƃ��o�C���ŕ\���ŕۑ������
�E/save/��save outlinks���g���Ɨ��p�f�o�C�X�ɊW�Ȃ��f�X�N�g�b�v�\���ŕۑ������i�Ǝv����j >>561
> �E���Ȃ��Ƃ�Yahoo�u���O�̏ꍇ�Ayjsecure.js�̓��o�C���ŕ\���̎��̂ݔ�������i�Ǝv����j
�����A�����Ō�����Ȃ������E�E�E�B
�C�ɂȂ����̂ŁA�f�f���� http://taruo.net/e/ ���A�[�J�C�u�����Ă݂��B
http://web.archive.org/web/20190930162118/taruo.net/e/
HTTP_USER_AGENT �̍s�ɒ��ځB�������ꂾ�Ȃ��B
�ʏ�� /save/ ���g���ƁA������s�����u���E�U�������̂܂ܑ����֑�����B
�Ƃ��낪���̐V�@�\���g���ƁA�ʂ̖��O��������͗l�B
Firefox ���g�����̂ɁA���ꂪ��،���Ă��Ȃ��B
�܂�A�V�@�\���g���ƃu���E�U�����B�����̂ŁA
���o�C���u���E�U�����ɓ��ʂȓ��������T�[�o�ł����Ă��A���ꂪ�s���Ȃ��B
Yahoo! �u���O�̏ꍇ�Ayjsecure.js ���܂܂Ȃ��f�X�N�g�b�v�����̃R�[�h���o�͂����B
�����������Ƃł͂Ȃ����ƁB
�Z�p�I�Ȑ����͏ȗ��B (��������TOP�y�[�W�ɔ���Ƃ����d�l����...?) �y�V���ǂ����Łu���Ȃ������Ă���h���C���͊y�V����Ȃ���I�v�݂����ȃG���[�͏o���肷��Ȃ��B
�����̍��\�ŕ��i�����Ăяo���Ă���ꂽ�肷�邱�Ƃ�����낤���B �Ƃ����rom-set�͍��@�Ȃ́H
���X�Ɣz�z���Ă邪���v�Ȃ̂� rom-set�����Ȃ̂��������Ă����ЂƂ�����Ȃ��������A
�����̔�����ĂȂ��Â��Q�[����ROM�̂��ƂȂ�č��@�̃t�F�A���[�X�K��Ŏ���Ă�̂ł͂Ɨ\�z �ŋ�Bummer������
�����[�h����Ε��ʂɎ��邯�� >>568
> �����[�h����Ε��ʂɎ��邯��
�Ȃɂ��ɋC�����Ȃ������悗 Too Many Requests���p������� �X�N���v�g�͎��Ԓ������Ƃ��Ȃ�Ƃ��Ȃ肻�������ǁA�蓮�ŕۑ����鎞�߂�ǂ� >>570
��������3���ȏ�
�����Ɏ�낤�Ƃ���Əo�Ă����
�����T�������̂����c ���{��URL(�Ƃ������A���t�@�x�b�g�ȊO�H)���Ƌ��������������Ȃ�̂ǂ����悤���Ȃ��̂��� Too Many Requests
Please email info@archive.org if you have questions about why are you being blocked
�c�����A��k�����ł��������ɂ��Ăق�����B
���͂₱����������Ƃ��낪�Ȃ��A�Ƃ����Ă��ߌ��ł͂Ȃ��̂ɁB
�ŁA��Ɍf�������̉��i�́A�ǂ������Ӗ��H
�u���b�N�Ɋւ��Ă̎���͂�����܂ŁA�Ƃ����������H ���̂Ƃ���Too Many Requests�œ{��ꂽ���Ȃ����A�ǂ̂��炢�̕p�x�ʼn��炢���Əo�Ă�����̂Ȃ́H ����Too Many Requests�o���
���o�Ƃ��Ă�3~5�A���Ŏ��Əo��A���o�Ȃ��Ƃ��͏o�Ȃ�
�P���ɃT�[�o�[���̖��ȋC������ >>577
> ���o�Ƃ��Ă�3~5�A���Ŏ��Əo��A���o�Ȃ��Ƃ��͏o�Ȃ�
�x�[�X�ƂȂ� HTML �����łȂ��A�X�̃t�@�C���P�ʂł͂ǂ��ł��傤�B
HTML ���ۑ��ł��Ă��A�����Ŏg���Ă���摜����ۑ����邽�߂�
�����I�ɔ��s����� /save/ ���N�G�X�g�� Too Many Requests �ƂȂ��Ă��܂��A
���ʂƂ��Ă�������肱�ڂ��A�Ȃ�Ď��Ԃ��������n�߂��悤�Ɏv���܂��B
���̃G���[���b�Z�[�W�A�ꏇ��������ƕςȏ�ɕ����̃s���I�h��Y��Ă��āA
Internet Archive �ł��܂肱�������p�������邱�Ƃ������̂ň�a��������܂��ˁB
 >>578
>>578
���߂�A�X�̃t�@�C���܂ł͌��ĂȂ����番����Ȃ�
�\�����o��悤�ɂȂ����͍̂ŋ�
�ꏇ�Ɋւ��ẮAIA�͊��Ƃ��������K���ȏ�������悤�ȋC�����邗 ���̌ꏇ����ȕς��H
�s���I�h���Ȃ��̂��A���̎�̃G���[���b�Z�[�W�̏ꍇ�͂�����������Ǝv�����ǂ� >>578
�Ƃ������Ƃ́A����IA�ɂ��Ă��A
�E�F�u����Ɍ�����悤�ȁA
�摜�i�ʐ^�Ȃǁj�̔����������o�Ă��������Ă��ƁH
��������������Ȃ� Twitter�̖��ߍ��݂�������ƕۑ�����Ȃ��̂��l�I�Ɉ�ԍ����Ă���ǁA���̌��ۂ��ĈȑO����Ȃ낤�� Save Page Now�̎d�l�ύX���������m�F����
�Eweb.archive.org�g�b�v��SPN�t�H�[���ŕۑ��{�^���������ƈ�U/save/�ɗU�������悤�ɂȂ���
�E/save/�̃I�v�V�����ɁuSave screen shot�v���������
���L���ɂ���Ɓu/web/���t��������/http://web.archive.org/screenshot/https://example.com�v�̌`���ŃX�N�V���摜���ۑ������
��Save outlinks�Ƃ̕��p���\���������N��̃X�N�V���͎擾���Ă���Ȃ����ۂ� >>583
archive.today�݂����ȃA���� �X�N�V��������
���I�ȃT�C�g�ł��ꉞ���� �����̃��[�J���Ń����_�����O������ɂȂ�̂��H >>584
�����ɂ͂�����ƈႤ��������Ȃ�
Wayback Machine�̃X�N���[���V���b�g�@�\�͒P�Ȃ�摜�t�@�C���Ƃ��ĕۑ������
����archive.today��E�F�u����͈ꉞHTML�R���e���c�Ƃ��ĕۑ����邩��A�����N�Ȃǂ͈ꉞ�@�\���� >>586
�����炭�Ⴄ
User Agent���߂��Ⴍ����ȕ�����ɂ�����ŁA��̕��ŏo�Ă��v���L�V�m�F�T�C�g���X�}�z��Firefox����A�[�J�C�u���Ă݂�
https://web.archive.org/web/20191011021858/http://taruo.net/e/
����Ε����邯�ǁA�g�p�����u���E�U�̏��UA���܂߂ĕʂ̓��e�ɒu��������Ă�
�����炭web.archive.org�̃T�[�o���̏��ȂƎv��
�w�b�h���X�u���E�U���������g���Ă�̂��� >>587
����͖Y��ĂȂ���ȁA�O�̂��߁B
 Too Many Requests���}�W�şT������
Too Many Requests���}�W�şT������
�ق�ƂɃj�[�Y�����Č����Ă�̂��I�H�ƌ��������Ȃ� >>590
����͕������Ă邩����v
�ł�Internet Archive�̕��ɂ̓X�N���[���V���b�g�ƕ��ʂ̃A�[�J�C�u���ȒP�ɐ�ւ���@�\���Ȃ����ۂ������
��r�̑Ώۂɂ͂Ȃ�Ȃ��悤�ȋC������ ���FIA�̓A�����J�l�l�̕��œ��{�l�̕��ł͂Ȃ��B�����͂킫�܂���ׂ��B
���{�ł��������p�̊T�O��@�������邵���Ȃ��B �䕗�Ō����݂�����{�݂��Վ��x�Ƃ̍Œ������A
�����[���A�uToo Many Requests�v�ɓY�t���ꂽ���͂��ς�������I
https://i.imgur.com/Cy8ibMt.jpg
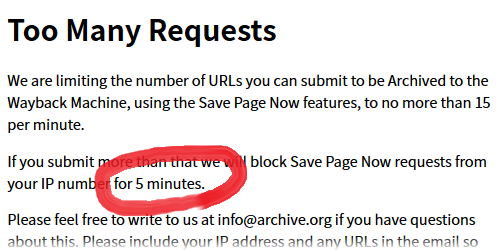
Too Many Requests
We are limiting the number of URLs you can submit to be Archived to the Wayback Machine, using the Save Page Now features, to no more than 15 per minute.
If you submit more than that we will block Save Page Now requests from your IP number for one day.
Please feel free to write to us at info@archive.org if you have questions about this. Please include your IP address and any URLs in the email so we can provide you with better service. >>594
google�|��@
> ���N�G�X�g����������
>
> [�������y�[�W��ۑ�]�@�\���g�p���āAWayback Machine�ɃA�[�J�C�u���邽�߂ɑ��M�ł���URL�̐���1��������15�ȉ��ɐ������Ă��܂��B
> ����ȏ㑗�M����ƁA(���Ȃ���)IP�A�h���X�����Save Page Now���N�G�X�g��1���ԃu���b�N����܂��B
>
> ����ɂ��Ď��₪����ꍇ�́Ainfo @ archive.org�܂ł��C�y�ɂ��A�����������B ���ǂ��T�[�r�X��ł���悤�ɁA���[����IP�A�h���X��URL���܂߂Ă��������B
�u(���Ȃ���)�v���������t�������� �e�n��̔���������鎩���̂�URL�����܂ɂ�������Ȃ�����
�A�[�J�C�u����Č��悤�Ǝv������������bummer >>595
�x�[�^�łƂ��Ă͊��ƑO�����������Ă����ǁA�������O�ɐ����łɂȂ���
�F�X�I�v�V�������t������悤�ɂȂ������ >>596
���肵����u���b�N�������̂��B
�}���ő�ʂɎ��̂�����Ȃ�ȁB�������Ȃ��B
>>600
�m���ɂ��������A1���ӂ�60��܂ł�����ȁB
�ǂ����T�d�ɂ��Ȃ��Ƒʖڂ��B InternetArchive��������ꂽ����̃��\�[�X�őS���E����̃��N�G�X�g���t���Ȃ��Ƃ����Ȃ�����A�����̃��~�b�g�͎d���Ȃ���
�K�͂��l�����1���Ԃ�15�܂łȂ�ނ���ɂ�������Ȃ����� ����100�����N�قLj�C��save��������20�߂��͈�x�ɕۑ�����邵�u���b�N������Ȃ��������ǂ�
HTTP���N�G�X�g�ɒ���POST���Ă��Ȃ����炩������Ȃ��� >>603
�ǂ���������save������� >>604
���[�U�[�X�N���v�g��https://web.archive.org/save/��window.location.href��������window.open���Ă邾���� ���Ȃ��悤�Ɋ��������ǁA��Âɍl�����畁�ʂɏ\������ 4�b��1������\�������邭�炢����
��قǑ�ʂ�URL�𐔎��Ԃŏ����������ꍇ�Ȃ�����������瑫��Ȃ���������Ȃ����ǁA����ȏ͂��������Ȃ� >>608
����قǑ�ʂ�URL�𐔎��Ԃŏ����������ꍇ�Ȃ������������
������Ȃ���������Ȃ����ǁA
�c���������Ď����͂���Ȃ�Ȃ��B
�����ăf�C���[�X�|�[�c�̌����Ȃ�āA�ЂƂ̃J�e�S���[�ł�
�L���𑱁X��悹���Ă������̂�����A�g�b�v���n���݂����ɃR���R���ς���Ă����̂�B
������ڂ���������ɁA��肽��������ԂƁA����̌��ʂ��قȂ邱�Ƃ��{���ɑ����B
�����������悤�ɋL������悹���Ă����̂��A�����X�|�[�c��
���n�߂���ŁA���ɍ������Ă�B
�X�|�j�`������݂����ɁA�L���͒lj����Ă��g�b�v�͂��炭�ς��Ȃ�
���炢�������̂����ǁB �j10000��
ttps://i.imgur.com/xXiIGJu.jpg >>609
�ڎw���Ƃ��낪�悭������Ȃ�����I�O��Ȃ��ƌ����Ă邩������Ȃ����A
����I�ɍX�V���`�F�b�N���āA�ȑO�̏�ԂƕύX����������/save/�𓊂���悤�ȃX�N���v�g�g��H >>611
�u�I�O��Ȃ��ƌ����Ă邩������Ȃ��v���Ă̂�
�u����I�ɍX�V���`�F�b�N���āA�ȑO�̏�ԂƕύX����������/save/�𓊂���悤�ȃX�N���v�g�g��H�v
�Ƃ����̂�������ɂƂ��Ă͓I�O��ȃR�����g��������Ȃ����Ď��� �V�@�\�̃X�N�V���A�ȑO�������������Ă���ǔ��f���x���������ȁH �ʏ펞�ł����삪�s����ɂȂ邱�Ƃ����Ȃ��Ȃ�����A�V�@�\�Ƃ������Ƃŗ]�v�ɕs���肳�������Ă�̂�����
�O�̂��߂Ɉꉞ�X�N�V�����擾�������Ă݂Ă� �L���v�`��������݂Ė��炩�ɕۑ��ł��Ă�̂ɂ܂�Hm.��Ԃ��̂͂Ȃ�Ȃ� �܂��s���őS�R�擾�o���Ȃ��E�E�E
���{����̃A�N�Z�X�����e���Ă�Ƃ��Ȃ����?
���̎�̃A�[�J�C�u�擾���܂����Ă�͓̂��{�l��������Ƃ��� �E�u���E�U���Â�
�E�A���������Ă�1���Ԃ�IP�u���b�N��H����Ă���
�E�����̃V�X�e���s��
�D���Ȍ�������I�ڂ� >>612
������Ȃ��B
>>619
�ϊ����ׂ� URL �� HTML �����ɑ�ʂɂ��邽�߈ُ�Ɣ��f����A
���ʂƂ��ăC���f�b�N�X����O����Ă���Ƃ��A���������\���B
���̃\�[�X������ƃX�^�C���V�[�g�� <style> �v�f�ő}������Ă��āA
���̒��Ƀt�H���g���̊O���Q�Ƃ� 1000 �ȏ゠��B ����ϑS�R�擾�ł��܂����
�ŐV��url����͂���ƈ�T�ԑO�̃A�[�J�C�u��url�ɔ����� ����Ă݂�
�X�N�V���͑S�R�_�������������ʂ̃A�[�J�C�u�͎�ꂽ�Ǝv��
https://web.archive.org/web/20191016233430/https://www.dworks-ent.com/ first archive���ǂ����̕\���~�߂�������̂���
���ꊄ�ƍD���������� >>623
���⍡�x�͕\�����ꂽ��
�P�ɒʐM���������������� �V����SavePage�AUserAgent����������邹�����T�C�g�̃f�t�H���g���ꂪ�p��ɂȂ��Ă��܂���
�܂��N������Ă����ꂳ��邩��ǂ��Ƃ����Ηǂ��� �G���[���̌x�������̂őS�R�y�[�W���Ȃ��g���Ȃ��T�C�g�ɂȂ��Ă��܂����E�E�E ����������܂�ŕۑ��ł��Ȃ���
���炭�҂����Ȃ��悤�� ��������肩��Save outlinks�̒��q�����������悤��
Save Page Now�t�H�[���ɓ����������N����URL�̃A�[�J�C�u�͎��邯�ǁA�����N��̂͑S�R���Ȃ�
�G���[���o���ɂ������[�L���O�J�[�\�������X�Ƃ��邮���葱����
������x��}�V���X�y�b�N�̖��ł͂Ȃ��͂��Ȃ��ǂ�
�����Ԃ����ɊԊu���Ď����Ă邪�A����ς�������܂ő҂����Ȃ��̂� ���C�悭���g���C����done�ɂȂ����y�[�W�����������Ċm�F���Ă݂�������Ă̂����p�x����
�k�J���͂�ςȂ���ň��肷��܂ł����̂��ʂ� >>628
>>629
�������������ۂɂȂ������ǁA2��3���u������A�[�J�C�u����Ă���
�\����O���O������Ă邾���œ����I�ɂ͎��Ă�̂��� �����ԑO�̂ł��A�[�J�C�u�ꗗ������ƑS�R�c���ĂȂ��̂��
�����������邾�낤�Ǝ擾�������邯�ǐ��_�I�ɂ炢 >>631
�ǂ����Ă��S�z�Ȃ�API�Ŋm�F���������
�������͂����ɔ��f�����
https://archive.org/help/wayback_api.php ���肪�Ƃ�
�ł������Ă݂����1���ȏ�擾�o���Ă��Ȃ��͗l�E�Eorz ���܂�ɂ��G���[�A�����邩��X�e�[�^�X�R�[�h���ɓK�X���g���C����悤�ȃX�N���v�g�����Ă��璲�q�ǂ������ɓ˓������炵���m�F���Ƃ�˂� /save/http://url~�ɃA�N�Z�X�����/save�ɔ�����̂͐V���Ȏd�l�ł����H https://i.imgur.com/mi8lPHF.jpg
https://i.imgur.com/312FfjE.jpg
�Ȃ�������ʏɓ˓����Ă܂���
�Ƃɂ����y�[�W�E�摜�Ƃ��ɐ�ɐi�߂₵�Ȃ�
>>632
�����������玩���͂��ꂩ���ȁc
�挎�ӂ肩����Ȃ��Ⴂ���Ȃ����̂������������� �Ɩ�����Ȃ���H�Ȃ���������ȗ͂�
�Ă������s�����IA�̌���݂Ă����������̂����� �E�F�C�o�b�N�E�F�[�C������ �]�v�ȋ@�\����ˁ[���班���ł��y�����Ă��� �w�ǂ̃T�C�g��y�[�W������o�^�����Ă��ꔭ�ŊȒP�ɂ́H���Ȃ��悤�ɂȂ��Ă�
��t�W�߂ĉ��������Ă�
�ň�����A����Ȃ�X�N�V������������}�V�� >>636
�����ł�
������ύX���ꂽ����
>>637
�u���E�U��URL���̓o�[��web.archive.org/save/https://example.com�ƒ��ł������玩�����uWayback Exception�v�ɂȂ���
�P�Ȃ�s���������Ȃ����A������������/save/�̃y�[�W����̓��͂̂ݎt����d�l�ύX�ɂȂ����̂�����
>>641
�`�F�b�N�{�b�N�X�̃I�v�V�����̂��Ƃ���
����֗�������l�I�ɂ͏d�Ă���ǐl���ꂼ�ꂩ >>642
>���ł������玩�����uWayback Exception�v�ɂȂ���
������������Ȃ�save�ł���
����ς�ꎞ�I�ȕs��������݂����� /save/http://url~�����܂Œʂ�ۑ�
Save This Url��/save�ɗU��
���X�T�[�o�[�G���[�Ԃ邯�Ǖۑ��ł��Ă���ۂ��� Bummer�o������10�{�ɂȂ����C������� �O����1���ȏ�o�Ă��C��������Ђ���Ƃ��ďo����100%�������H Bummer�o�����͂ǂ������⎞�ԑтɂ���ĕς����ۂ������
�����͑̊���0.5~2%���炢�����A5�����z����l������炵�� >>622
���肪�Ƃ��@
17 Oct 2019�ŎB��Ă�̂�������ł��m�F �����ƐϋɓI�Ɋ�t����Ă����Ǝv�����ǂ�
Wikipedia�Ȃ�ăN�\�f�J�A�s�[�����Ă�̂� Wikipedia�݂����Ȃ������L���������Ƌp���Ċ�t����C�������邪�A
Internet Archive�݂����ɑS�����������Ă��Ȃ��Ƌt�ɐS�z�ɂȂ��Ċ�t�������Ȃ��Ă��܂� Save outlinks�œǂݍ���ł���郊���N��50�����E�݂���
�O�������N���������낤�ƍő��50�����ǂݍ��܂�ĂȂ�
�܂����s���ɊO�������N��H��Ƒ�ςȂ��ƂɂȂ邩�琧����������͖̂����Ȃ����ǂ�
�����ǂݍ��ރ����N���ǂ�������őI�肵�Ă���̂����C�ɂȂ�A�����������烉���_���Ȃ̂�������Ȃ� ���ʂȂ�u�擪����p�[�X����50�ɒB������I���v�Ƃ��A����Ȋ����őg�ނƎv�����ǂȁB �u���E�U�̗���������web.archive�Ŏ�������̗�����web.archive��������Ă鎖���������ǁA
�ǂ������炢����ł��傤�c�H ���͐��Ƃł͂Ȃ����A����͂��Ԃ�ʂ̘b���� 100������ŏ����鎖�͂Ȃ�
�����A�J�����_�[�o�R���A�[�J�C�uURL���ł����̈Ⴂ���Ǝv�����ǁi�J�����_�[�͔��f���x���j �m����100%���肦�Ȃ���
����܂Ō���Ă��A�[�J�C�u���u���E�U�̗������������㌩��Ȃ��Ȃ������Č��������Ɖ��߂������ǁA
�����������ƂȂ�Wayback���̃V�X�e���s��Ɨ��������̃^�C�~���O�����R�d�Ȃ�����Ȃ����� ���ꋭ���Z�[�u�ǂ������
/save/�ɃA�h���X���ꂽ�Ƃ���ۑ��ς݂̌Â��y�[�W�ɔ�Ԃ��猻���_�̂��ۑ��ł��� >>659
����ۑ�����Ă���͂��ł́H
�A�h���X�̓����͍����݂̎����ɂȂ��Ă���͂��B
���������{�̎����Ƃ̓Y���Ă��� �����������Ă��܂����@�������悭�Ȃ�������
�����ƕۑ����ꂽ�̂��m�F 18 �������肩��ł��傤���A�ꕔ�̌Â��u���E�U�ւ̑Ή����������Ă��܂��ˁB
�S���g�����ɂȂ�Ȃ��Ȃ��Ă��� Internet Explorer 11 ��
�J�����_��ʂ��`��ł��Ă��邱�Ƃ��m�F�B
https://i.imgur.com/5XWVxdq.png IE11�̓T�|�[�g�����̃u���E�U�������
�����łȂ������� Web�J������Ă��IE�͂Ƃɂ����ז��҂ł����Ȃ����ǂ�
�ʑΉ��Ƃ����ʓ|�����Z�L�����e�B��̌��O������
IA���悭�T�|�[�g���������ȁA�v�]�����������낤�� �u�������Ⴎ���Ⴞ���Ljꉞ�g����v���x�ł��\������� ���ς�炸�������B�u���b�N���Ԃ��ܕ��ԂɒZ�k�B
 �A����Ńu���b�N���Ԃ��ς��Ɨ\�z
�A����Ńu���b�N���Ԃ��ς��Ɨ\�z
�܂��u���b�N���Ԃ������Ȃ��肩�̓}�V�ł��� URL�̖������u?�v���ƃA�[�J�C�u�����Ȃ��o�O�������H
���m�Ɍ����Ə���Ɂu?�v������ĈӐ}���Ȃ��y�[�W���擾�����
�Ⴆ��
example.com/test?
���A�[�J�C�u���悤�Ƃ��Ă�
example.com/test
�ƂȂ��ăA�[�J�C�u�ł��Ȃ�
��Ƃ��Ă͓K���ȃN�G����t����A�[�J�C�u�ł���B��̗�Ȃ�
example.com/test?hoge
�Ƃ���Ύ���AURL�͕ς�邯��...
�N�G���̊J�n�_�ƌ�F�����Ă�̂��ȁH ����͎Q�l�ɂȂ�
�N���X�^���ЂƂ�������������� >>673
> URL�̖������u?�v
����ȃT�C�g������̂��B�m��Ȃ������̂��B >>676
�p�[�Z���g�G���R�[�h����Ă���̂��f�R�[�h����}�k�P URL���G���R�[�h���ĕۑ����Ȃ��Ƃ���Ⴛ���Ȃ��� �����ł����A���Ⴀ�ۑ����@�������Ă���
https://web.archive.org/web/*/https://ja.wikipedia.org/wiki/�\�E�i���ł���%3F URL �p�[�Z���g�G���R�[�f�B���O �Ō��� �܂�?�L�������G���R�[�h���Ă������Ӗ��������
URL�̓��{�ꕔ���S�����G���R�[�h���� �uURL �p�[�Z���g�G���R�[�f�B���O�v�Ō������ĕ�����Ȃ��Ȃ���͂��]�I��������߂� >>683
Edge �Ȃ��ƁAlocation.href �� document.URL ��
decodeURI() ���ꂽ��Ԃœ����Ă��܂�����˂��B
�A�h���X�o�[�̒��g���R�s�[�����ꍇ���܂��R��B
https://ja.wikipedia.org/wiki/�\�E�i���ł���%3F
�܂�����u���E�U���ŒP���� http://web.archive.org/save/ �ɕt����
�A�h���X�o�[�֍ē������邾���Ȃ���͋N����Ȃ��Ƃ͎v���܂����B ���� >>676 �Ŏ����œ��������Ă����
URL�G���R�[�h�̗����ȏ�ɋ~���悤���Ȃ� Wayback Machine
���̊Ԃɂ����t�[�j���[�X�̃X�N���[���V���b�g������悤��
�Ȃ��Ă����B
���ꂾ�ƃ��t�[�̃g�b�v�y�[�W�ɑJ�ڂ���邱�Ƃ��Ȃ��B
Save screen shot�@�@�Ƀ`�F�b�N�����Ă���N���b�N�B �����uattention request�v�Ƃ��o��(�L��֥`) �ߌォ��503���p������Ǝv������
�����Ȃ胁���e�i���X�ɓ˓� >>686
�����ǂ�������擾�ł���URL���Ă���Ȃ����H
�{���Ɏ��Ă�Ȃ爫�����}�E���g��肽�������ɂ��������Ȃ��Ă�
���̃J�����_�[�ł͐ۂɂȂ��Ă邪���ĂȂ��i�G���R�[�h�L�薳�������j
https://web.archive.org/web/*/https://ja.wikipedia.org/wiki/�\�E�i���ł���%3F web.archive.org �̃o�O����
�{���G���R�[�h�ς݂Ȃ疳�������Ⴂ���Ȃ�������%3F (?) ����������Ă� �܂��Ȃ���������������
�ۑ�������������m�F���悤�Ƃ���Ɓu�Z�[�u���܂����H�v�̃y�[�W�ɔ��
�h���C������������Ƃ��Ă�1���q�b�g���Ȃ� >>690
�����e�i���X�͎��O�ɗ\�����Ăق������ �A�h���X�̕�����ɂm�f���[�h��������ublock���������Ă�P�[�X��������
archive�S�̂��X���[�ɂ��Ȃ��Ƃ����� Internet Archive
We're experiencing some technical issues, cause
undetermined at the moment. Site availability may be
spotty for a while. We will update when we have more
news. Thanks for your patience!
5:49 - 2019�N11��14��
https://twitter.com/internetarchive/status/1194719014045380608
https://twitter.com/5chan_nel (5ch newer account) Internet Archive
Update: We should be stable again, looks like it was a
router issue.
6:06 - 2019�N11��14��
https://twitter.com/internetarchive/status/1194723218638036992
https://twitter.com/5chan_nel (5ch newer account) �H
ttps://i.imgur.com/nINvdBL.jpg �������{�ł͂���ȏ�L���ɂȂ��ė~�����Ȃ�
�A�[�J�C�u�̏d�v�����L�܂��ĂȂ���ԂŗL���ɂȂ��Ă�
�A�[�J�C�u�̍폜�⋑�ۂ��炯�ɂȂ関�������݂��� �k�֔��p�ق͉����A�N�Z�X�e���Ă�˂� >>701
����}���ق̃A�[�J�C�u���������×~�ʼn���I�Ȃ炢������ �������p�̊T�O���L�߂ĊJ�������邵���Ȃ� �^���ʼn��サ���Ƃ���T�C�g�̊Ǘ��l��Internet Archive�ɉp�ꃁ�[�������āA�؋��p��SavePageNow�Ŏ��ꂽ�A�[�J�C�u���\���ɂ���������͑O�Ɍ������Ƃ�����
Archive.today�ɂ��A�[�J�C�u����Ă�l����������؋������������邱�Ƃ͂Ȃ��������ǁAWayback Machine�̃A�[�J�C�u���Č��\�낤����� ���Ȃ݂ɂ��̃T�C�g�͉��㑛���̌�ia_archiver��e���悤��robots.txt��ύX���Ă����ǁA
SPN�ł̓u���E�U��UserAgent���p������̂�SPN�ŃA�[�J�C�u����邱�Ǝ��͍̂��ł��\�Ȃ܂�
�������擾���Ă�"This URL has been excluded from the Wayback Machine."�Ƃ�����̕\�����o�ĉ{���͂ł��Ȃ�
" Boomer���X�V���Ă�Boomer���o��悤�ɂȂ����B outlink���ꗗ�̑��̃y�[�W���ۑ������Ⴄ���玟�̃y�[�W��outlink�擾���悤�Ƃ��Ă�10���ȏ�҂��Ȃ��Ă͂Ȃ�Ȃ��B
�擾����̃y�[�W��10���ԕۑ��Ȃ��ɂ��āA���̃y�[�W�����ۑ����Ă��������̂ɁB >>709
> outlink���ꗗ�̑��̃y�[�W���ۑ������Ⴄ���玟�̃y�[�W��outlink�擾���悤�Ƃ��Ă�10���ȏ�҂��Ȃ��Ă͂Ȃ�Ȃ��B
���[�A�����Ȃ̂��B����͒m��Ȃ������B Mapion�Ƃ�Google Map������悤�ɂȂ��Ăق����B
�摜�̎B�e�ꏊ�������̂Ɏg���Ă����ˁB ��T�ӂ肩��܂����������Ȃ��Ă�ȁB
�V�����擾�������̂��A�ߋ��̈ꗗ�ɂ������f����Ȃ��Ƃ��B
�܂��͎擾�ł����Ǝv������A�m�F������܂��擾�O�̉�ʂɖ߂����������Ƃ��B 503���Ԃ��Ă���悤�ɂȂ����̂ŁA�A�N�ւ��ꂽ�̂��Ǝv�������A
TOP�J������Scheduled Maintenance�������B�i�v�A�N�ւ���ĂȂ���������ǁB ���������͂��b�ɂȂ�˂����炢������Ԃ���
Sorry�A��
������̌��ʂ��S�R�o�ė��˂� �ŋߒ��q�����Ȃ��Ǝv������}�Ɉ����Ȃ�����c���f���Ȃ̂��H
>>715
������API�ɂ��甽�f����ĂȂ�����~�߂��ق����ǂ��� �������e�ジ���Ƃ����
This page is not available on the web
because of server error �g�����ɂȂ���
�[��Ɏ�����������Ǝ��Ă邩�������� �����I�ɂǂ����Œf���ł����Ă��Ȃ����Ƌ^�����x�� Wi-Fi�̋߂��œd�q�����W�g���Ă�̂�������Ȃ� �����擾����Ă���url�̃A�[�J�C�u�ꗗ�ł�23����10:00(UTC)���炢����o�^�b�Ǝ擾�~�܂��Ă�̂�
�T���ɓ����Ă邩�畜���x��Ă��� �����g���Ȃ��Ȃ����炷�������� �Ƃ肠�����V�K�̎擾�͒��������ۂ�? ����ւ��ɃE�F�u�����������Ȃ��Ă� �����s���肾�Ɗ�t�̂��肢�̕K�����ɐ����͂����� ���������ۑ������̂��m�F������قڑS��
���ꂶ��ƂĂ���t�͂ł���� ��t���Ȃ��Ɨ]�v�ɍ����Ȃ邾�낤���A���z�ɗ]�T���o�����班����t���悤���Ǝv��
�C���^�[�l�b�g�A�[�J�C�u�����S�Ɏg���Ȃ��Ȃ�����{���ɍ��邵 Twitter�Ђ����N�ȏ�c�C�[�g���ĂȂ��A�J�E���g��12���ɍ폜����炵��
�̐l�̃A�J�E���g�������Ă��܂��̂��Ɩ��ɂȂ��Ă���Ǐ������獢��
�Ƃ肠�����}���œ��ɑ厖�ȃc�C�[�g�͂����ɕۑ����Ă邯�� �݂�Ȃ��̂čC���T�u�C�����܂����Ă邩��T�[�o���������Ă���
UserStream��p�~�����̂������̖�肪�������݂�����������͕����邪�A
�ɂ��Ă����O�C���m�F�ł��Ȃ���Έꊇ�폜���Ă͎̂c��������C�͂���� ���N���ĂȂ�
�t��bot���e�Ȃ炱��Ɉ��������炸�ɐ����c��낤��
�o�����X���������ɂȂ肻���� �����Ɣ����傫���������߂��A�̐l�̃A�J�E���g���ǂ����邩��肢���@��������܂ō폜�͓��ʉ������邻����
�Ƃ肠�����]�T�͏o�������ǁATwitter�̃A�[�J�C�u�Ƃ������Ď������ł����� archive.is �I�ՏI��(�L��֥�M)�H
#192q�c�Ƃ��o�� 👀
Rock54: Caution(BBR-MD5:1322b9cf791dd10729e510ca36a73322) archive.is�����ɕۑ����������ʂ���
IA�̕���23���ȍ~�ɕۑ��������e�����ԂƂƂ��ɏ����ă��o�C ttps://news.livedoor.com/lite/article_detail/17447598/ >>736-737
�m���ɕۑ��͂ł��邪�A������҂����Ԃ��N�\���߂���B
�Ă̒�A�f�C���[�X�|�[�c�̌|�\�J�e�S���[�������A
�҂����Ԃ̂������ɋL������lj�����āA���IA�Ŏ������Ɣ�ׂ�
�u�Y���v�����������������Ȃ����c�B��������Ȃ�A�S�ē��������Ŏ�肽���̂ɁB �ł����͂�肽����B�ł�����I���傠�邩�H
�����A�������̓����e�i���X�ł�������̂��H
���ς炭�f�����[�X�|�[�c�̋L�����A�e�L�X�g��Ԃł������Ȃ��������A
������ꂽ���̂́A�ȑO�Ɠ����悤�ɃJ���[�E�ʐ^����Ŏ��Ă�B �����܂Ńf�C���[�X�|�[�c�̊��S�Ȃ�A�[�J�C�u�ɌŎ����闝�R���C�ɂȂ�
�T���猩�Ă�ƁA�����������������ǂ��Ȃ��������ُ�Ɍ����Ă��܂� ������Ŏ����Ă���Ώۂ��ʂ̋L���Ƃ��ł͂Ȃ��āA
�g�b�v�y�[�W�Ƃ��J�e�S���[�ʂƂ��̈ꗗ�y�[�W������Ȃ����� �f�C���[�X�|�[�c�̃}�j�A�@���@�M���I�ȍ�_�t�@�� >>146�����肪���o���ȁB
�L�[�{�[�h���o���o���@���ăA�[�J�C�u���擾����s�ׂ��̂��̂�
�A�h���i�������s���s���b�Əo���Ⴄ�l�Ȃ낤�ȁB
�{���ɕK�v���������Ă���Ȃ�A�������Ƃ����������ʂ̕�����
�l���Ă邾��B��N�Ԃ��̊ԁA������Ă��B �u�������͐M�p�Ȃ�Ȃ��A�����̎�ł�������ƃA�[�J�C�u�ł������m�F�������v�Ƃ������Ƃȕ�����Ȃ��ł͂Ȃ����A����ɂ��Ă����Ԃ̖��ʂł́H ���ۉ摜���C���̃T�C�g�Ȃ̂ɉ摜���S�����Ă��炸
�A�[�J�C�u�������̎ז��ɂȂ��Ă邾���̃A�z�A�[�J�C�u���`���z������������
�m���ɂ��Ă̂͂킩��Ȃ��͂Ȃ� ���H�R��
ttps://f.uploader.xzy.pw/eu-prd/upload/20191128232625_34756b6f49.png >>748
���N���O�̕����ꂽ�C�O���_�Q�ŃR���悭����������
��ɓǂ݂Â炢�F�R�[�h�������ă��c Archive.is �̑҂����Ԃ��N�\���߂���Ƃ����b�B
���T�C�g�Œ���I�ɃA�[�J�C�u���擾������X�N���v�g�𑖂点�Ă��܂����A
1. ���O�� http://Archive.is/ ����g�[�N�����擾�B
2. �^�[�Q�b�g URL ���̏��� http://Archive.is/submit/ �֑��M (POST)�B
3. 200 �������Ԃ�A�R���e���g�{�f�B�� loading.gif �ւ̎Q�Ƃ�
�܂܂�Ă���A�[�J�C�u�����Ɣ��f���I���A���Ƃ͒m���Ղ�B
�\ �ȏ�̎菇�Ŗ��͋N���Ă��Ȃ��ł��ˁB
�擾�J�n����A�[�J�C�u�����܂Ŏ��Ԃ��|����̂͂����瑤�̃v���Z�X�Ȃ̂�
�d���������Ƃ��āA�擾�𗅗��y�[�W���J��Ԃ��ǂ܂���̂�
�l�Ԍ����̂����̉��o�B
>>739
�L���̃��X�g�̓x�[�X�� HTML �Ɋ܂܂�Ă��āA�A�[�J�C�u���͈�ԍŏ���
�ۑ������t�@�C���ł�����A�҂����ԉ]�X�͖��W�B
�P�ɃA�[�J�C�u���J�n������܂łɎ��Ԃ��|�����Ă��܂��������B
>>748
CloudFlare �Ńz�X�g����Ă���T�C�g�� Tor �o�R�ŃA�N�Z�X����Ɨǂ��o�Ă��܂����ˁB
�������O�ɂ��ꂪ�ˑR�o�Ȃ��Ȃ��Ă��܂��A�t�ɂ����炪�u�܂������Ōq�����Ă�?�v��
�s���ɂȂ������Ƃ�����܂��B 214���ɂ͊e�A�[�J�C�u�T�C�g�̎������̒m���ɂ��ău���O��Qiita���ǂ����ɂ��Ђ܂Ƃ߂ĕ��͉����ė~����
���v�͂��Ȃ肠��Ǝv���� archive.is�A���������N�̒u�����p�~���ꂽ�H
28���ȍ~�̃A�[�J�C�u�͌������N�ɔ�� 23���ȍ~����S���A�[�J�C�u�����Ă���ǁE�E�E�E �ȂA�[�J�C�u�����͂��Ȃ̂Ɍ�����URL����Ă��A�[�J�C�u����Ė������ďo����ǁc
����ł�����x�A�[�J�C�u����Ə��߂ăA�[�J�C�u���������ɂȂ��ĂāA������URL�����Ƃ܂��������ĂȂ���ǁc�Ȃɂ��� ������x����Ă݂���ǂ����A�[�J�C�u�͈ꉞ�Ƃ�Ă�݂���������
������URL����Ă��ŋ߂̃A�[�J�C�u�͌��ʂɏo�Ă��Ȃ��Ȃ��Ă���ۂ� ��������ɂ��̃X���ۑ����ău�N�}���Ƃ����������قǂŏ�����
���͂܂Ƃ��ɕۑ��ł��Ȃ��炵�� �ۑ��֘A�̏����ƃA�[�J�C�u�̃C���f�N�V���O�E�{���֘A�̏����͕ʁX�̃v���O�������S���Ă邩���
����͌�҂̕������s����ɂȂ��Ă�Ǝv�� ���ꂶ��g�����ɂȂ���
���������� >>757
�t�@�C���� Internet Archive �ɕۑ��ł��Ă��邩�ǂ������m�F���邽�߂�
�擪�� http://web.archive.org/web/2/�` ��t���� URL �Ń`�F�b�N����̂ł����A
/2/ ��ۑ������̐����ɒu�������� URL �փ��_�C���N�g�ł��Ă���̂ɁA
�܂蓖�Y�����̃A�[�J�C�u�����݂��邱�Ƃ������Ă���̂ɁA
���̃��_�C���N�g��ł� Save Page Now (404 Not Found)�B
������T�ԂقǁA����Ȃ��Ƃ��x�X�N���Ă��܂��B
���Â��u�ʃv���Z�X�ȂȂ��v�Ɗ����܂��B ����̌��͊�t�W�߂邽�߂̏��H�ɂ��v�������� ����ȏ��H�Ȃ�Ă��ꂽ��
�u���ŕς�������Ȃ�����Ȃ���
����Ȍ딚�����₵�Ȃ�
https://i.imgur.com/L12ywG3.jpg ���ʂɃ����N���b�N�Ŏ���Ă��Ă��u���_�C���N�g���J��Ԃ��s���܂����v
�uCookie ���������Ă݂Ă��������v�Ƃ����\�������X�o���. �d�g�݂��ǂ��킩���
�������̃N�b�L�[�g���̂� IA�́u�N�b�L�[��H�ׂȂ��u���E�U�v�Ƃ��ē��삷�邩��
�N�b�L�[��H�킹�邽�߂ɖ������_�C���N�g���[�v�A
���ꂪ�������肻�̂܂܃A�[�J�C�u����Ă��܂�����Ȃ��́H �ꎞ�I��IA��e���Ă��Ƃ��Ă������I�ɂ͏��͕ۑ�����Ă�̂�
�������Ǝv���Ă������S���� archive.is
robots.txt�ɏ]��Ȃ� 👀
Rock54: Caution(BBR-MD5:1322b9cf791dd10729e510ca36a73322) donate��💗���t���Ăď���
�Ƃ�����60�y�^�o�C�g�����Ă��̂�
https://archive.org/donate/ >>773
���A�����������������
����n�[�g donate
�� ttps://i.imgur.com/g3xBqiq.jpg Donate�����N�Ƀn�[�g�}�[�N���đ��̃T�C�g�ł����\����� �m���ɉp�ꌗ�̃T�C�g���ƌ��\�悭������
���������������������K������������낤�Ǝv�� ���{�l��������L�ȂŐ��j���A���X�͂Ȃ����Ă��Ƃ��낤�� �����ƌ���ׂ������Ȃ��ƌ���ׂ��� �ď��ɓ����f�[�^�������ꍇ�u�����ł����v�Ƃ����L�^���Ă�̂���
����Ƃ����S�d���ŕۑ����Ă�̂��� �X�|�[�c�����A�[�J�C�u����Ɓu�L��������v�̕������܂��܂��(�L��֥�M) �J���Ȃ�(�L��֥�M) >>783
���O�ŃA�[�J�C�u��邩�H
�I����̃\�[�X�ۑ�����Ȃ��A���̏u�ԃu���E�U�ŕ\�����Ă��Ԃŕۑ����鎩��̃u�b�N�}�[�N���b�g����
�u���E�U�Ńu�b�N�}�[�N����Εۑ��ł���
�`����javascript:�̓u���E�U�ɂ���Ă̓y�[�X�g�����Ƃ��Ɏ����Ŕ������̂ŁA������Ă��玩���ŕt�������ău�b�N�}�[�N���邱��
javascript:(()=>{'use strict';const c=new Date(),h=document.documentElement.cloneNode(true);
let n=h.querySelectorAll('[href]'),i=n.length-1;while(i>=0){n[i].href=new URL(n[i].href,location.href).href;i--;}n=h.querySelectorAll('[src]');i=n.length-1;while(i>=0){n[i].src=new URL(n[i].src,location.href).href;i--;}
const b=new Blob([new XMLSerializer().serializeToString(document.doctype)+h.outerHTML],{type:'text/html'});const a=document.createElement('a');
a.download=c.toUTCString()+
' - '+decodeURI(location.href).replace(/\*/g,'��').replace(/\//g,'�^').replace(/:/g,'�F').replace(/:/g,'�F').replace(/\\/g,'�_').replace(/\|/g,'��').substring(0,123)
+'.html';a.href=(URL||webkitURL).createObjectURL(b);a.click();})(); >>786
���X�̈�s�����ʼn��s���ꂽ���ǁA�����u"+"�̑O�̉��s�v�œ�����Ǝv������
���s�����������
���s�S������Ă������悤�ɂ��Ă��邩�炻��ł��ǂ��� �ŋ߂�archiveis�͂����ʖڂ���
�҂����Ԓ����Ȃ��������ɍ����͊����߂邩��擾����܂Ƃ��ɍs���Ȃ� ����͋���o�R�ł��������Ǎ����͉�����Ă����߂� �ǂ����܂��V���|�[�c�̂͂Ȃ��Ȃ�ł��傤 ���������V���|�[�`���ł���� Archive.is��牽���̘b���Ă�l�̓E�F�u����X���ɍs���Ă�
IA�̘b�̒��ő��T�[�r�X�̘b�肪�o��͕̂����邪���̏ꍇ�͂�������Ȃ����� pixiv���č��A�[�J�C�u�ł��Ȃ��H
�̂͂ł��Ă��C�����邯�� >>793
������SPN�ɓ˂�����Ŏ����Ă���
�ۑ������̕\���͏o�邯��Wayback���̂��s����Ȃ������A�A�[�J�C�u���\���ł�����o���Ȃ������肷����
�X�N���[���V���b�g�̕��͂Ƃ肠�������Ă�����A�����炭���ʂ̃A�[�J�C�u�̕������Ă��Ȃ����Ǝv��
�܂Ƃ߂�ƁA�����炭�A�[�J�C�uIA�����s���肾���� �r�����M���Ă��܂���
�܂Ƃ߂�ƁA�����炭�A�[�J�C�u�͏o���邪IA�����s����Ȃ����ŏ�肭�s���ĂȂ��������Ǝv����
���ƃA�[�J�C�u���ɓ��{���O�̉������A�N�Z�X����̂ŁA�p��Ńy�[�W�փ��_�C���N�g�����_�ɂ����� �����ł́A����̓��e�Ɋւ���b�͔����ŁB
ttp://web.archive.org/web/20190717122047id_/video.twimg.com/ext_tw_video/1146432912117489664/pu/vid/1280x720/DhxeMNq_qWw8iakm.mp4
���ʂɃA�N�Z�X���|���Ă��A�ǂ������� 200 OK �ł͂Ȃ� 206 Partial Content ��Ԃ��Ă���B
���R�A�Ԃ��Ă͂����Ȃ������Ȃ̂ň�ʓI�ȃN���C�A���g�ł̓_�E�����[�h�ł��Ȃ��B
���X�|���X�w�b�_�������
X-Archive-Orig-Content-Range: bytes 0-3091160/3091161
�Ƃ����s������̂ŁA����N���C�A���g�� Internet Archive �ɓ��Y�t�@�C����
�ۑ�����悤�v�������Ƃ���
Range: bytes=0-3091160
�̎w�肪���̂��t���Ă��܂��Ă��āA���ꂪ���̂܂� IA ���� video.twimg.com �ɑ����A
�͈͎w��t�����N�G�X�g�Ƃ��ď������ꂽ������ IA �ɃA�[�J�C�u���ꂽ�A
�Ƃ������Ƃ��Ǝv���B
�������A�����ǂ��������͈͎w��t���̃A�[�J�C�u�v���Ȃo��̂��˂��B ���ؗp�����Ȃ��Ēf��o���Ȃ��̂Ŋ��S�ȗ\�z�����AHeritrix�������̐ݒ�̂����Ȃ̂�����
Save Page Now�o�R�Ŏ擾�ł��铮��̗e�ʂɂ��炩���ߐ����������Ă����Ȃ����낤��
����͂��Ȃ�ʐM�ʂ�H�����A�������̎擾����������F�X�Ȗʂő�ςȎ��ɂȂ邾�낤����A
�����������~�b�^�[�����݂��Ă��s�v�c�ł͂Ȃ��Ǝv�� ���[��pixiv�ۑ�����ƂȂ����ǂ����Ă��ۑ������̂��^�����ȃy�[�W�ɂȂ��Ă��܂�
�Ȃ����낤 >>801
����̓��o����
2019�N������10�y�^�o�C�g�A1996�N�`2011�N�ɕۑ������ʂ�2�{���̃f�[�^���lj����ꂽ�Ƃ��c
�������t���W�߂��Ƃ���ł���Ȗc��ȗʂ������Ƒ��������Ă����Ⴖ��n�ɂȂ�͖̂ڂɌ����Ă�C���c
������������Ȃ��Ēu���ꏊ������Ȃ��Ȃ肻��
AI�g���ē�����������قƂ�Ǖω��̖����y�[�W�͏����Ă����Ƃ����Ȃ���
���Ƃ͌��ǃN���[������͈͂����Ɠ����Ɍ��炷�����Ȃ��Ȃ�C������
����ƃN���E�h�g���ĂȂ����Ă��Ƃ͂����̃T�[�o�[���Ύ��Ƃ��ɂȂ�����S���p�[���Ă��Ƃł�����|����
Google�݂����ɐ��E���ɉ��\�ɂ��o�b�N�A�b�v�Ƃ����O�Ȏ��͂��ĂȂ��������� save now�@�\�t�������낱�̃X���ł����v�ȂƂ͌����Ă���� 10PB�i10000TB�j���������^ �ǂ����̕x�����|���Əo���Ă���˂����� �s����Ȃ̂Ɋ�t�Ȃł��Ȃ��Ƃ������Ă�l���ǂ����Ō����������A�z���Ǝv��
��t���Ȃ��Ƃ����Ȃ������炱���s����Ȃ� �t����
�s���肾���炱����t���Ȃ��Ƃ����Ȃ� �lj��f�[�^�ɍی��͂Ȃ�����̈�r
��20�N���T�[�r�X�ł͂Ȃ��� �܁[����������ň��̏ꍇ����1996-2011�̂����c���R�X�p���������� �q�ϓI�Ɋ��������ꍇ
�������c�����l��K�v��������Ǝv�����炨�������͊�t���邾�낤��
�r�炵�݂����Ȃ��Ƃ������Ă��݂܂��� �����Ƃ��r�炵�݂����ł͂Ȃ����A�����Ƃ��q�ϓI�ł��Ȃ� �m���ɍr�炵���ۂ��Ȃ��������ɋq�ϓI�ł��Ȃ�
���P���Ƃɂ��Ă�����Ȓn���Ȃ��Ƃɋ��g���x���͂��Ȃ�����
�ꂵ��ł�l���������邱�ƂɗD�悵�ċ����g���ƍl����̂��Ó� �c�C�b�^�[��100�������l�����ɉ^�c�������˂���̂͂ǂ����낤�� ������v�v���J�����Ă��Ċ�t���悤�Ƃ��Ă݂����NJ�t�̎�t����Ƀ��[�����Ė₢���킹����ĕ��͂��\������Ēe������ςȂ�
�C�O�̏Z���̏������̒ʂ�Ƀt�H�[���͖��߂����A�J�[�h�̔ԍ����������Z�L�����e�B�R�[�h���S���m�F�������ǎt���Ă��炦�Ȃ�
���ʂ̃N���W�b�g�J�[�h����̊�t�����t���Ȃ����Ă�Ȃ�A���{��ł̈ē���p�ӂ��ĂȂ��s�e�������ɗ��邵��t�͖������� �W�Ȃ�����archive.is�̕���YouTube�̃R�����g���ۑ��ł���悤�ɂȂ��Ă��
�̂��ł��Ă����ǂ������N���͂ł��Ȃ��Ȃ��Ă����������
Internet Archive����YouTube�͕ۑ��ł��Ȃ����� V�v���J�͌���������͊��S��VISA�N���J�Ɠ����ɂ��������Ȃ��͂� ����V�v���J���g����Ƃ��ǂ��ɂ������ĂȂ�����
PayPal�A�J�E���g�����Ă�Ȃ炠�炩���ߓ������Ă�������Ŏx�������͏o����Ǝv����
�ނ���N���W�b�g�J�[�h�Ɠ����悤�ɂ���V�v���J���g����Ǝv���Ă�����Ԉ���Ă邼 �l�I�Ȍo���ŗ��R�͕�����Ȃ����ǁA���O�Ƃ̎x������V�v���J�g���Ə�肭�����Ȃ��ꍇ������Ȃ�ɂ���
PayPal���p���������m�� >���{��ł̈ē���p�ӂ��ĂȂ��s�e�������ɗ���
�����g����ȓz���ȁAWikipedia���Ⴀ��܂��������܂ł��郊�\�[�X���]�T����������낤��
��t�֘A�̈ē����S�����݂��Ȃ�������s�e�ƌ����邾�낤������������ł��Ȃ����A
Google�|��g���Γǂ߂���̂�s�e���Ƃ������̂͂�������
5ch�͎g����Ȃ�Google�|����g���]���X�͖����̂ȁA���� �e�q��������̍L�����j�Q����悭����\�}������ ��t�̂��肢�����ōς܂��Ă��镪�@���Ƃ��Ă͂����ԗǐS�I
�{���̏@���ƈ���Ė����Ȃ����獢�邯�� Internet Archive�ȊO�Ńl�b�g���̕ۑ������ɐϋɓI�ȂƂ��낪�S�R�����̂�
���쌠�Ƃ��̖������邪����������ǂ͂�������ēV���w�I�ȗʂ̏���X�����ɑ��������Ă����č���̂��\�z�ł��邩��Ȃ낤��
���ꂾ���ɂ����Ċ撣���Ă��邱���͋M�d�ʼn�����������
�{���ɂǂ�����낤��
���͂⌻��ł͂قƂ�ǂ̏�l�b�g�ˑ���ԂȂ̂�
���������������Ȃ�����l�ނ̗��j�Ō���̏���������ۂ�����Ă��܂��ċn�тɂȂ��đ呹�����낤 AWS�Ƃ�Google�Ƃ�������Ă���ˁ[���ȁ[ Google�͂�낤�Ǝv���Ώo���邾�낤����
�܂����Nj��ɂȂ�Ȃ����Ă������ɂԂ��������˂��E�E�E >>825
�����������ɂȂ������_�Ŗ��B
�t�F�A���[�X�̔��e����O��āA�A�[�J�C�u���̂���@�R�s�[�ɐ��艺����B ��c���c�̂����炱��Wayback Machine�Ȃ�ăO���[�ȑ㕨���^�p�ł���킯��
Google����t������Č`�ɂ���Ζ@�I�ɂ̓Z�[�t��������Ȃ����AGoogle�̋���Internet Archive�ɂ܂œ�������@���Ƃ͕ʂ̖��Ń}�Y�����ƂɂȂ肻�� �����AInternet Archive�̃T�[�o�[�̑O�Ƀs�J�s�J�̃����h�Z���� �����h�Z���͈������f���ł����p��卷�Ȃ����Lj�����HDD��SMR�����c outlinks��Saving�̂܂~�܂�
���q�����̂� ��t�̂��肢���o�n�߂�O�ォ�炸����outlinks�͕s���� �p�����}���ق�WebCite�͂ǂ��H
IA�ȏ�ɕn�����Ă邩�c WebCite�@�͐V��������͎��Ȃ��̂ł͂Ȃ��������ȁH ���S�Ȑڑ����ł��܂���ł������ďo�� �������ăA�����J���{�Ƃ������p���ĂȂ����������H�����ƂȂ����炨�̂������o���ĕی삷���Ȃ����� �����܂Ŋy�ϓI�ł��Ȃ�
��c���̐}���ق�A�[�J�C�u�c�̂͂ǂ�����̓����悤�ɍ�����ɒ��ʂ��Ă�
���E�ő�K�͂̐}���قƂ��ėL���ȃj���[���[�N�����}���قł����A�����J��Ɏl�ꔪ�ꂵ�Ċ�t�����߂ċ삯�������Ă��� ��t600���h�����S�[���ɂȂ��Ă邯�ǁA�����ł���Ă������Ȃ̂��ˁH
�Ƃ肠����5�h������������ ������͊��͂��邯�Ǔ��ʂ͂��ꂾ���������čs�������A���Ă��Ƃ��Ǝv�� �ŋ�Twitter�̂ǂ�Ȃ�����Ƃ�������Ȃ������˂����c�C�[�g���Ȃ��悤�șꂫ�ł��S�đ����ɖԗ��I�ɂ����ɕۑ�����Ă鎖�ɋC�Â���
�����p���N����� ���ׂ��Ƃ���>>731�̔��\����ArchiveTeam�������Ă�݂�������
https://archive.org/details/archiveteam_twitter
�ꉞ�u�̐l�̃A�J�E���g��ۑ�������@��������܂ō폜�����v��Twitter���͌����Ă邯�ǁAArchiveTeam�͂���Ŗ�������悤�ȑg�D����Ȃ��� ����Ԃ��u�ۑS������@������������폜�J�n�����v���ĈӖ��ł�������炻���A�[�J�C�u����� Twitter�ƘA�g���đS���JTweet�f�[�^��IA�ɓn���Ă����Έ�Ԋy�H ���̂܂���Google�ł̃��A���^�C���������ĊJ���Ă���� �Ƃ肠�����A�[�J�C�u���ꂽ��url���킩�炸
��x�Ɣ��@����Ȃ������̉��Ɖ����Ă�f�[�^���������낤 ���̃A�[�J�C�u�ʂőS�����������琦�܂������ɂȂ肻�� �S������Ȃ��ăh���C��+<title>+���t�͈͂ł��������ɗ����ǂȁc �����G���W���̉^�p�݂����ɁA��ɍ����t�����Ă�����Ȃ��́H�m��� �܂������Ă�݂�����
�S�R�擾�ł��Ȃ� �����e��ʂɂȂ�����
�ʂ����č���͉����Ԃ�����̂�� We're sorry ? something's gone wrong.
Our team has been notified. punycode�\�L��URL�̋��������������Ȃ��
���Ƃ��Ȃ�Ȃ��̂��� 600���h���͊m�ۏo�����̂���
����paypal��ʂ��Ċ�t��������ē��{�ł͈�@�����A�ǂ��ċK��ᔽ�ŃA�J���ł������Čx�@�����ɂȂ�ˁH >>862
https://donate.wikimedia.org/wiki/Problems_donating/ja#%E3%81%AA%E3%81%9C%E7%A7%81%E3%81%AE%E3%83%9A%E3%82%
A4%E3%83%91%E3%83%AB%E3%81%A7%E3%81%AE%E5%AF%84%E4%BB%98%E3%81%8C%E6%8B%92%E5%90%A6%E3%81%95%E3%82%8C%E3%81%9F%E3%81%AE%E3%81%A7%E3%81%99%E3%81%8B%EF%BC%9F >>863
������Â��Ȃ����H
���͕��ʂɎt���Ă邼 ttp://2chan.tv/jlab-long/s/long200107161313.jpg >>865
�X�|�[�c��m�̃A�[�J�C�u�p�x��������
������̐l�����Ɏ������ł��n�߂��̂� �l�̎��R�Ƃ͂��������ނ�M�S�ɂ����Ă���̂� �܂��A�[�J�C�u�Ƃ����ʂł�
�������������ŔM�S�ɂ���Ă����l���������������̂�
�Ȃ�ł���ɍS���Ă�̂��͒m��� ���̕ӂ��A�����}�E�X���|�`�|�`���邾���̐l��
�����Ŗ����l�Ƃ̈Ⴂ�Ȃ̂��ƁB
PC���g�����P���J��Ԃ��̒�^��ƁA�����������Ă݂���
���ꂪ�����Ŏ��ꂽ�Ȃ�Ęb�����邭�炢������˂��B ����ɂ��Ă�����IP���炱��ȗ��đ����Ƀ��N�G�X�g����Ȃ��͂�����ȁA�����Œe���ꂻ���Ȃ��� ��m�����o�O�H
��m
ttp://2chan.tv/jlab-long/s/long200108162357.jpg
�����X�|�[�c
ttp://2chan.tv/jlab-long/s/long200108162444.jpg F5�A�łŖ��ʂɕ��ׂ����܂����Ă鈫���r�炵�ɋ߂��� Base64�G���R�[�h�ʼn摜���ߍ���ł�T�C�g����������������ۂ��H
https://web.archive.org/web/20200109161142/http://up-img.net/img.php?mode=gif&id=2358 first����Ȃ�url�̂͒��߃A�[�J�C�u����x�T�o�߂��Ȃ���NG�̐����݂�������̂ɂ�
���o�߂��ƗL���Ŏ擾�ł���悤�ɂ����^�_�Ŕ��擾���₪���H�̂Ƃ�������}�V�ɂȂ� >>849
5ch�̉ߋ����O�ɓ\���Ă���ς݃T�C�g��URL�����Ŕ��@������c
>>869
�蓮�����AWikipedia�̕ҏW�L���Ƃ�Yahoo�j���[�X�Ƃ�TLS1.2�����̃u���E�U��[�����璼�ړǂ߂Ȃ��Ȃ����y�[�W��ǂނ��߂ɕۑ����Ă���B
�����is�ɂ�����Ă邪�A�[�J�C���T�[�r�X�܂�TLS1.2�K�{�Ɏd�l�ς����Ȃ����Ƃ��F��B Yahoo!�j���[�X��wayback����ƃg�b�v�y�[�W���A�[�J�C�u����� Yahoo�j���[�X�͂��������Ŏ�����A�[�J�C�u���d�ˎ�肷��Η���Ȃ������������B yjsecure.js��NG����Γ]������Ȃ��B�U�X���o adblock�̏ڍאݒ�̃}�C�t�B���^�[���X�g�Ɂu*/yjsecure.js�v��o�^����adblock�L��
�Ɛݒ肷����������H ���������͎擾���Ă��Â��A�[�J�C�u�Ƀ��_�C���N�g����Ė{���Ɏ擾���Ă��邩�m�F�ł��Ȃ��悤�ɂȂ��Ă���̂Œ��� 5������URL�A�[�J�C�u�ł��Ȃ��Ȃ��ĂȂ��H�����O����ł��Ȃ����� �Ȃ����̊�����͂Ȃ���5��������A�[�J�C�u�ł��Ȃ��Ȃ��Ă��܂���
����ς�����ڑ�����������vpn���܂����艽�x�����g���C���Ă݂���F�X������牽�Ƃ��ł����X�������邯�ǂł��Ȃ��X���͂ǂ�����Ă��_�����c�� ���傤���Ȃ�����sc�̃X���ŃA�[�J�C�u���Ă� ������������ϒ��q�����ȁ`�Â��A�[�J�C�u�m�F�o���Ȃ� �܂�5�����ۑ��ł���悤�ɂȂ�����
�Ȃ����낤 pc����̗��p�Ȃ̂Ɏ��Xsp�p�y�[�W�ɂȂ�̂��n���ɃX�g���X �܂��A�[�J�C�u�ł��Ȃ������悭�N����悤�ɂȂ���
5���������Ȃ��đ��̃T�C�g�ł��ł��Ȃ������肽�܂ɂł�����c
�s����Ȃ̂��� ����3~4���̓A�[�J�C�u�܂Ƃ��Ɏ擾�ł��Ȃ��Č�������
�E�F�u�A�[�J�C�u����Ȃ��Ɛ������擾�o���Ȃ�������̂ɁE�E�E SavePageNow�̸�����߰�ނ��p�ɂɕ\������� �X�e�[�^�X�R�[�h200�ȊO�Ń��g���C����X�N���v�g�g��ŕ��u���Ă���400captures�Ƃ��ɂȂ��ď��Ă� �N�b�V�����y�[�W�A��ʂ͓�����URL�ɓ��t�������Ă��Ɠ����ĂȂ����������ۂ��B Internet Archive �̃t�@�C���A�b�v���[�h�@�\�A������g����
���[�U�o�^�Ɏg���Ă��郁�[���A�h���X���R���Ȃ��B
��Ƃ��Ă��̃t�@�C����������B
https://archive.org/details/Pbtestfilemp4videotestmp4
�E���� SHOW ALL �̃����N����t�@�C���ꗗ���J���A
�t�@�C���������� _meta.xml �̃t�@�C�������Ă݂�ƁA
<uploader> �v�f�̒��Ƀ��[���A�h���X���L�ڂ���Ă���B
���̃y�[�W�ɖ߂�AUploaded by �Ŏ�����Ă���A�b�v���[�h�҂�
�v���t�y�[�W�ɓ����Ă݂�B
�v���t�̃A�o�^�[�摜�� IA �ɒ��ڃA�b�v���[�h���邱�Ƃ��ł��邪�A
���̐l�͂�����s���Ă��Ȃ����� Gravatar �̉摜���Q�Ƃ���Ă���B
Gravatar �̉摜 URL �ɂ́A���[���A�h���X�� MD5 �n�b�V���l���܂܂��B
��� XML ���瓾�����[���A�h���X�ɂ��� MD5 ������Ă݂�ƁA�o���̒l����v�B
(�啶�������܂ރA�h���X�͈��̉��H���K�v�����A���̗�ł͖��W�B)
�܂�AXML ���瓾�����[���A�h���X�̓��[�U�̓o�^�A�h���X�ŊԈႢ�Ȃ��B
�P�� IA �Ƀ��[�U�o�^���s���ăv���t�������Ă��邾���̏�Ԃ����
�F�X�T���Ă݂����ǘR����ۂ����̂͌�����Ȃ������B
�����A�o�^�[�摜��������Ԃ̂܂܂��ƃ��[���A�h���X�̃n�b�V���l��
����̂ŁA�������瑼���ŕR�t������Ă��܂����Ƃ͂���Ǝv���B >>897
����͖{�l�̃A�h���X�ŊԈ���ĂȂ��A���N�O����Z�L�����e�B�ʂŎw�E����Ă�B
�O�̂��߂Ɍ����ƘR��Ă��Ȃ��āA�A�[�J�C�u�̏ؖ��ׂ̈ɋL�ڂ��Ă�Ǝv�����ǂˁB
�u�A�[�J�C�u�v�ł���ȏ㉽�炩�̖{�l�m�F�͕K�v�Ȃ̂ŁB >>898
��͂���o���������B
���^���Ƃ��āu�N���A�b�v���[�h�������v���L�^���Ă����K�v��
����͉̂��邪�A���������`�ŏo�Ă��܂��̂́u�R���v�ƕ\���������Ȃ��B
�V�X�e����Ń��[�U���𖼏�点�Ă����Ȃ���A�ǂ����ă��A�h�ŋL�^���Ă��܂��̂��B
���[�U���́u��x�g�p�������O�͓�x�ƍė��p�����Ȃ��v
(��x�ς����猳�ɖ߂����Ƃ���ł��Ȃ�) �Ȃ�ă��b�N���|�����肵�Ă���̂�
������̕����d�v�Ȏ��ʎq�Ȃ̂��Ǝv�������ǁA����������ł͖����ȁB >>900
Browser crashed visiting URL
chrome�g�������A���������ł悭����悤�ɂȂ����ȁB
���Ƃ����ĉ�����������A��ɂȂ��āu���ł���ȑ�ʁH�v���ĂȂ肻��������A
�}�[�L���O���o�ŁA1�`2��ŗ��߂邵���Ȃ��̂��B �ŋ߂ǂ̃T�C�g���S�R�A�[�J�C�u�ł��Ȃ��c tamper����grease�����Ń��g���C��������悤�ɂ�������A�[�J�C�u����邵�c �A�[�J�C�u�o���ĂȂ��悤�Ɍ����Č���`�F�b�N���Ă݂�ƃA�[�J�C�u����Ă����Ă̂͂���
�`�F�b�N���Ă݂� /save/�ŕۑ�����api�Ŋm�F���Ď��ĂȂ���������������ۑ� �ŋ�API�����f���x���ĂȁE�E�E
�܂��������ŏd���Ȃ�̂͂����̎������A�C���ɑ҂��ǂ� save outlinks�Ƀ`�F�b�N�����ĕۑ����悤�Ƃ���Ɓ��݂����ȃG���[�ɂȂ�ȁB
ttp://2chan.tv/jlab-long/s/long200126211024.png
�܂��A������9������18���O�ʂ܂őS���ۑ��������Ȃ��������炻����̓}�V�����ǂ��c save outlinks�Ȃ��ł�Job failed
26������ ���T�C�g�ɃA�N�Z�X�ł��Ȃ��Ȃ��Ă� �ȂʔK�o�R�ŕۊǂ�����ƌ�ŃA�[�J�C�u��������Ă�悤�ȋC�����邯��
�C�̂������ȁB
 Twitter�̎d�l�ύX�̂������A�[�J�C�u�o���Ȃ��Ȃ��Ă��܂��� save outlinks�Ƀ`�F�b�N����ĕۑ�����������N�悪�L�^�ł���
Twitter�̎d�l�ύX�̂������A�[�J�C�u�o���Ȃ��Ȃ��Ă��܂��� save outlinks�Ƀ`�F�b�N����ĕۑ�����������N�悪�L�^�ł���
�����ŃT�[�r�X�I������T�C�g�Ȃ�ŗ��ށc �ۑ����ɃG���[���ۂ��\���͂Ȃ�������
save�����y�[�W���̂͂������f����Ă邪�A���̃����N�悾������Ȃ��̂Ń^�C�����O���Ƃ��Ă���
���Ƃ����Ă������@���̂����ׂɂȂ邵��߂��� �����ɂ������������save outlinks�Ƀ`�F�b�N����Ă�̂ɂ��̃y�[�W�����ۑ����ĂȂ�orz Save error pages������save outlinks�`�F�b�N�͗������Ȃ��H�H >>917
IA�����Ȍ`���ɂȂ������疳�����Ǝv��
download elements������Ɖ摜�Ƃ��͎��Ă�݂��������E�E�E �ŋߖ{�C�ۑ����Ă����Ƃւ̈ӎ�Ԃ��Ȃ́H Twitter��megalodon��Archive.today�̕����܂����₷���C�����Ă���
>>918
���Ȍ`���ɂȂ������Ăǂ��������ƂȂ��
�ڂ��������Ă���Ȃ��� today�̕����ƕ��ʂɎ����>Twitter
�䂾 save outlinks�������Ȃ��Ă�c
ttp://2chan.tv/jlab-long/s/long200203211629.png >>923
�T�C���C��������ď����Ă�� Wayback�@�̓T�C���C���i���O�C���j���Ȃ���
�X�N���[���V���b�g�����Ȃ��d�l�ɉ��ς��ꂽ�B
���t�[�j���[�X�̋�������Ƃ��ɂ͒��ӂ��悤�B >>927
�������炢�O�͂����ł͂Ȃ������B Firefox �� general.useragent.override ��
Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; .NET4.0E; .NET4.0C; .NET CLR 3.5.30729; .NET CLR 2.0.50727; .NET CLR 3.0.30729; Tablet PC 2.0; rv:11.0) like Gecko
�Ɠ���Ă���Ă݂���A����Ȋ������B
http://web.archive.org/web/20200207033245/twitter.com/TwitterJP/status/1224802584650584064
https://twitter.com/5chan_nel (5ch newer account) >>930 �� User-Agent�A���܂��E�����̂����̕������������Ȃ̂�
Internet Explorer �Ɣ��肳���悤�ȓ��e�Ȃ牽�ł��ǂ��Ǝv���B �ŏ�����general.useragent.override.web.archive.org�ɓ�����ςȂ��ł������̂��� �Ȃ���Internet Explorer�o�R�łȂ���Twitter�̃A�[�J�C�u�����Ȃ��̂� �ʂɉ��̂��ł��Ȃ����Ǎ���IA�͂��������̂ǂ�����̂��� �Ȃ�Twitter�������Ɏ���悤�ɂȂ��Ă��
�v�]�����������낤���H ���������ă��[�g�p�X�̃����N���Ȃ��̂� �A�}�]���͖��W
�e�X�g�X���ƊԈႦ�Ēlj����Ă��܂������� �Ȃ�Too Many Requests�̔��肨�������Ȃ����H
���炩�ɏ���ɒB���ĂȂ��̂Ƀu���b�N������ ��������茵�����Ȃ����̂ł́H������Ȃ����� �v���Ԋu���Z������ƒe�����B
����������T���o���ĂȂ��Ă��Ԃ��Ă���B �C�����������炢�������������
���̂����ɂ��낢�����Ă����ׂ��� >>941
���肪�Ƃ�
��������A�[�J�C�u���̂������Ă��������蒼�����猩�ꂽ �܂Ƃ߂ĂƂ�������S�������Ă�c 20�N�ȍ~�ɕۑ������̂������Ȃ��̂������Ă�̂��m���
�Ō�ɕۑ������̂�2019�̂��̂ɂȂ��Ă�� �����ĂȂ��̂������
�������Ń����e����������Ă邾���� ���s�̎���������̂��ȁc
����̊m�F�ŃJ�����_�[���J�������ɗΊۂ̃y�[�W�͐�Ɍ���Ȃ��d�l�ł���?
�����Œ��ׂ���Ί�=���_�C���N�g�͂킩�����̂ł����Ίۂ�������@��������Ȃ��ď������݂܂���
���S�҉߂��鎿��Ő\����Ȃ��ł� �\����Ȃ����u�Ίۂ̃y�[�W������v���Ă̂��������������̂��悭������Ȃ�
���_�C���N�g��̃y�[�W��Wayback Machine�ɕۑ�����Ă��猩��邵�A�ۑ�����ĂȂ������猩��Ȃ��A�Ƃ����d�l�̂͂������� Yahoo�݂����ȃy�[�W�̘b�Ȃ�
JavaScript����������Ό����͂� >>953
�_���݂����ł�
�X�}�z�ʼn{�����Ă�̂ł���javasScript���I�t�ɂ��Ă����ɕω��͂���܂���ł���
���݂ɒ��ׂĂ���̂�bekkoame�Ƃ����T�C�g�ł� ���_�C���N�g�����̃R���e���g�{�f�B���������Ƃ��A
����ȃj�b�`�Șb���Ǝv�������ǂǂ����Ⴄ�悤���E�E�E�B
�����������_�C���N�g���ǂ��������̂��A����Ҏ��͗�������Ă��܂����B
���� URL ����āu����ɂ���������v�Ǝw��������̂ł�����A
���_�C���N�g���̂ɂ���ȏ�̓��e�͂���܂���B
Internet Archive �̃J�����_�ŗΐF�ŕ\������Ă���A�܂�
�N���[�����Ƀ��_�C���N�g���Ԃ��ꂽ�|�L�^����Ă���A�[�J�C�u��
�J���ƁA���b��ɂ��̓������_�C���N�g��Ƃ��Ď�����Ă��� URL ��
�A�[�J�C�u�̓ǂݍ��݂��n�܂�܂��B
�����烊�_�C���N�g��Ƃ��Ď�����Ă�������ƌ����Ă��A���F�͕ʂ� URL �ł��B
���Y URL �� Internet Archive �ɃA�[�J�C�u����Ă��邩�ǂ����́A
���� URL ���A�[�J�C�u����Ă��邱�ƂƂ͂��܂�W������܂���B /save/�ł͂Ȃ���/web/2/�ł�Too Many Requests���o��悤�ɂȂ������ۂ��� Summary�^�u������h���C���Ɩ����h���C���̈Ⴂ���ĉ��Ȃ�H
���N�o���Ă�̂ɖ����̂�����A���N���x�ł���h���C�������邵
�擾�����Ė�ł��������������Ȃ��E�E�E �{���ň�U�A��������Ă�����Ƃ��x�~���܂��B �摜�Ƃ��A�[�J�C�u����Ƃ��̃v���O���X�o�[�������H �Ȃۑ��ɂ��������Ԃ�������...
�ǂ��Ȃ��Ă� The same snapshot had been made 38 seconds ago.
������o�Ă�̂�API�ł͕ۑ�����Ă��Ȃ����ƂɂȂ��Ă�
/save/�ł��ۑ��ł��Ȃ����A�ł���͕̂ۑ��ς݃A�[�J�C�u�̉{�������� >>965
���܂ǂ��A�S�E�̃X�e�}�����l������Ƃ́I ����A�[�J�C�u���Ă���ɐ����Ԍ�Ɋm�F�������̂�
�����ɂȂ�����A�[�J�C�u����Ă��Ȃ����ƂɂȂ��Ă�
��蒼������First Archive�ƂȂ��Ċm�F���Ă������ƃA�[�J�C�u�ł��Ă�̂���
�����͏����Ă����� >����A�[�J�C�u���Ă���ɐ����Ԍ�Ɋm�F�������̂�
>�����ɂȂ�����A�[�J�C�u����Ă��Ȃ����ƂɂȂ��Ă�
https://web.archive.org/�̎��Ȃ牴���܂������������
http://archive.fo/�͖��Ȃ��������ǁA��ӂ���g���Ȃ��Ȃ��ĕۑ����̉�ʂɂȂ����܂I���Ȃ� �y�ۑ��E�L�^�z�E�F�u�A�[�J�C�u���� Page.01
2020/02/25(��) 23:55:53.96 ID:jlsY//Cy0
>>345
Internet Archive�̓A�[�J�C�u���s�p�N���[��(Heritrix)��
�ۑ������A�[�J�C�u�̐�p�r���[��(Wayback)��g�ݍ��킹�ē����Ă��ŁA
�ۑ������A�[�J�C�u���T�[�o�s���ňꎞ�I�Ɍ����Ȃ��Ȃ��ĂĂ��A
�A�[�J�C�u����������Əo���Ă���̂������Ȃ�������悤�ɂȂ� cube news�̒P���ȍ\���Ȃ瓮����ꏏ�ɕۑ��ł�����ۂ� ���q�����ł��˂��B
 503�����o�Čq����˂��Ǝv������܂������e�� API��������
503�����o�Čq����˂��Ǝv������܂������e�� API��������
��̂̃L���v�`���������Ƃ���̂ɁAAPI�ł͕ۑ�����Ă��Ȃ����ƂɂȂ��Ă�B �R���i�̂����ŃA�N�Z�X�������Ă�ˁH IA���L�̃w�b�_���\������Ȃ��Ȃ��� >>979
Internet Archive�������ŐF�X�Ȗ{�����J��������A�N�Z�X�����ăL���p�I�[�o�[�����\������� >>983
��
�e���v���̓�� Q&A �͉i�v�ۑ��ł���w
2011 �N�Ă� UTF-8 ���ȍ~�Ӗ��𐬂��Ȃ��Ȃ��Ă܂����B >>984
�e���v���͂Ƃ肠�������̂܂܂ɂ��������ł�
4�X���ڈȍ~��Q&A�����Ɛ������Ȃ��Ă� �C���^�[�l�b�g�E�A�[�J�C�u�̖����d�q���Б݂��o���ɒ��Ғc�̂��R�c
https://hon.jp/news/1.0/0/29039
�C���^�[�l�b�g�E�A�[�J�C�u�iInternet Archive�j�͐挎24���A
140������E�u�b�N���ǂ߂�uNational Emergency Library�v
���I�[�v����6�����܂ł��߂ǂɃ��[�U�[��1�l10���܂Ŏ��
�ǂނ��Ƃ��ł���悤�ɂ��������Ғc�̂����̐����グ�Ă���B https://web.archive.org/web/20200324005017/http://www.mynewsjapan.com/
> ���݃����e�i���X���ł�
> ���݁A�A�N�Z�X�W�Q�s�ׂɂ���āA�T�C�g�ɃA�N�Z�X�ł��Ȃ��ƂȂ�A
> ���s�ւ����������Ă���܂��B���҂����Ɩ��W�Q�����Ă���͗l�ł��B
> �x�@���T�C�o�[�ƍߑ��ǂ��Ɛl��ߕߎ���A�ڍׂɂ����܂��B
> ���S���������߁A�ꎞ�I�ɒ�~���āA���S���m�F���Ă���܂��B
> ��̂����A���X�ɕ������܂��̂ŏ��X���҂����������B
> My News Japan ���N�ȏ�O�ɕۑ�����Ă��y�[�W��ۑ����Ȃ������牽�̂�First Archive�ɂȂ��� ���X���������Ă��邩�炱�����̃X���͖��߂悤 ����
���q�����̒���Ȃ��˂�
�R���i�ŃX�^�b�t���x��ł�낤�� ���̃X���b�h�͂P�O�O�O���܂����B
�V�����X���b�h�𗧂ĂĂ��������B
life time: 1287�� 23���� 4�� 22�b 5�����˂�̉^�c�̓v���~�A������̊F���܂Ɏx�����Ă��܂��B
�^�c�ɂ����͂��肢�������܂��B
��������������������������������������
�s�v���~�A������̎�ȓ��T�t
�� 5�����˂��p�u���E�U����̍L������
�� 5�����˂�̉ߋ����O���擾
�� �������K���̊ɘa
��������������������������������������
����o�^�ɂ͌l���͈�ؕK�v����܂���B
��300�~���瓽���ł��w�����������܂��B
�� �v���~�A������o�^�͂����� ��
https://premium.5ch.net/
�� �Q�l���O�C���͂����� ��
https://login.5ch.net/login.php ���X����1000���Ă��܂��B����ȏ㏑�����݂͂ł��܂���B













