Internet Archive総合 (web.archive.org) #2 ©2ch.net
レス数が1000を超えています。これ以上書き込みはできません。
atwikiはFirefox 52にトラウマでもあるのか ふむふむ
http://web.archive.org/web/20181211102115/www26.atwiki.jp/gcmatome/pages/1017.html
Mozilla/6.0 (Macintosh; Intel Mac OS X 10.13; rv:60.0) Gecko/20100101 Firefox/60.0
>>320
/save/ を叩いた時なんだけど、もし点数方式で判定するなら
◎ IP は archive.org の取得用サーバ群の中の何れか一つが使われる。
米国の IP であること、また名前に www が入っていることは加点対象になる可能性あり。
同じ IP からの繰り返しアクセスも加点対象になる可能性あり。
◎ User-Agent を含め、リクエストヘッダはクライアントのものがそのまま転送される。
古いブラウザを使っていると加点対象になる可能性あり。
◎ さらに Via: HTTP/1.0 web.archive.org (Wayback Save Page) が追加される。
これは間違いなく加点対象。
この辺が総合的に判断されて弾かれているのだろう。
保存に成功することもあるので、Wayback Machine だからと言って一律に判断しているのでは無いと思う。 そもそも閲覧回数が多いのってスパムっていうのだろうか
いや本筋と関係ないな 先週くらいから、上のほうに寄付金募集のバナーが出るようになったな。
しかもIEだと、右上の「×」をクリックしても、どうしたわけかバナーが消えない。
この募集は本気だな。 将来見たくなった時のためにそれの魚拓も撮っといてくれ ウィキのコーヒー1杯みたいな洒落たジョークじゃないと金が集まらんぜ http://web.archive.org/web/20181223223511/https://www26.atwiki.jp/gcmatome/pages/2928.html
http://web.archive.org/web/20181223223509/https://www26.atwiki.jp/gcmatome/pages/686.html
またスパム扱いされてる 221 名前:名無しさん@お腹いっぱい。[] 投稿日:2018/12/22(土) 16:36:12.78
こういう海外サービスを発見した。
まだちょこっとしか試していないが。
Archive.st
https://archive.st
Time Travel
(ブラウザから「このサイトはやばいかもしれない」
という警告が出たが、おそるおそる行ってみると
特にまずいことはなかった)
http://timetravel.mementoweb.org Wayback Everywhereってアドオン使ってるけど他に便利なのないかな 以前のいつかと同じく、18年12月29日深夜から現在に至るまで取得したアーカイブの消失が起きている
注意されたし 名前上がらないけどWebrecorderとかInterPlanetary Waybackとか知ってる?
いいぞ〜これ Webrecorderは、Webページからwarcファイルを生成するWebアプリケーション
生成したwarcはコレクションに保存され、そのまま表示したり、
会員なら公開コレクションにすることでURLを貼って公開できる
+ New Sessionの隣の「…」から「Download Collection」でコレクション内のwarcファイルをダウンロードできる
warcファイルは魚拓の規格化された形式で、HTTPのステータスコードから画像や動画までそのページを表示するのに必要な情報を格納している
とりあえずwarcファイルさえあれば後からどうにでもなるから残したいサイトは今すぐcaptureしてこい
warcファイルを表示するには、「Webrecorder-player」というアプリが使える
またWebrecorderのコレクションにwarcファイルをアップロードして追加することも可能なので、そうやって表示や公開をしてもいい
InterPlanetary Waybackはもうちょっと高度な話で、IPFSと連携するためのものなんだけどこれは後でいい 19/01/13の分から取得したアーカイブが確認不可能になっている >>214 と同じ URL の 2018 年カレンダーを貼ってみます。
10 月に連続して欠けているのは、Internet Archive の仕様変更に対し
こちらの対応が遅れた (>>291) ことが原因です。
ttp://i.imgur.com/aYSmomB.png
ttp://i.imgur.com/35RP1No.png
ttp://i.imgur.com/fRsG33D.png
こちらは URL を公開しちゃってもいいや。
この人の騒動について個人的に興味が無くなってきていること、
また別途取得させている個別エントリのアーカイブで十分なことから、いずれ止めるかもしれません。
ttp://web.archive.org/web/*/blog.goo.ne.jp/chimaki-1014
昨年 3 月以降、一日 2 回の取得に対し計 4 回のスナップショットが記録されているのは、
HTTP から HTTPS へのリダイレクトと HTTPS で取得したブログコンテンツが
それぞれ計上されているためかと思われます。 先週辺りから
「502 Bad Gateway」が
表示されることが多くなった NHKニュース公式のスクショが
ちゃんと保存されないポンコツびりには
あきれた ×ポンコツびり
〇ポンコツぶり
あー本当に腹が立つ 近々でNHK NE○S W○Bのトップページを
InternetArchive経由で魚拓を取った人は
一度確かめてほしい
なぜか画面が「本日現在」の状態になっているから
ウェブ魚拓ではMETAタグが引っかかって駄目
ArchiveTodayも変な画像(白地に黒文字の注意書き?のみ)
を結果として返してくるので駄目
まさか頼みの綱のInternetArchiveで大失敗するとは思わなんだ
どうしてもN○K NEWS ○EBのトップページを残したければ
画面を直に撮影するしか方法は無いようだ htmlに本文が入ってなくて、ajax的に別のファイルから読み込むやつはいかんな。
wixも同じ理由で保存されてない。
本文ファイルのキャッシュが残ってたとしても、それを読み込みに行ってくれないのよね で、それはwebrecorderでも保存できないのかい? >>361
使い方が分かりにくいな
記録(魚拓)は取れても
その取り出し方がいまいち分かり辛い
後日に取り出してその当時の状態を
再現できなければ意味がないし >>360-361
何で「NHK NE○S W○B」のトップページの話を出したかといえば
先週日曜(1月27日)にあった某「国民的」グループの活動休止発表からだった
この時「N○K NEWS ○EB」のトップページでは
最上部の「速報」・そのすぐ下の「JUST IN」・本記事と
同時に3つの見出しで「○活動休止」の文字が並ぶという
何とも稀な状態になっていた
そこでInternetArchiveでページの魚拓を取り
同時にIrfanview経由でスクリーンショットを取った“はず”だったのだが
その画像を何らかの形で保存することをうっかり忘れてしまっていた
そして翌朝になってInternetArchiveを確認したら…
下のような状況になっていた
https://i.imgur.com/IBOpfrs.jpg
すなわち明けて1月28日になったが
前日27日に取ったものが表示されないという状態
一応は類似の画像を検索してみたがこんなのしか出なかった
https://pbs.twimg.com/media/Dx56MVSV4AEsqgB.jpg そんなわけで試しに1月27日以前に取られたものも表示してみたが
結局どの日でも表示されるのは“作業当日”の画面だった
つまりは二重三重で痛恨のミスをやらかしたことになり
本当に今週はそれを引きずった…
このままでは何か癪に障るので
おまけを罪滅ぼしに置いておく
(1月31日)
https://i.imgur.com/E96yEeA.jpg
https://i.imgur.com/bCjdPXO.jpg
https://i.imgur.com/EAUNldo.jpg
(昨2月1日)
https://i.imgur.com/hpvfmr9.jpg 時々出てくるこれ、具体的に何かやっているというより、
503 応答のエラーページがこのように書かれているだけとしか思えないんだけどなぁ。
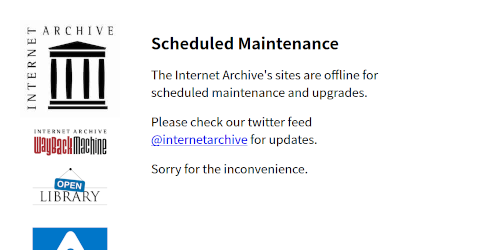 >>366
>>366
文字通りメンテナンス中と思わせるくらいに
数時間表示される場合もあれば…
この画面が出た後で再読み込みをしたら
すぐにトップ画面に戻る場合もある リンク先がなにもない真っさらなページだった時ってもう諦めたほうがいいですか? たしかに2/19にとったやつが消えてますね
前もこんなこと1週間くらい続いたけど戻ったときがあったので様子見ですかね アーカイブのサイトが何だかおかしいね
当サイトは昨日「Sorry,we are busy」なんていう
初めて見た表示が出た
ウェブ魚拓は今日の午前中重かった
Archive isは断続的にキレる
一体全体どうなってるのか yahoo!ブログまでサービス終了だ
どんどん老舗が消えていくなあ ネットのデータは儚い Yahoo!ブログ消えるのにYahoo!系はなぜかInternet Archiveで保存しても全部トップページに転送されちゃうから保存できないんだよな… 何だか重くなってるぞ
20分くらい前にはアクセス不能になっていたし 2日前くらいからarchive.orgの再生時画面が小さくなってしまって辛い
全画面だと作業が出来ないしなあ >>379
このトップページ転送本当どうにかならんのかな。 >>383
何なんだろうなこれ
自前でHeritrix回すとどんな感じになるんだろう
Yahooブログアーカイブ活動の本スレ
http://mevius.5ch.net/test/read.cgi/blog/1554380939/ 魚拓もInternet Archiveも引っ掛からないスレタイって >>388
サンクス。
adblockの詳細設定のマイフィルターリストに「*/yjsecure.js」を登録してadblock有効で転送されなくなった。 http://mevius.5ch.net/test/read.cgi/internet/1554553882/78-79
/save/ を知ってて /web/2/ を知らないとは。
あと保存の際に http:// や https:// を無条件に外すのも考え物。
HTTP から HTTPS へリダイレクトするサイトだと、そのリダイレクトも
保存回数に計上されてしまう。 >>392
そのブックマークレットを作った人間ではないけど、Wayback Machine初心者の自分に/web/2/が何なのか教えて下さい
あと保存回数の計上が増えると何か問題があるの? /save/知ってるのはgeocitiesのスレの方で多用されてたからじゃないかな >>395
これ
/web/2/は初めて聞いたけどその二つは言うほど特別な知識ではないと思うよ >>398
っぽいですね。
https://i.imgur.com/gZyzB5u.png
ただ、アーカイビングとインデクシングはそれぞれ独立しているみたいなので、
後者だけでデータの欠落が発生しているという可能性もあると思います。 全ページ内全文検索はまだ?
なんか問題でもあるのか? 昔やってたけどすぐ立ち消えたからきつかったんじゃね Scheduled Maintenance
先ほどからこの表示
長くなりそうか? >>406
機械翻訳使ったのかどうか知らんが、文章の意味を読み取れて無いだけやんか。 >>406
米国政府のサイトと米軍のサイト限定って書いてあるな
そこまで強調して書いてある訳ではないとは言えもうちょっと慎重に読もう
しかし、robots.txtが邪魔なら全サイトで無視しちゃば良いのにな
どうせ法的拘束力はないんだし 過去分リストが今日から(?)マイナーチェンジしている件 自動的に最新ログの年に飛ばない気がする。2019年。 数分前から「HTTP ERROR 400」と出て使えない 手動で1ページ1カテゴリーづつ保存するの面倒くさいんですけど、
自動巡回で指定のサイトやブログをhttps://web.archive.org/に保存出来る方法なんて無いですよね?
毎日毎日徹夜で保存して疲れた…保存しても保存してもキリがない… >>413
>毎日毎日徹夜で保存して疲れた…
>保存しても保存してもキリがない…
アーカイブサイト全般のユーザーの
最大の悩みでもあるな
一度やり始めたら強迫観念が出てきて
毎日やらねばならなくなる
しかも誰もがやっているわけじゃなさそうだから
自分が休んでも他の人が補完してくれる保証はないしね やろうと思えばプログラム組んで出来るよ、ネット探せば色々見つかる
さっきWebアーカイブ総合スレに投稿されたやつを転載
0175 py ◆o3kzHb/in8w0 2019/05/14 19:06:58
https://u1.getuploader.com/irvn/download/1657
web2IAWBM.dms ver0.000.007 WayBackMachineに保存 (web.archive.org) 2019/05/14
web2IAWBM.dmsはIrvineとDorothy2を使ってInternet Archive WayBack Machineに自動登録(保存)するためのスクリプトです。
自動で全てのリンクをたどって保存してくれるはずです。
web2IAWBM.dmsは素人が作った物なので至らない点も多々ありますが、
一応使える水準になったと思われるので公開します。
無料のウィルススキャンはしましたが、念のためもう一度スキャンされることをお勧めします。
同梱のDorothy2(の一部)は別の方が作った物です。
■ Irvine初回起動前に必ず jwordフォルダを削除してください。■
動作試験環境:windows10pro Irvine1.3.1 IAヘビーユーザーが多いであろうここの住人なら、
自動化手段を発見済みかスクリプト自作してる人がいるだろうと思ってたが、案外そういう訳でもないのかな >>414-416
ありがとうございます。
勇気出して聞いてよかった…頑張る archive.orgにファイルアップロードしてる人っている? 重宝していた攻略サイトが消えてしまった・・
アーカイブされていたのに何故?何が原因でまるごと
消えてしまったんだ? archive.orgにファイルアップロードしてる人っている? ベータ版の新しいSave Page Nowを使ってみたかったからユーザー登録してみた
思いのほかあっさり登録できて少し驚いた 今、サーバーエラー出てる
503 Service Unavailable
No server is available to handle this request. スマホからSave Page Nowを使ってTwitterをアーカイブしようとすると必ずエラーを吐いてくる
PCではそんなことになった経験がないんだけど何がおかしいんだろう
あと、これはスマホもPCも関係ないんだが、
Internet Archiveの場合ツイートがjsonと解釈さ
れてしまう場合が多い
Archive.todayやmegalodonは普通のHTMLコンテンツと解釈してくれるんだが、IAだと何でjsonになってしまうんだろう エラー入りました(この表示は初めてだ)
500 Internal Server Error
nginx/1.10.3 (Ubuntu) にしてもこうまで長時間の「メンテナンス」はいつ以来か 最近400errorみたいな表示が多かったのは前兆だったのか・・・? >>424
> ベータ版の新しいSave Page Now
初耳 なんか保存済みページをIA開いて記事とかの2ページ目から3ページ目に移動しようとすると2ページ目に移動する(移動できてない)。
なんかちょっとおかしい。 そのサイト
スクリプトでページ切り替えてるんでねーの? imgur直リンがSavePageNow出来なくなった。 Twitterをアーカイブすると必ず表示が崩れる人がいるんだが
あれって何なんだろうか 最近保存してないけどツイッターいつもUIが謎の外国語になってたわ >>451
それ多分IAが経由してるサーバーの国の言語で表示されてるんだと思う これarchive.vnだと保存できない奴も保存出来るから便利 これが示すのはInternet Archive Wayback Machineのことだろ。 https://web.archive.org/web/20190727084527/https://toyokeizai.net/articles/-/293979?page=2
東洋経済の記事で未保存記事を1ページ目を保存して、1ページ目のアーカイブから2ページ目のリンクを開くと
保存されていないから当然保存用のリンクが表示されるけど、2ページ目のアーカイブから3ページ目のリンクを
クリックすると2ページ目のアーカイブが再度表示される。
以前だったら連続で保存できたのにできなくなって直接SavePageNowに打ち込むしかなくなったっぽい。 https://toyokeizai.net/articles/-/293789
https://toyokeizai.net/articles/-/294305
この 2 つを Internet Archive の入力欄に突っ込んでやってみたけど、
どちらも先頭から最後のページまで、"This page is available on the web!" を経て保存できたけどなぁ。
https://web.archive.org/web/20190727093955/https://toyokeizai.net/articles/-/293789
https://web.archive.org/web/20190727094921/https://toyokeizai.net/articles/-/294305
どうもこちらでは現象が再現できない。 >>462
もう一回試してみたけど、また同じ症状になった。page=2が再表示。駄目やん
Firefoxアプデ放置してたのが原因かと思って、他のタブ閉じたりしてしばらくたったところで
アプデ前にもう一回挑戦したら、何故かpage=3も保存できた。あれ?できた。どうなってるんだ? archive.todayまったく繋がらないけど同じ状況の人いませんか? >>427
Heritrixの仕様か何かなのかな?
自前でHeritrix動かしたことないから断言は出来ないけど ひょっとしたら改悪が行われたか?
以前ならば、(うまく説明できないが)例えばニュースサイトならば、
本記事以外の近隣記事なり参照記事のURLをクリックすると、
取得前のものについては、新規の取得を促す画面が出ていた。
これが大量に記事を取りたい場合には、非常に助かっていたのだが…
ところが昨日からは、上記と同じ動作を行うと、そういう画面が出なくなった。
代わりに出てきたのがこれ↓
https://i.imgur.com/2mOTHmt.jpg
そのため、いちいち一つずつ「Save Page Now」の部分に
URLを打ち込んで、対処している状態だが…。
やっぱりどうにも面倒くさい。
「This page is not available on the web」「because of server error」
ということは、一部のサーバーが動いていないのが原因で、
それさえ治れば、先に触れた機能も復活するのか?
このままでは仕事量が多くなる一方だから、何とかしてほしいんだが。 因みに>>470とはメッセージが異なる。
「The Wayback Machine has not archived that URL.」
「This page is not available on the web」
「because request is invalid」 >>470
それ、起こるサイトでは以前から発生しているけどなぁ。
> そのため、いちいち一つずつ「Save Page Now」の部分に
> URLを打ち込んで、対処している状態だが…。
アドレスバーの /web/日付時刻数字/ を /save/ に変えるだけでは駄目なのか?
面倒なことには変わりは無いが。
せっかくブラウザにブックマークツールバーを出してるんだったら
強制保存させるブックマークレットを登録してしまえ。
ttps://pastebin.com/NA4c5krN >>473
>それ、起こるサイトでは以前から発生しているけどなぁ。
東京スポーツの公式サイトのうち「バックナンバー(本日の紙面)」に関しては、
こうした現象を確認していたんだが 、本当にあるとすればそのくらいで、
いきなり対象となる範囲が広がってしまった印象。
>アドレスバーの /web/日付時刻数字/ を /save/ に変えるだけでは駄目なのか?
>面倒なことには変わりは無いが。
これを試してみたけど、幾分作業が楽になった。これ、しばらく続けてみます。
本当にありがとうございます。 Twitterも最近その現象になってしまったな
アーカイブ先への負荷対策とかなんかね >>470に関しても、元に戻ったみたいだ(新規取得を促す画面が復活)。
とはいえ>>473最下段のブックマークレットは、使ってみたら
結構便利なので、しばらく併用ということで。
ところでchromeはともかくとして、先日からIEではかなり使い辛くなった。
保存の後、以前なら左上隅のロゴマークをクリックするとトップページに戻っていたのが、
なぜか違うページに飛ばされるようになった。
上方に四角形がいくつか並んでいるのと、小さな英文が表示されたページだが、
その四角形は関連サイトへのリンクらしく、左端の四角形をクリックすると、
やっとこさ当サイトのトップページに戻ることができた。
さらに言えば、「BROWSE HISTORY」(過去の保存リストが表示される画面行き)が
IEでは使えなくなってしまってる。 IEだと使いづらいね。過去のキャプチャ一覧も見られなくなったし。
Microsoft Edgeなら問題なく見られるから今後はEdgeで見ようかな >>480
元々そういう仕様。
/save/ を使って保存させたとき、ブラウザから Internet Archive へ送られた
リクエストヘッダ類 (俗に環境変数と呼ばれているやつ) は
一部の改変・追加のみで元サーバへ送られるので、
これを偽装することによって直リン回避は可能。
リファラーのみチェックしているサイトについては、やったことがある。
ただ、同一の URL について複数の日付のアーカイブが存在しているときに、
自分が /save/ したものだけ画像あり、他人が /save/ したものは画像無し、
ということになるのであまり実用性は無いと思う。 >>478-479
何が悲しくって未だにIE使ってるの?
MSももはやサポート放棄しようとしてるのに Internet Archiveがどうかは分からないけど、最近のサイトは面倒なIE対応を放棄してるところも多いし、
悪いこと言わないからEdgeとかChromeとかFirefoxとかに乗り換えた方が良い
というかIAも長くてあと2,3年でIEじゃちゃんと見れなくなると思うぞ IEだとまったく使い物にならなくなっていたのか。
検索かけて原因見てもだれも指摘してないので調べたら、5chのこのスレでようやく原因判明
クローム使えってか。たしかにweb.archive.org/web/*/ の保存一覧がちゃんと出るようになった
見られないからwebarchiveに無駄に垢とっちゃったよ消したい・・・・ >>482
図書館などの公共施設のパソコンだと、
いまだにブラウザといえばIEしか用意されてない。 IEは業務決め打ちシステム用が多くて下手に改変もできないが無視して捨てるわけにもいかないがんじがらめ状態なんだろうな >>481
ありがとう。Referer ControlをInactiveにしたら画像もキャプチャできた。 429 Too Many Requests
You have sent too many requests in a given amount of time.
…ありゃスレもあがってないや >>488
これ俺だけじゃなかったのか
てっきりアーカイブし過ぎたせいかと ここ数日
すぐに結果が表示されずに
画面が真っ白になる現象が起きている
今のところ少し時間を置けば普通の状態になるので
使えはするが何だか謎 >>490
同じく。
>>491
トップにしかアクセスできない。
ブラウザによってはトップすらアクセスできず。 >>488
スクショをJPEGで上げてる時点で程度が知れてる ようやくトップ以外にもアクセスできるようになった。 >>479
URL検索がずっと死んだままで特定サイトの年代別アーカイブが探りにくい
検索エンジンも昔はサクサクで一覧出てきたのが、何年か前にUIがリニュされてから、ずっと激重で不便極まりなかったけど… >>484
Chromeも古い端末だと最終verでも駄目だね。
Edgeが使えるぐらい新しい機種でないと… こっちは普通に問題なく繋がってる
今もSave Page Nowでいくつか保存してきた
ベータ版SPNのSave outlinksってオプションを初めて使ってみたがめちゃくちゃ便利だな >>501
> ベータ版SPNのSave outlinksってオプション
知らない ベータ版SPNのSave outlinks
いま試してみたが、ヤフーニュースはやっぱり魚拓とれなかった。 >>504
アーカイブが取れて無いのと、例のページ遷移スクリプトが発動してるだけなのと
どっちなんだ Save outlinksってのは、SPNに投げたURLのページに貼られてるリンク先も全て読み込んで保存してくれるオプション
さすがに無制限にリンクを辿る訳ではなくて1段階しか辿ってくれないけど、それでもかなり手間が省ける
遷移スクリプトの発火をキャンセルしてくれるような機能はおそらくないと思う >>506
>>504
今までインターネットアーカイブでヤフー関連のページの魚拓を
取ってもヤフートップに飛ばされた魚拓しか表示されなかったので
ここでは魚拓は取れないものと思っていたが、実は取れていたと知
恵袋に書いてあった。
http://superbabooooo.blog.jp/archives/27043737.html またクソ重になってら
他だと取りにくいページもあるのに 確か/web/1/が最古、/web/2が最新のアーカイブなんだよね
これ以外に隠しコマンドというか隠しエンドポイント的なURLはあるの? >>512
初耳だったのでexample.comで試してみたが最古のものが表示された
/1/と同じなのでは >>514
/web/年/ とか /web/年月/ とかは、現在の UI が Beta から本導入となった時に廃止された。
今でもエラーとはならないものの、数字の意味する通りには動かなくなっている。
>>511
数字の後ろに付ける、コマンドみたいなものは前スレでほぼ挙がっているから、
いわゆる文字化け騒動以降のレスに一通り目を通しておくと良いと思う。 >>515
情報ありがとう
主なものをまとめるとこんな感じだろうか、間違いや抜けがあったら教えてくれ
(全てhttps://example.comで利用可能なのは検証済み)
/save/:保存
/web/*/:アーカイブ一覧表示
/web/1/:最古のアーカイブ
/web/2/:最新のアーカイブ
/web/日付時刻数字fw_/:時系列・クローラー情報の非表示(文字コード変換あり)
/web/日付時刻数字id_/:アーカイブ時の生ファイル(文字コード変換なし、HTMLコード内のURLの置換も行われない)
こちらも参照のこと:https://en.wikipedia.org/wiki/Help:Using_the_Wayback_Machine#Specific_archive_copy
まだ情報を精査出来てないけどここも参考になりうるかも:https://github.com/iipc/openwayback/wiki 新しいSPNのSave outlinksなどのオプションのオンオフ情報はやはりHTTPリクエストの中に含まれてるのかな
このオプションを使った/save/を自動化できたらいいんだが どうでもいいことだが、前スレに比べるとこのスレは書き込み数がだいぶ多いな
何かのきっかけで人口が増えたのかもな >>520
ヤフーブログやヤプログまで消滅するからな。 >>510
ここ2〜3日おかしいね。
使える時もあるけど、すぐに息切れするかのように
アクセス不可になってしまう。
瞬時に見出しや内容を変えかねないニュースサイトについては、
他が調子が悪かったり、動作のスピードがゆっくりになった分、
ここのサイトがぴったりになってるが、ここもダメになったら本当に痛い。 魚拓界という言い方があるかは知らないが、
今年は受難の年だなあ。 釣りに引っ掛かりやすそうやつばかり住んでそうな界だな 自分の環境ではここ数日の間も普通に保存できてるから受難とか言われてもあまりピンと来ない 自分はいつアクセスしても特に何事もなく保存できているが、不安定で使えないという人もいるのか
回線か時間帯かマシンかブラウザかサイト特有の問題かはたまた別の何かか、何がおかしいんだろうな 使っていくうちに後になって「アクセス不可」と返してきたり
昨日などは一日中動きが固くなった末やっと画面が変わったら「アクセス不可」
と本当に様々だが
自分にとっては必要なんだよ
誰も新聞社のニュースサイトなんて取ってねえから
環境によって使えませんという話なら誰か自分の代わりにやってほしいわ… どこの新聞社のサイトなんよ
URL分かれば多少は手伝いようがある 時間が経つにつれ必然的にアーカイブの重要性は増していくので
IAには頑張ってほしいね 何かの間違いで消滅したら一番ショックなサイトな気がしてきた 今is共々落ちてる
同時に落ちたらなんにも出来なくて困る・・・ >>532
稀によくある
数日経った後に反映される >>534
まさに稀によくあるの好用例すぎるw
あの図解を思い出せる
●●●●●●●
●●●●●●●
●●●○○○○
○●●●●●●
●●● 最近の人ってInternetArchiveって知ってるんだろうか 知らない年長者も多く見かけるし、知ってて活用してる若者も多く見かける
老いも若きも関係なく、知ってる人は知ってるし知らない人は知らないんだと思う >>517
id_のコマンドを初めて知ったがすごく便利だなこれ、thx 30分くらい前から、5chのスレッドや、imgurの画像が
ハネられるようになったな。
>>539
分かるなあ。
「魚拓を取る」という行為自体が、まだまだ一般的ではないんだよな。 twitterとか見ると発言の証拠にスマホのスクショ使ってるのをよく見るよね
あんなんやろうと思えばいくらでもいじれるのに… このスレには未だにスクショをJPEGで貼る奴が・・・ >>543
アニメ板とかだとこだわるんだろうか
スクショの目的の多くは再現性では無いと思うから別にファイル形式はどうでもいいのでは >>541
>「魚拓を取る」という行為自体が、まだまだ一般的ではないんだよな。
同感だわ
過去の文書や書籍を将来のために保管するのが大事だって意識自体、日本では今ひとつ根付いてない
(どこかの地方図書館が入り切らない蔵書を焼却処分したという最近のニュースが好例)
昔からある紙の資料ですらそんな扱いなんだから、Webアーカイブを取るという意識が根付いているはずもないわな
それにしても、スクショのファイル形式がjpegだとなんか問題があるの?
確かにアニメのキャプとか高い画質が要求される種類の画像なら確かにダメだろうけど 既に重いんだから多少人が増えたってどうせ主観的な重さ具合は変わらんだろ
少しくらい重くてもアーカイブが増えた方がいい はじめまして。無知ですがすみません。
もう何日もこのインターネットアーカイブ(http://web.archive.org/)
どんなURLを入れても、何も出来ないです。
トップも前まであったURLいれる欄がなくなって(右上のsearchならある)、おかしな文出てるし。
↓トップはURLいれる欄がなくなり、こういう文だけ出てますが、英語わからないので日本語訳してもわけわかりません。
(The Wayback Machine is an initiative of the Internet Archive,a 501(c)(3) non-profit, building a digital library ofInternet sites and other cultural artifacts in digital form.
Other projects include Open Library & archive-it.org.
Your use of the Wayback Machine is subject to the Internet Archive's Terms of Use. )
右上から何のURL検索してみても、日付のも出て来ずにこのトップ文のままです。
でもスマホからなら前みたいに普通に検索出来ることを、スマホからやって、たった今知りました。でもどうしてもパソコンから見たいので。
何日もパソコンからインターネットアーカイブ出来ないのですが、スマホからなら出来るので、
出来ないのはうちのパソコンからだけなのか気になってます。
これはどういうことなのかわかる方いらっしゃいませんか。無知なのですみません。 「ブラウザが古い、ないしサポート外」に一票。
https://i.imgur.com/ir0AFD6.png
以前 Windows 2000 で頑張っていた人 (>>94-106) を思い出す。 >>552
同感
スマホでは見れるって事からもサポート外の古いブラウザのせいという感じがする 【ヤフー】Yahoo!ブログ【アーカイブ】
http://mevius.5ch.net/test/read.cgi/blog/1554380939/l50/
74 Trackback(774) 2019/09/30(月) 17:07:59.58ID:th5gp/Yr
Internet ArchiveでYahooブログを保存すると遷移スクリプトが発火する話なんだけど、
web.archive.org/save のページから「Save outlinks」にチェックを入れて保存すると
どうもYahooのトップページに遷移されずにアーカイブできるみたいだ
さっき偶然発見して何回か試したけど今のところ全て上手く保存されてる >>555
> Internet ArchiveでYahooブログを保存すると遷移スクリプトが発火する話なんだけど、
ニュースとか知恵袋は yjsecure.js が埋め込まれてるが
ブログも埋め込みあったっけ? save outlinksってURLレベルでは指定できないの?
/save/みたいに/saveoutlinks/みたいなのはない? >>556
ヤフーブログにもyjsecure.jsがあるかは分からない
でも以前web.archive.orgトップページのSPNフォームから保存した時は何回やってもリダイレクトされたよ
向こうのスレでもそれが問題になってたみたいだね
>>557
おそらくない
ただHTTPリクエストにsave outlinksが有効かどうか指定するオプションはあった(ブラウザの開発者機能で確認した)
何とも言えないけどsave outlinksで保存するスクリプトを組める可能性はあると思う 確認してきた
確かにYahooブログにもyjsecure.jsが埋め込まれてるね
https://s.yimg.jp/images/security/pf/yjsecure.js ってリンクがどのブログにも入ってた 少し実験して分かったこと
・少なくともYahooブログの場合、yjsecure.jsはモバイル版表示の時のみ発動する(と思われる)
・web.archive.orgトップページのSPNフォームをモバイル端末(スマホやタブレット)のブラウザから使うとモバイル版表示で保存される
・/save/のsave outlinksを使うと利用デバイスに関係なくデスクトップ表示で保存される(と思われる) >>561
> ・少なくともYahooブログの場合、yjsecure.jsはモバイル版表示の時のみ発動する(と思われる)
あぁ、道理で見つからなかった訳だ・・・。
気になったので、診断くん http://taruo.net/e/ をアーカイブさせてみた。
http://web.archive.org/web/20190930162118/taruo.net/e/
HTTP_USER_AGENT の行に注目。多分これだなぁ。
通常の /save/ を使うと、操作を行ったブラウザ名がそのまま相手先へ送られる。
ところが件の新機能を使うと、別の名前が送られる模様。
Firefox を使ったのに、それが一切現れていない。
つまり、新機能を使うとブラウザ名が隠されるので、
モバイルブラウザ向けに特別な動作をするサーバであっても、それが行われない。
Yahoo! ブログの場合、yjsecure.js を含まないデスクトップ向けのコードが出力される。
こういうことではないかと。
技術的な説明は省略。 (そもそもTOPページに飛ばすという仕様いる...?) 楽天かどっかで「あなたが見ているドメインは楽天じゃないよ!」みたいなエラーは出たりするなあ。
何かの詐欺で部品だけ呼び出してつかわれたりすることがあるんだろうか。 ところでrom-setは合法なの?
堂々と配布してるが大丈夫なのか rom-setが何なのか検索しても今ひとつ分からなかったが、
もう販売されてない古いゲームのROMのことなら米国法のフェアユース規定で守られてるのではと予想 最近Bummer多いな
リロードすれば普通に取れるけど >>568
> リロードすれば普通に取れるけど
なにげに気がつかなかったよw スクリプトは時間長くしとけばなんとかなりそうだけど、手動で保存する時めんどい >>570
だいたい3件以上
同時に取ろうとすると出てくるな
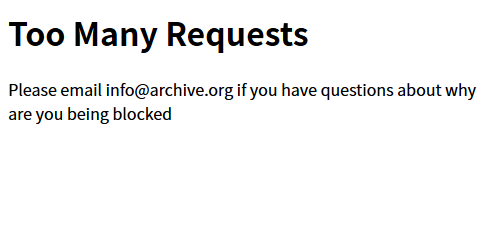
正直鬱陶しいのだが… 日本語URL(というかアルファベット以外?)だと挙動がおかしくなるのどうしようもないのかな Too Many Requests
Please email info@archive.org if you have questions about why are you being blocked
…もう、冗談抜きでいい加減にしてほしいよ。
もはやここしか頼るところがない、といっても過言ではないのに。
で、上に掲げた文の下段は、どういう意味?
ブロックに関しての質問はこちらまで、というだけか? 今のところToo Many Requestsで怒られた事ないんだが、どのくらいの頻度で何回くらいやると出てくるものなの? 俺もToo Many Requests出るな
感覚としては3~5連続で取ると出る、が出ないときは出ない
単純にサーバー側の問題な気がする >>577
> 感覚としては3~5連続で取ると出る、が出ないときは出ない
ベースとなる HTML だけでなく、個々のファイル単位ではどうでしょう。
HTML が保存できても、そこで使われている画像等を保存するために
副次的に発行される /save/ リクエストが Too Many Requests となってしまい、
結果としてそれらを取りこぼす、なんて事態が発生し始めたように思えます。
このエラーメッセージ、語順がちょっと変な上に文末のピリオドを忘れていて、
Internet Archive であまりこういう英文を見ることが無いので違和感がありますね。
 >>578
>>578
ごめん、個々のファイルまでは見てないから分からない
表示が出るようになったのは最近
語順に関しては、IAは割とそういう適当な所があるような気もするw この語順そんな変か?
ピリオドがないのも、この手のエラーメッセージの場合はそこそこあると思うけどな >>578
ということは、今後IAについても、
ウェブ魚拓に見られるような、
画像(写真など)の抜け落ちが出てきそうってこと?
何かそれも嫌だなあ Twitterの埋め込みがきちんと保存されないのが個人的に一番困ってるんだけど、この現象って以前からなんだろうか Save Page Nowの仕様変更をいくつか確認した
・web.archive.orgトップのSPNフォームで保存ボタンを押すと一旦/save/に誘導されるようになった
・/save/のオプションに「Save screen shot」が加わった
→有効にすると「/web/日付時刻数字/http://web.archive.org/screenshot/https://example.com」の形式でスクショ画像が保存される
→Save outlinksとの併用も可能だがリンク先のスクショは取得してくれないっぽい >>583
archive.todayみたいなアレか >>584
厳密にはちょっと違うかもしれない
Wayback Machineのスクリーンショット機能は単なる画像ファイルとして保存される
対してarchive.todayやウェブ魚拓は一応HTMLコンテンツとして保存するから、リンクなどは一応機能する >>586
おそらく違う
User Agentをめちゃくちゃな文字列にした上で、上の方で出てたプロキシ確認サイトをスマホのFirefoxからアーカイブしてみた
https://web.archive.org/web/20191011021858/http://taruo.net/e/
見れば分かるけど、使用したブラウザの情報がUAも含めて別の内容に置き換わってる
おそらくweb.archive.orgのサーバ側の情報なんだと思う
ヘッドレスブラウザか何かを使ってるのかも >>587
これは忘れてないよな、念のため。
 Too Many Requestsがマジで鬱陶しい
Too Many Requestsがマジで鬱陶しい
ほんとにニーズを分かって言ってんのか!?と言いたくなる >>590
それは分かってるから大丈夫
でもInternet Archiveの方にはスクリーンショットと普通のアーカイブを簡単に切り替える機能がないっぽいからな
比較の対象にはならないような気もする 所詮IAはアメリカ人様の物で日本人の物ではない。そこはわきまえるべき。
日本でも公正利用の概念を法律化するしかない。 台風で軒並みあらゆる施設が臨時休業の最中だが、
うおーい、「Too Many Requests」に添付された文章が変わったぞ!
https://i.imgur.com/Cy8ibMt.jpg
Too Many Requests
We are limiting the number of URLs you can submit to be Archived to the Wayback Machine, using the Save Page Now features, to no more than 15 per minute.
If you submit more than that we will block Save Page Now requests from your IP number for one day.
Please feel free to write to us at info@archive.org if you have questions about this. Please include your IP address and any URLs in the email so we can provide you with better service. >>594
google翻訳
> リクエストが多すぎる
>
> [今すぐページを保存]機能を使用して、Wayback Machineにアーカイブするために送信できるURLの数を1分あたり15個以下に制限しています。
> それ以上送信すると、(あなたの)IPアドレスからのSave Page Nowリクエストが1日間ブロックされます。
>
> これについて質問がある場合は、info @ archive.orgまでお気軽にご連絡ください。 より良いサービスを提供できるように、メールにIPアドレスとURLを含めてください。
「(あなたの)」だけ俺が付け足した 各地域の避難情報を見れる自治体のURLがたまにしか見れないから
アーカイブ取って見ようと思ったがずっとbummer >>595
ベータ版としては割と前から実装されてたけど、つい数日前に正式版になった
色々オプションが付けられるようになったんよ >>596
下手したらブロックもされるのか。
急いで大量に取るのも難しくなるんだな。困ったなあ。
>>600
確かにそうだが、1日辺り60回までだからな。
どこも慎重にやらないと駄目か。 InternetArchive側も限られた回線のリソースで全世界からのリクエストを受け付けないといけないんだから、多少のリミットは仕方ないよ
規模を考えると1分間に15個までならむしろ緩い方じゃないかな 今日100リンクほど一気にsaveしたけど20近くは一度に保存されるしブロックもされなかったけどな
HTTPリクエストに直後POSTしてる訳じゃないからかもしれないが >>604
ユーザースクリプトでhttps://web.archive.org/save/とwindow.location.href結合してwindow.openしてるだけよ 少ないように感じたけど、冷静に考えたら普通に十分だな 4秒に1個だから十分すぎるくらいだな
よほど大量のURLを数時間で処理したい場合ならもしかしたら足りないかもしれないけど、そんな状況はそうそうない >>608
>よほど大量のURLを数時間で処理したい場合ならもしかしたら
>足りないかもしれないけど、
…正直言って自分はそれなんだよなあ。
だってデイリースポーツの公式なんて、ひとつのカテゴリーでも
記事を続々上乗せしていくものだから、トップが馬鹿みたいにコロコロ変わっていくのよ。
だから目を放した隙に、取りたかった状態と、魚拓の結果が異なることが本当に多い。
しかも同じように記事を上乗せしていくのを、中日スポーツも
やり始めたんで、非常に今困ってる。
スポニチや日刊みたいに、記事は追加してもトップはしばらく変えない
くらいがいいのだけど。 祝10000回
ttps://i.imgur.com/xXiIGJu.jpg >>609
目指すところがよく分からないから的外れなこと言ってるかもしれないが、
定期的に更新をチェックして、以前の状態と変更があったら/save/を投げるようなスクリプト組んだら? >>611
「的外れなこと言ってるかもしれない」ってのは
「定期的に更新をチェックして、以前の状態と変更があったら/save/を投げるようなスクリプト組んだら?」
というのがそちらにとっては的外れなコメントかもしれないって事ね 新機能のスクショ、以前取ったやつが消えてるんだけど反映が遅いだけかな? 通常時でも動作が不安定になることが少なくないから、新機能ということで余計に不安定さが増してるのかもな
念のために一応スクショを取得し直してみては キャプチャ数からみて明らかに保存できてるのにまずHm.を返すのはなんなんだ また不調で全然取得出来ない・・・
日本からのアクセスだけ弾いてるとかないよね?
この手のアーカイブ取得しまくってるのは日本人多いからとかで ・ブラウザが古い
・連投しすぎてて1日間のIPブロックを食らっている
・いつものシステム不調
好きな原因候補を選ぼう >>612
皮肉だなぁ。
>>619
変換すべき URL が HTML 内部に大量にあるため異常と判断され、
結果としてインデックスから外されているとか、そういう予感。
元のソースを見るとスタイルシートが <style> 要素で挿入されていて、
その中にフォント等の外部参照が 1000 個以上ある。 やっぱ全然取得できませんわ
最新のurlを入力すると一週間前のアーカイブのurlに飛ばされる やってみた
スクショは全然ダメだったが普通のアーカイブは取れたと思う
https://web.archive.org/web/20191016233430/https://www.dworks-ent.com/ first archiveかどうかの表示止めちゃったのかな
あれ割と好きだったんだが >>623
いや今度は表示されたわ
単に通信が悪かっただけか 新しいSavePage、UserAgentが書き換わるせいかサイトのデフォルト言語が英語になってしまうな
まあ誰が取っても統一されるから良いといえば良いんだが エラーだの警告文だので全然ページ取れない使えないサイトになってしまった・・・ さっきからまるで保存できないな
しばらく待つしかないようだ 昨日あたりからSave outlinksの調子もおかしいような
Save Page Nowフォームに投げたリンク元のURLのアーカイブは取れるけど、リンク先のは全然取れない
エラーも出ずにただワーキングカーソルが延々とぐるぐる回り続ける
回線速度やマシンスペックの問題ではないはずなんだけどな
数時間おきに間隔を空けて試してるが、やっぱり問題解消まで待つしかないのか 根気よくリトライしてdoneになったページも半日おいて確認してみたらズコーってのが高頻度発生
徒労感はんぱないんで安定するまでしばしのお別れ >>628
>>629
自分も同じ現象になったけど、2日3日置いたらアーカイブされてたよ
表示上グルグル回ってるだけで内部的には取れてるのかも 数時間前のでもアーカイブ一覧を見ると全然残ってないのよね
いつか復活するだろうと取得し続けるけど精神的につらい ありがとう
でも試してみたら丸1日以上取得出来ていない模様・・orz あまりにもエラー連発するからステータスコード毎に適宜リトライするようなスクリプト書いてたら調子良い時期に突入したらしく確認がとれねえ /save/http://url~にアクセスすると/saveに飛ばされるのは新たな仕様ですか? https://i.imgur.com/mi8lPHF.jpg
https://i.imgur.com/312FfjE.jpg
なんかもう訳分からぬ状況に突入してまっせ
とにかくページ・画像ともに先に進めやしない
>>632
もしかしたら自分はそれかもな…
先月辺りから取らなきゃいけないものが激増したから 業務じゃないんだろ?己を強迫するな力を抜け
ていうか不安定なIAの現状みても当分離れるのが正解 殆どのサイトやページが何回登録押しても一発で簡単には?取れないようになってる
寄付集めて何改悪してんだよ
最悪だよ、これならスクショ取った方がマシだ >>636
そうです
つい先日変更されたばかり
>>637
ブラウザのURL入力バーにweb.archive.org/save/https://example.comと直打ちしたら自分も「Wayback Exception」になった
単なる不具合かもしれないが、もしかしたら/save/のページからの入力のみ受け付ける仕様変更になったのかもな
>>641
チェックボックスのオプションのことかな
あれ便利だから個人的には重宝してるんだけど人それぞれか >>642
>直打ちしたら自分も「Wayback Exception」になった
今試したら問題なくsaveできた
やっぱり一時的な不具合だったみたいだ /save/http://url~→今まで通り保存
Save This Url→/saveに誘導
時々サーバーエラー返るけど保存できてるっぽいな 前から1割以上出てた気がするんだがひょっとして出現率100%超えた? Bummer出現率はどうも環境や時間帯によって変わるっぽいからな
自分は体感で0.5~2%くらいだが、5割を越える人もいるらしい >>622
ありがとう
17 Oct 2019で撮れてるのをこちらでも確認 もっと積極的に寄付募っていいと思うんだけどな
Wikipediaなんてクソデカアピールしてるのに Wikipediaみたいなしつこい広告をされると却って寄付する気が失せるが、
Internet Archiveみたいに全く何も言ってこないと逆に心配になって寄付したくなってしまう Save outlinksで読み込んでくれるリンクは50個が限界みたい
外部リンクがいくつあろうと最大で50個しか読み込まれてない
まあ無尽蔵に外部リンクを辿ると大変なことになるから制限をかけるのは無理ないけどな
ただ読み込むリンクをどういう基準で選定しているのかが気になる、もしかしたらランダムなのかもしれない 普通なら「先頭からパースして50個に達したら終了」とか、そんな感じで組むと思うけどな。 ブラウザの履歴消すとweb.archiveで取った筈の履歴がweb.archiveから消えてる事が多いんだけど、
どうしたらいいんでしょう…? 100%それで消える事はない
多分、カレンダー経由かアーカイブURL直打ちかの違いだと思うけど(カレンダーは反映が遅い) 確かに100%ありえないな
これまで見れてたアーカイブがブラウザの履歴を消した後見れなくなったって言いたいんだと解釈したけど、
そういうことならWayback側のシステム不具合と履歴消去のタイミングが偶然重なったんじゃないかな あれ強制セーブどうやんだっけ
/save/にアドレス入れたとたん保存済みの古いページに飛ぶから現時点のが保存できん >>659
それ保存されているはずでは?
アドレスの日時は今現在の時刻になっているはず。
ただし日本の時刻とはズレている ああ騒がせてすまんかった やり方がよくなかったんだわ
ちゃんと保存されたのを確認 18 日あたりからでしょうか、一部の古いブラウザへの対応が復活していますね。
全く使い物にならなくなっていた Internet Explorer 11 で
カレンダ画面が描画できていることを確認。
https://i.imgur.com/5XWVxdq.png IE11はサポート現役のブラウザだからな
そうでなくっちゃ Web開発やってるとIEはとにかく邪魔者でしかないんだけどな
個別対応とかが面倒だしセキュリティ上の懸念もある
IAもよくサポート復活したな、要望が多かったんだろうか 「ぐっちゃぐちゃだけど一応使える」程度でも十分だよね 相変わらず迷走中。ブロック期間を五分間に短縮。
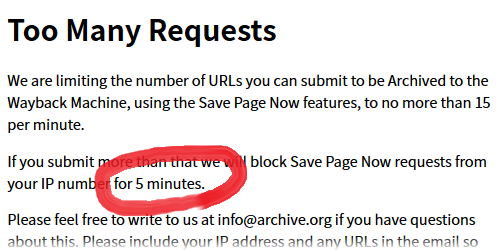 連投具合でブロック時間が変わるんだと予想
連投具合でブロック時間が変わるんだと予想
まあブロック時間が長くなるよりかはマシでしょ URLの末尾が「?」だとアーカイブが取れないバグ無いか?
正確に言うと勝手に「?」が取られて意図しないページが取得される
例えば
example.com/test?
をアーカイブしようとしても
example.com/test
となってアーカイブできない
対策としては適当なクエリを付ければアーカイブできる。上の例なら
example.com/test?hoge
とすれば取れる、URLは変わるけど...
クエリの開始点と誤認識してるのかな? >>673
> URLの末尾が「?」
そんなサイトがあるのか。知らなかったのだ。 >>676
パーセントエンコードされているのをデコードするマヌケ URLをエンコードして保存しないとそりゃそうなるわな そうですか、じゃあ保存方法を教えてくれ
https://web.archive.org/web/*/https://ja.wikipedia.org/wiki/ソウナンですか%3F まあ?記号だけエンコードしてもそりゃ意味無いわな
URLの日本語部分全部をエンコードせな 「URL パーセントエンコーディング」で検索して分からないならもはや絶望的だから諦めろ >>683
Edge なんかだと、location.href も document.URL も
decodeURI() された状態で入っていますからねぇ。
アドレスバーの中身をコピーした場合もまた然り。
https://ja.wikipedia.org/wiki/ソウナンですか%3F
まぁ同一ブラウザ内で単純に http://web.archive.org/save/ を頭に付けて
アドレスバーへ再投入するだけなら問題は起こらないとは思いますが。 いや >>676 で自分で答え書いてるって
URLエンコードの理解以上に救いようがない Wayback Machine
いつの間にかヤフーニュースのスクリーンショットを取れるように
なっていた。
これだとヤフーのトップページに遷移されることもない。
Save screen shot にチェックを入れてからクリック。 何か「attention request」とか出る(´・ω・`) 午後から503が頻発すると思ったら
いきなりメンテナンスに突入 >>686
もし良かったら取得できたURLを張ってくれないか?
本当に取れてるなら悪いがマウント取りたいだけにしか見えなくてな
↓のカレンダーでは青丸になってるが取れてない(エンコード有り無し両方)
https://web.archive.org/web/*/https://ja.wikipedia.org/wiki/ソウナンですか%3F web.archive.org のバグだね
本来エンコード済みなら無視しちゃいけない末尾の%3F (?) を無視しちゃってる またなんか挙動がおかしいな
保存完了したから確認しようとすると「セーブしますか?」のページに飛ぶ
ドメインから引こうとしても1個もヒットしない >>690
メンテナンスは事前に予告してほしいよな アドレスの文字列にNGワードがあってublockが反応してるケースがあった
archive全体もスルーにしないとあかんかな Internet Archive
We're experiencing some technical issues, cause
undetermined at the moment. Site availability may be
spotty for a while. We will update when we have more
news. Thanks for your patience!
5:49 - 2019年11月14日
https://twitter.com/internetarchive/status/1194719014045380608
https://twitter.com/5chan_nel (5ch newer account) Internet Archive
Update: We should be stable again, looks like it was a
router issue.
6:06 - 2019年11月14日
https://twitter.com/internetarchive/status/1194723218638036992
https://twitter.com/5chan_nel (5ch newer account) ?
ttps://i.imgur.com/nINvdBL.jpg 正直日本ではこれ以上有名になって欲しくない
アーカイブの重要性が広まってない状態で有名になっても
アーカイブの削除や拒否だらけになる未来しかみえん >>701
国会図書館のアーカイブがもっと貪欲で解放的ならいいんだけど 某所で炎上したとあるサイトの管理人がInternet Archiveに英語メール送って、証拠用にSavePageNowで取られたアーカイブを非表示にさせた事例は前に見たことがある
Archive.todayにもアーカイブ取ってる人がいたから証拠が消え失せることはなかったけど、Wayback Machineのアーカイブって結構危ういよね ちなみにそのサイトは炎上騒ぎの後ia_archiverを弾くようにrobots.txtを変更してたけど、
SPNではブラウザのUserAgentが用いられるのでSPNでアーカイブを取ること自体は今でも可能なまま
ただし取得しても"This URL has been excluded from the Wayback Machine."という例の表示が出て閲覧はできない
" Boomerを更新してもBoomerが出るようになった。 outlinkが一覧の他のページも保存しちゃうから次のページのoutlink取得しようとしても10分以上待たなくてはならない。
取得直後のページは10分間保存なしにして、他のページだけ保存してくれればいいのに。 >>709
> outlinkが一覧の他のページも保存しちゃうから次のページのoutlink取得しようとしても10分以上待たなくてはならない。
あー、そうなのか。それは知らなかった。 MapionとかGoogle Mapも取れるようになってほしい。
画像の撮影場所を示すのに使われているんだよね。 先週辺りからまたおかしくなってるな。
新しく取得したものが、過去の一覧にすぐ反映されないとか。
または取得できたと思ったら、確認すたらまだ取得前の画面に戻っちゃったりとか。 503が返ってくるようになったので、アク禁されたのかと思ったが、
TOP開いたらScheduled Maintenanceだった。永久アク禁されてなければいいけど。 もう今日はお話にならねえくらい酷い状態だな
Sorry連発
かつ魚拓の結果が全然出て来ねえ 最近調子いいなぁと思ったら急に悪くなったりツンデレなのか?
>>715
今日はAPIにすら反映されてないから止めたほうが良さげ あかんメンテ後ずっとこれや
This page is not available on the web
because of server error 使い物にならんな
深夜に取った分ちゃんと取れてるかも怪しい 物理的にどっかで断線でもしてるんじゃないかと疑うレベル Wi-Fiの近くで電子レンジ使ってるのかもしれない 毎日取得されているurlのアーカイブ一覧でも23日の10:00(UTC)くらいからバタッと取得止まってるのな
週末に入ってるから復旧遅れてそう こんだけ不安定だと寄付のお願いの必死さに説得力がある ここ数日保存したのを確認したらほぼ全滅
これじゃとても寄付はできんな 寄付しないと余計に酷くなるだろうし、財布に余裕が出来たら少し寄付しようかと思う
インターネットアーカイブが完全に使えなくなったら本当に困るし Twitter社が半年以上ツイートしてないアカウントを12月に削除するらしい
故人のアカウントも消えてしまうのかと問題になってるんだけど消えたら困る
とりあえず急いで特に大事なツイートはここに保存してるけど みんなが捨て垢やらサブ垢やら作りまくってるからサーバを圧迫してるんだろな
UserStreamを廃止したのも資金の問題があったみたいだし事情は分かるが、
にしてもログイン確認できなければ一括削除ってのは残酷すぎる気はするな 半年ってなあ
逆にbot投稿ならこれに引っかからずに生き残るんだろうし
バランス悪い結末になりそうだ 混乱と反対が大きかったためか、故人のアカウントをどうするか上手い方法が見つかるまで削除は当面延期するそうな
とりあえず余裕は出来たけど、Twitterのアーカイブという懸案事項もできたな archive.is 鯖臨終か(´・ω・`)?
#192q…とか出る 👀
Rock54: Caution(BBR-MD5:1322b9cf791dd10729e510ca36a73322) archive.is試しに保存したが普通だぞ
IAの方が23日以降に保存した内容が時間とともに消えてヤバイ ttps://news.livedoor.com/lite/article_detail/17447598/ >>736-737
確かに保存はできるが、いかんせん待ち時間がクソ長過ぎる。
案の定、デイ○ースポーツの芸能カテゴリー取ったら、
待ち時間のあいだに記事が一つ追加されて、先にIAで取ったやつと比べて
「ズレ」が生じちゃったじゃないか…。魚拓を取るなら、全て同じ条件で取りたいのに。 でも俺はやりたいんだよ。でもやるんだよ!文句あるか?
ただ、あそこはメンテナンスでもやったのか?
しぱらくデ○リースポーツの記事が、テキスト状態でしか取れなかったが、
今日取れたものは、以前と同じようにカラー・写真入りで取れてる。 そこまでデイリースポーツの完全なるアーカイブに固執する理由が気になる
傍から見てると、こういう言い方も良くないが正直異常に見えてしまう それも固執している対象が個別の記事とかではなくて、
トップページとかカテゴリー別とかの一覧ページだからなwww >>146あたりが初出かな。
キーボードをバンバン叩いてアーカイブを取得する行為そのもので
アドレナリンがピュピュッと出ちゃう人なんだろうな。
本当に必要性を感じているなら、自動化とかもう少し別の方向を
考えてるだろ。二年間もの間、何やってたんだ。 「自動化は信用ならない、自分の手でしっかりとアーカイブできたか確認したい」ということな分からないではないが、それにしても時間の無駄では? 実際画像メインのサイトなのに画像が全く取れておらず
アーカイブ検索時の邪魔になってるだけのアホアーカイブもチラホラ見かけるんで
確実にってのはわからなくはない 何?コレ
ttps://f.uploader.xzy.pw/eu-prd/upload/20191128232625_34756b6f49.png >>748
何年か前の閉鎖された海外ロダ群でコレよく見かけたな
先に読みづらい認証コードいれろってヤツ Archive.is の待ち時間がクソ長過ぎるという話。
同サイトで定期的にアーカイブを取得させるスクリプトを走らせていますが、
1. 事前に http://Archive.is/ からトークンを取得。
2. ターゲット URL 等の情報を http://Archive.is/submit/ へ送信 (POST)。
3. 200 応答が返り、コンテントボディに loading.gif への参照が
含まれていればアーカイブ成功と判断し終了、あとは知らんぷり。
― 以上の手順で問題は起きていないですね。
取得開始からアーカイブ完了まで時間が掛かるのはあちら側のプロセスなので
仕方が無いとして、取得状況を羅列したページを繰り返し読ませるのは
人間向けのただの演出。
>>739
記事のリストはベースの HTML に含まれていて、アーカイブ時は一番最初に
保存されるファイルですから、待ち時間云々は無関係。
単にアーカイブを開始させるまでに時間が掛かってしまっただけ。
>>748
CloudFlare でホストされているサイトに Tor 経由でアクセスすると良く出ていましたね。
数ヶ月前にそれが突然出なくなってしまい、逆にこちらが「まさか生で繋がってる?」と
不安になったことがあります。 214氏には各アーカイブサイトの自動化の知見についてブログかQiitaかどこかにぜひまとめて文章化して欲しい
需要はかなりあると思うんだが archive.is、内部リンクの置換が廃止された?
28日以降のアーカイブは元リンクに飛ぶ 23日以降から全部アーカイブ消えてるんだけど・・・・ なんかアーカイブしたはずなのに検索にURL入れてもアーカイブされて無いって出るんだけど…
それでもう一度アーカイブすると初めてアーカイブした扱いになってて、検索でURL入れるとまた無いってなるんだけど…なにこれ もう一度やってみたらどうもアーカイブは一応とれてるみたいだけど
検索でURL入れても最近のアーカイブは結果に出てこなくなってるっぽい 昨日試しにこのスレ保存してブクマしといたが半日ほどで消えた
今はまともに保存できないらしい 保存関連の処理とアーカイブのインデクシング・閲覧関連の処理は別々のプログラムが担ってるからな
今回は後者の部分が不安定になってるんだと思う >>757
ファイルが Internet Archive に保存できているかどうかを確認するために
先頭に http://web.archive.org/web/2/〜 を付けた URL でチェックするのですが、
/2/ を保存日時の数字に置き換えた URL へリダイレクトできているのに、
つまり当該日時のアーカイブが存在することが判っているのに、
そのリダイレクト先では Save Page Now (404 Not Found)。
ここ二週間ほど、こんなことが度々起きています。
つくづく「別プロセスなんだなぁ」と感じます。 そんな小細工なんてやられたら
瞬時で変わるやつが取れないじゃないか
こんな誤爆も取れやしない
https://i.imgur.com/L12ywG3.jpg 普通にワンクリックで取っていても「リダイレクトが繰り返し行われました」
「Cookie を消去してみてください」という表示が時々出るな. IAは「クッキーを食べないブラウザ」として動作するから
クッキーを食わせるために無限リダイレクトループ、
それがそっくりそのままアーカイブされてしまったんじゃないの? 一時的にIAを弾いてたとしても内部的には情報は保存されてるのか
消えたと思ってたが安心した archive.is
robots.txtに従わない 👀
Rock54: Caution(BBR-MD5:1322b9cf791dd10729e510ca36a73322) donateに💗が付いてて笑った
というか60ペタバイト超えてたのね
https://archive.org/donate/ donate
草 ttps://i.imgur.com/g3xBqiq.jpg Donateリンクにハートマークって他のサイトでも結構見るよ 確かに英語圏のサイトだと結構よく見るよね
何かそういう文化か風習か何かがあるんだろうと思う 日本人が感じる猫なで声ニュアンスはないってことだろうか 再巡回時に同じデータだった場合「同じでした」とだけ記録してるのかな
それとも完全重複で保存してるのかな スポーツ紙をアーカイブすると「記事を見る」の部分が折り畳まれる(´・ω・`) 開けない(´・ω・`) >>783
自前でアーカイブ取るか?
鯖からのソース保存じゃなく、その瞬間ブラウザで表示してる状態で保存する自作のブックマークレットある
ブラウザでブックマークすれば保存できる
冒頭のjavascript:はブラウザによってはペーストしたときに自動で剥がれるので、剥がれてたら自分で付け直してブックマークすること
javascript:(()=>{'use strict';const c=new Date(),h=document.documentElement.cloneNode(true);
let n=h.querySelectorAll('[href]'),i=n.length-1;while(i>=0){n[i].href=new URL(n[i].href,location.href).href;i--;}n=h.querySelectorAll('[src]');i=n.length-1;while(i>=0){n[i].src=new URL(n[i].src,location.href).href;i--;}
const b=new Blob([new XMLSerializer().serializeToString(document.doctype)+h.outerHTML],{type:'text/html'});const a=document.createElement('a');
a.download=c.toUTCString()+
' - '+decodeURI(location.href).replace(/\*/g,'*').replace(/\//g,'/').replace(/:/g,':').replace(/:/g,':').replace(/\\/g,'\').replace(/\|/g,'│').substring(0,123)
+'.html';a.href=(URL||webkitURL).createObjectURL(b);a.click();})(); >>786
レスの一行制限で改行入れたけど、多分「"+"の前の改行」で動かんと思うから
改行消してやってくれ
改行全部取っても動くようにしてあるからそれでも良いが 最近のarchiveisはもう駄目だな
待ち時間長くなったうえに今日は巻き戻るから取得すらまともに行われない 昨日は魚拓経由でつかえたけど今日は何やってもだめだ Archive.isやら何やらの話してる人はウェブ魚拓スレに行ってや
IAの話の中で他サービスの話題が出るのは分かるがこの場合はそうじゃないだろ pixivって今アーカイブできない?
昔はできてた気がするけど >>793
いくつかSPNに突っ込んで試してきた
保存完了の表示は出るけどWayback自体が不安定なせいか、アーカイブが表示できたり出来なかったりするんだよな
スクリーンショットの方はとりあえず取れてたから、おそらく普通のアーカイブの方も取れてるんじゃないかと思う
まとめると、おそらくアーカイブIA側が不安定だから 途中送信してしまった
まとめると、おそらくアーカイブは出来るがIA側が不安定なせいで上手く行ってないだけだと思われる
あとアーカイブ時に日本国外の回線からアクセスするので、英語版ページへリダイレクトされる点にも注意 ここでは、動画の内容に関する話は抜きで。
ttp://web.archive.org/web/20190717122047id_/video.twimg.com/ext_tw_video/1146432912117489664/pu/vid/1280x720/DhxeMNq_qWw8iakm.mp4
普通にアクセスを掛けても、どういう訳か 200 OK ではなく 206 Partial Content を返してくる。
当然、返してはいけない応答なので一般的なクライアントではダウンロードできない。
レスポンスヘッダを見ると
X-Archive-Orig-Content-Range: bytes 0-3091160/3091161
という行があるので、あるクライアントが Internet Archive に当該ファイルを
保存するよう要求したときに
Range: bytes=0-3091160
の指定が何故か付いてしまっていて、それがそのまま IA から video.twimg.com に送られ、
範囲指定付きリクエストとして処理された応答が IA にアーカイブされた、
ということだと思う。
しかし、何をどうやったら範囲指定付きのアーカイブ要求なんか出るのかねぇ。 検証用環境がなくて断定出来ないので完全な予想だが、Heritrixか何かの設定のせいなのかもな
Save Page Now経由で取得できる動画の容量にあらかじめ制限をかけてあるんじゃないだろうか
動画はかなり通信量を食うし、無制限の取得を許可したら色々な面で大変な事になるだろうから、
そういうリミッターが存在しても不思議ではないと思う うーんpixiv保存するとなぜかどうしても保存されるのが真っ白なページになってしまう
なぜだろう >>801
これはヤバいな
2019年だけで10ペタバイト、1996年〜2011年に保存した量の2倍ものデータが追加されたとか…
いくら寄付を集めたところでこんな膨大な量がずっと増え続けていくんじゃじり貧になるのは目に見えてる気が…
お金だけじゃなくて置き場所も足りなくなりそう
AI使って同じだったりほとんど変化の無いページは消していくとかしないと
あとは結局クロールする範囲を元と同じに減らすしかなくなる気がする
それとクラウド使ってないってことはここのサーバーが火事とかになったら全部パーってことでそれも怖いな
Googleみたいに世界中に何十にもバックアップとか入念な事はしてなさそうだし save now機能付けたころこのスレでも大丈夫なんかとは言われてたよね 不安定なのに寄付なんかできないとか言ってる人をどこかで見かけたがアホかと思う
寄付しないといけない状況だからこそ不安定なんだろ 追加データに際限はなく増大の一途
後20年持つサービスではないな まー言い換えれば最悪の場合その1996-2011のだけ残せばコスパ高そうだな 客観的に勧化得た場合
もしも残す価値や必要性があると思ったらお金持ちは寄付するだろうね
荒らしみたいなことを言ってすみません ちっとも荒らしみたいではないし、ちっとも客観的でもない 確かに荒らしっぽくないし同時に客観的でもない
慈善事業にしてもそんな地味なことに金使う富豪はいないだろ
苦しんでる人を援助することに優先して金を使うと考えるのが妥当 ツイッターで100万くれる人たちに運営がいいねするのはどうだろうか 試しにvプリカ買ってきて寄付しようとしてみたけど寄付の受付部門にメールして問い合わせろって文章が表示されて弾かれっぱなし
海外の住所の書き方の通りにフォームは埋めたし、カードの番号も期限もセキュリティコードも全部確認したけど受け付けてもらえない
普通のクレジットカードからの寄付しか受け付けないってんなら、日本語版の案内を用意してない不親切さも頭に来るし寄付は無しだな 関係ないけどarchive.isの方でYouTubeのコメントが保存できるようになってるな
昔もできてたけどここ何年かはできなくなってたから嬉しい
Internet ArchiveだとYouTubeは保存できないから Vプリカは向こうからは完全にVISAクレカと同じにしか見えないはず いやVプリカが使えるとかどこにも書いてないだろ
PayPalアカウント持ってるならあらかじめ入金しておいた上で支払う事は出来ると思うが
むしろクレジットカードと同じようにしてVプリカを使えると思ってる方が間違ってるぞ 個人的な経験で理由は分からないけど、国外との支払いでVプリカ使うと上手くいかない場合がそれなりにある
PayPal併用した方が確実 >日本語版の案内を用意してない不親切さも頭に来る
随分身勝手な奴だな、Wikipediaじゃあるまいしそこまでするリソースも余裕もある訳無いだろうが
寄付関連の案内が全く存在しなかったら不親切と言えるだろうがそういう訳でもないし、
Google翻訳使えば読めるものを不親切だとか言うのはおかしい
5chは使える癖にGoogle翻訳を使う脳味噌は無いのな、哀れ 寄付のお願いだけで済ませてくる分宗教としてはだいぶ良心的
本物の宗教と違って無くなったら困るけど Internet Archive以外でネット情報の保存活動に積極的なところが全然無いのは
著作権とかの問題もあるがそれよりも結局はこうやって天文学的な量の情報が日々無限に増え続けていって困るのが予想できるからなんだろうな
それだけにあえて頑張っているここは貴重で応援したいが
本当にどうするんだろうな
もはや現代ではほとんどの情報がネット依存状態なのに
もしここが無くなったら人類の歴史で現代の情報だけがすっぽり消えてしまって空白地帯になって大損失だろう Googleはやろうと思えば出来るだろうけど
まぁ結局金にならないっていう問題にぶち当たるんだよねぇ・・・ >>825
そもそも金になった時点で問題。
フェアユースの範疇から外れて、アーカイブ自体が違法コピーに成り下がる。 非営利団体だからこそWayback Machineなんてグレーな代物を運用できるわけで
Googleが寄付するって形にすれば法的にはセーフかもしれないが、Googleの金がInternet Archiveにまで入ったら法律とは別の問題でマズいことになりそう 翌朝、Internet Archiveのサーバーの前にピカピカのランドセルが ランドセルは安いモデルでも実用上大差ないけど安価なHDDはSMRだし… outlinksがSavingのまま止まる
調子悪いのか 寄付のお願いが出始める前後からずっとoutlinksは不安定 英国立図書館のWebCiteはどう?
IA以上に貧化してるか… WebCite は新しい魚拓は取れないのではなかったかな? ここってアメリカ政府とかも利用してなかったっけ?いざとなったらお偉いさんが金出して保護するんじゃないかな そこまで楽観的でもない
非営利の図書館やアーカイブ団体はどこも大体同じように財政難に直面してる
世界最大規模の図書館として有名なニューヨーク公共図書館でさえ、資金繰りに四苦八苦して寄付を求めて駆けずり回ってる訳で 寄付600万ドルがゴールになってるけど、そんだけでやってけるもんなのかね?
とりあえず5ドル投げたけど いずれ枯渇はするけど当面はそれだけあればやって行けそう、ってことだと思う 最近Twitterのどんなちょっとした下らないいいねもリツイートもないような呟きでも全て即座に網羅的にここに保存されてる事に気づいた
そりゃパンクするわ 調べたところ>>731の発表を受けてArchiveTeamが動いてるみたいだな
https://archive.org/details/archiveteam_twitter
一応「故人のアカウントを保存する方法が見つかるまで削除延期」とTwitter側は言ってるけど、ArchiveTeamはそれで満足するような組織じゃないし 裏を返せば「保全する方法が見つかったら削除開始するよ」って意味でもある訳だからそりゃアーカイブするわ Twitterと連携して全公開TweetデータをIAに渡してくれれば一番楽? そのまえにGoogleでのリアルタイム検索を再開してくれよ とりあえずアーカイブされたがurlがわからず
二度と発掘されないただの化石と化してるデータも多いだろう 今のアーカイブ量で全文検索したら凄まじい事になりそう 全文じゃなくてドメイン+<title>+日付範囲でも相当役に立つんだけどな… 検索エンジンの運用みたいに、先に索引付けしておくんじゃないの?知らんけど メンテ画面になったね
果たして今回は何時間かかるのやら We're sorry ? something's gone wrong.
Our team has been notified. punycode表記のURLの挙動がおかしくなるの
何とかならないのかね 600万ドルは確保出来たのかね
あとpaypalを通じて寄付をするって日本では違法だし、良くて規約違反でアカ消滅か悪くて警察沙汰にならね? >>862
https://donate.wikimedia.org/wiki/Problems_donating/ja#%E3%81%AA%E3%81%9C%E7%A7%81%E3%81%AE%E3%83%9A%E3%82%
A4%E3%83%91%E3%83%AB%E3%81%A7%E3%81%AE%E5%AF%84%E4%BB%98%E3%81%8C%E6%8B%92%E5%90%A6%E3%81%95%E3%82%8C%E3%81%9F%E3%81%AE%E3%81%A7%E3%81%99%E3%81%8B%EF%BC%9F >>863
これ情報古くないか?
今は普通に受け付けてるぞ ttp://2chan.tv/jlab-long/s/long200107161313.jpg >>865
スポーツ報知のアーカイブ頻度すごいな
いつぞやの人がついに自動化でも始めたのか まぁアーカイブという面では
そういう無償で熱心にやってくれる人が多い方がいいので
なんでそれに拘ってるのかは知らんが その辺が、ただマウスをポチポチするだけの人と
そうで無い人との違いなのかと。
PCを使った単純繰り返しの定型作業、自動化させてみたら
それが原因で首切られたなんて話もあるくらいだからねぇ。 それにしても同一IPからこんな立て続けにリクエスト送れないはずだよな、自動で弾かれそうなもんだが 報知だけバグ?
報知
ttp://2chan.tv/jlab-long/s/long200108162357.jpg
日刊スポーツ
ttp://2chan.tv/jlab-long/s/long200108162444.jpg F5連打で無駄に負荷かけまくってる悪質荒らしに近いな Base64エンコードで画像埋め込んでるサイトが文字化けするっぽい?
https://web.archive.org/web/20200109161142/http://up-img.net/img.php?mode=gif&id=2358 firstじゃないurlのは直近アーカイブからx週経過しないとNGの制限設ければいいのにな
未経過だと有料で取得できるようにすりゃタダで爆取得しやがる乞食のとばっちりもマシになる >>849
5chの過去ログに貼られてる閉鎖済みサイトをURL検索で発掘したり…
>>869
手動だが、Wikipediaの編集記事とかYahooニュースとかTLS1.2未満のブラウザや端末から直接読めなくなったページを読むために保存している。
魚拓やisにも取ってるがアーカイヴサービスまでTLS1.2必須に仕様変えられないことを祈る。 Yahoo!ニュースをwaybackするとトップページがアーカイブされる Yahooニュースはいったん他所で取ったアーカイブを重ね取りすれば流れないンだったか。 yjsecure.jsをNGすれば転送されない。散々既出 adblockの詳細設定のマイフィルターリストに「*/yjsecure.js」を登録してadblock有効
と設定すればいいんだっけ? ここ数日は取得しても古いアーカイブにリダイレクトされて本当に取得してあるか確認できないようになっているので注意 5ちゃんのURLアーカイブできなくなってない?数日前からできないんだけど なんか自分の環境からはなぜか5ちゃんだけがアーカイブできなくなってしまった
回線変えたり接続し直したりvpnかましたり何度もリトライしてみたり色々やったら何とかできたスレもあるけどできないスレはどうやってもダメだ…謎 ここ数日やっぱ調子悪いな〜古いアーカイブ確認出来ない また5ちゃん保存できるようになったわ
なんだったんだろう pcからの利用なのに時々sp用ページになるのが地味にストレス またアーカイブできない事がよく起きるようになった
5ちゃんだけじゃなくて他のサイトでもできなかったりたまにできたり…
不安定なのかな ここ3~4日はアーカイブまともに取得できなくて厳しいは
ウェブアーカイブじゃないと正しく取得出来ない所あるのに・・・ SavePageNowのクッションページが頻繁に表示される ステータスコード200以外でリトライするスクリプト組んで放置してたら400capturesとかになって笑ってる クッションページ、画面は同じでURLに日付が入ってるやつと入ってないやつがあるっぽい。 Internet Archive のファイルアップロード機能、あれを使うと
ユーザ登録に使っているメールアドレスが漏れるなぁ。
例としてこのファイルを挙げる。
https://archive.org/details/Pbtestfilemp4videotestmp4
右側の SHOW ALL のリンクからファイル一覧を開き、
ファイル名末尾が _meta.xml のファイルを見てみると、
<uploader> 要素の中にメールアドレスが記載されている。
元のページに戻り、Uploaded by で示されているアップロード者の
プロフページに入ってみる。
プロフのアバター画像は IA に直接アップロードすることもできるが、
この人はそれを行っていないため Gravatar の画像が参照されている。
Gravatar の画像 URL には、メールアドレスの MD5 ハッシュ値が含まれる。
先の XML から得たメールアドレスについて MD5 を取ってみると、双方の値が一致。
(大文字等を含むアドレスは一定の加工が必要だが、この例では無関係。)
つまり、XML から得たメールアドレスはユーザの登録アドレスで間違いない。
単に IA にユーザ登録を行ってプロフを持っているだけの状態からは
色々探してみたけど漏れっぽいものは見つからなかった。
ただアバター画像が初期状態のままだとメールアドレスのハッシュ値が
判るので、そこから他所で紐付けされてしまうことはあると思う。 >>897
それは本人のアドレスで間違ってない、数年前からセキュリティ面で指摘されてる。
念のために言うと漏れてるんじゃなくて、アーカイブの証明の為に記載してると思うけどね。
「アーカイブ」である以上何らかの本人確認は必要なので。 >>898
やはり既出だったか。
メタ情報として「誰がアップロードしたか」を記録しておく必要が
あるのは解るが、こういう形で出てしまうのは「漏れる」と表現したいなぁ。
システム上でユーザ名を名乗らせておきながら、どうしてメアドで記録してしまうのか。
ユーザ名は「一度使用した名前は二度と再利用させない」
(一度変えたら元に戻すことすらできない) なんてロックを掛けたりしているので
こちらの方が重要な識別子なのかと思ったけど、そういう訳では無いんだな。 >>900
Browser crashed visiting URL
chrome使いだが、ここ数日でよく見るようになったな。
かといって何回も取ったら、後になって「何でこんな大量?」ってなりそうだから、
マーキング感覚で、1〜2回で留めるしかないのか。 tamperだかgreaseだかでリトライし続けるようにすればいつかアーカイブされるし… アーカイブ出来てないように見えて後日チェックしてみるとアーカイブされてたってのはある
チェックしてみろ /save/で保存してapiで確認して取れてなかったらもっかい保存 最近APIも反映が遅くてな・・・
まぁ一定周期で重くなるのはいつもの事だし、気長に待つけども save outlinksにチェックを入れて保存しようとすると↓みたいなエラーになるな。
ttp://2chan.tv/jlab-long/s/long200126211024.png
まぁ、今朝の9時から18時前位まで全く保存が効かなかったからそれよりはマシだけどさ… save outlinksなしでもJob failed
26日から なんか玉葱経由で保管させると後でアーカイブが消されてるような気がするけど
気のせいかな。
 Twitterの仕様変更のせいかアーカイブ出来なくなってしまった save outlinksにチェック入れて保存するもリンク先が記録できず
Twitterの仕様変更のせいかアーカイブ出来なくなってしまった save outlinksにチェック入れて保存するもリンク先が記録できず
今日でサービス終了するサイトなんで頼む… 保存時にエラーっぽい表示はなかったし
saveしたページ自体はもう反映されてるが、そのリンク先だけ見れないのでタイムラグだとしても妙
かといってもう一回叩くのも負荷になるしやめたい 試しにもう一回やったらsave outlinksにチェック入れてるのにそのページしか保存してないorz Save error pages抜きとsave outlinksチェックは両立しない?? >>917
IAが苦手な形式になったから無理だと思う
download elementsを見ると画像とかは取れてるみたいだが・・・ TwitterはmegalodonやArchive.todayの方がまだ取りやすい気がしてきた
>>918
苦手な形式になったってどういうことなんや
詳しく教えてくれないか todayの方だと普通に取れるね>Twitter
謎だ save outlinksが無くなってる…
ttp://2chan.tv/jlab-long/s/long200203211629.png Wayback はサインイン(ログイン)しないと
スクリーンショットが取れない仕様に改変された。
ヤフーニュースの魚拓を取るときには注意しよう。 Firefox で general.useragent.override に
Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; .NET4.0E; .NET4.0C; .NET CLR 3.5.30729; .NET CLR 2.0.50727; .NET CLR 3.0.30729; Tablet PC 2.0; rv:11.0) like Gecko
と入れてやってみたら、こんな感じ↓。
http://web.archive.org/web/20200207033245/twitter.com/TwitterJP/status/1224802584650584064
https://twitter.com/5chan_nel (5ch newer account) >>930 の User-Agent、たまたま拾ったのがこの文字列だっただけなので
Internet Explorer と判定されるような内容なら何でも良いと思う。 最初からgeneral.useragent.override.web.archive.orgに入れっぱなしでもいいのかも なぜかInternet Explorer経由でないとTwitterのアーカイブが取れないのね 別に何故かでもないんだけど今後IAはこういうのどうするのかな なんかTwitter何も対策せずに取れるようになってるな
要望が多かったんだろうか? アマゾンは無関係
テストスレと間違えて追加してしまった失礼 なんかToo Many Requestsの判定おかしくないか?
明らかに上限に達してないのにブロックされるんだが 要求間隔が短すぎると弾かれる。
少しあければ5分経ってなくても返ってくる。 気持ち悪いくらいサクサク応答するな
今のうちにいろいろやっておくべきか >>941
ありがとう
今見たらアーカイブ自体が消えていたから取り直したら見れた 20年以降に保存したのが見えないのか消えてんのか知らんけど
最後に保存したのが2019のものになってんな 消えてないのもあるな
向こうでメンテか何かやってるだけか 魚拓音痴の質問もいいのかな…
魚拓の確認でカレンダーを開いた時に緑丸のページは絶対に見れない仕様ですか?
自分で調べたら緑丸=リダイレクトはわかったのですが緑丸を見る方法が見つからなくて書き込みました
初心者過ぎる質問で申し訳ないです 申し訳ないんだが「緑丸のページを見る」ってのが何を言いたいのかよく分からない
リダイレクト先のページがWayback Machineに保存されてたら見れるし、保存されてなかったら見れない、という仕様のはずだけど Yahooみたいなページの話なら
JavaScript無効化すれば見れるはず >>953
ダメみたいです
スマホで閲覧してるのですがjavasScriptをオフにしても特に変化はありませんでした
因みに調べているのはbekkoameというサイトです リダイレクト応答のコンテントボディが見たいとか、
そんなニッチな話かと思ったけどどうやら違うようだ・・・。
そもそもリダイレクトがどういうものか、質問者氏は理解されていますか。
他の URL を提示して「代わりにここを見よ」と指示するものですから、
リダイレクト自体にそれ以上の内容はありません。
Internet Archive のカレンダで緑色で表示されている、つまり
クロール時にリダイレクトが返された旨記録されているアーカイブを
開くと、数秒後にその当時リダイレクト先として示されていた URL の
アーカイブの読み込みが始まります。
いくらリダイレクト先として示されていたからと言っても、所詮は別の URL です。
当該 URL が Internet Archive にアーカイブされているかどうかは、
元の URL がアーカイブされていることとはあまり関係がありません。 /save/ではなくて/web/2/でもToo Many Requestsが出るようになったっぽいね Summaryタブがあるドメインと無いドメインの違いって何なんだろ?
数年経ってるのに無いのもあれば、半年程度であるドメインもあるし
取得数って訳でも無さそうだしなぁ・・・ 画像とかアーカイブするときのプログレスバー消えた? なんか保存にすごく時間がかかる...
どうなってんだ The same snapshot had been made 38 seconds ago.
↑これ出てるのにAPIでは保存されていないことになってる
/save/でも保存できないし、できるのは保存済みアーカイブの閲覧だけか >>965
いまどきアゴ勇のステマをやる人がいるとは! 昨日アーカイブしてさらに数時間後に確認もしたのに
今日になったらアーカイブされていないことになってる
やり直したらFirst Archiveとなって確認してもちゃんとアーカイブできてるのだが
明日は消えていそう >昨日アーカイブしてさらに数時間後に確認もしたのに
>今日になったらアーカイブされていないことになってる
https://web.archive.org/の事なら俺もまったく同じ状態
http://archive.fo/は問題なかったけど、昨晩から使えなくなって保存中の画面になったまま終わらない 【保存・記録】ウェブアーカイブ総合 Page.01
2020/02/25(火) 23:55:53.96 ID:jlsY//Cy0
>>345
Internet Archiveはアーカイブ実行用クローラ(Heritrix)と
保存したアーカイブの専用ビューワ(Wayback)を組み合わせて動いてるんで、
保存したアーカイブがサーバ不調で一時的に見られなくなってても、
アーカイブさえきちんと出来てればそのうち問題なく見られるようになる cube newsの単純な構造なら動画も一緒に保存できるっぽい 調子悪いですねぇ。
 APIおかしい
APIおかしい
大昔のキャプチャがちゃんとあるのに、APIでは保存されていないことになってる。 >>979
Internet Archiveが無料で色々な本を公開したからアクセス増えてキャパオーバーした可能性あるね >>983
乙
テンプレの二つの Q&A は永久保存ですかw
2011 年夏の UTF-8 化以降意味を成さなくなってますが。 >>984
テンプレはとりあえずそのままにしただけです
4スレ目以降はQ&Aちゃんと整理しなくては インターネット・アーカイブの無料電子書籍貸し出しに著者団体が抗議
https://hon.jp/news/1.0/0/29039
インターネット・アーカイブ(Internet Archive)は先月24日、
140万冊のEブックが読める「National Emergency Library」
をオープンし6月末までをめどにユーザーが1人10冊まで借りて
読むことができるようにしたが著者団体が反対の声を上げている。 https://web.archive.org/web/20200324005017/http://www.mynewsjapan.com/
> 現在メンテナンス中です
> 現在、アクセス妨害行為によって、サイトにアクセスできない状況となり、
> ご不便をおかけしております。何者かが業務妨害をしている模様です。
> 警察庁サイバー犯罪対策班が犯人を逮捕次第、詳細にご報告します。
> 万全を期すため、一時的に停止して、安全を確認しております。
> 対策のうえ、早々に復旧しますので少々お待ちください。
> My News Japan 半年以上前に保存されてたページを保存しなおしたら何故かFirst Archiveになった 埋め
調子悪いの直らないねぇ
コロナでスタッフも休んでるんだろうか このスレッドは1000を超えました。
新しいスレッドを立ててください。
life time: 1287日 23時間 4分 22秒 5ちゃんねるの運営はプレミアム会員の皆さまに支えられています。
運営にご協力お願いいたします。
───────────────────
《プレミアム会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
月300円から匿名でご購入いただけます。
▼ プレミアム会員登録はこちら ▼
https://premium.5ch.net/
▼ 浪人ログインはこちら ▼
https://login.5ch.net/login.php レス数が1000を超えています。これ以上書き込みはできません。







