なんだかんだでお世話になってるInternet Archiveについて語りましょう
Internet Archive
http://archive.org/
インターネット・アーカイブ - Wikipedia
http://ja.wikipedia.org/wiki/InternetArchive
------------------
Twitter
https://twitter.com/internetarchive/
関連スレ
【保存・記録】ウェブアーカイブ総合 Page.01
https://mevius.5ch.net/test/read.cgi/internet/1554553882/
前スレッド
Internet Archive総合 (web.archive.org) #4
https://mevius.5ch.net/test/read.cgi/esite/1628793497/
https://twitter.com/5chan_nel (5ch newer account)
Internet Archive総合 (web.archive.org) #5
レス数が1000を超えています。これ以上書き込みはできません。
1名無しさん@お腹いっぱい。
2023/07/28(金) 06:58:53.372名無しさん@お腹いっぱい。
2023/07/28(金) 07:00:04.50 【QA】
Q.Internet Explorerで日本語などの2byte言語のページのWeb Archiveキャッシュを見ようとしても
真っ白なページ&文字化けが起きる&極端に重いなどの症状が出てしまう
A.[表示]もしくは右クリック→[エンコード]→[日本語(自動選択)]やその言語の文字コードに則したものをクリック
Q.Web Archiveでダウンロードしたzipなどが開けない&CRCが違うと表示される
A.よくWeb Archiveは1byte欠けを起こすのでバイナリエディタなどで該当ファイルを開き、
16進数の最後の末尾に「00」を付加すると正常なファイルになることがあります。
Q.寄付したいんだけど?
こちらから金額,一度きりか毎月か,送金方法を選んで寄付してください
https://archive.org/donate
Q.すぐに保存したい場合は?
Save Page NowにURLを入力して「SAVE PAGE」ボタンを押す
https://web.archive.org/save/
Q.アカウント作ったらなんかいいことあるの?
A.ページのスクリーンショットを保存したり、ページの全てのリンク先を保存できる「Save outlinks」という機能が使える
Q.spn@archive.orgにメールでURLを送ったら保存されるの?
A.1週間後に保存完了のメールが届いたり、何も戻ってこない失敗した場合があるので、確実に保存したいなら辞めたほうがいい
Q.Internet Explorerで日本語などの2byte言語のページのWeb Archiveキャッシュを見ようとしても
真っ白なページ&文字化けが起きる&極端に重いなどの症状が出てしまう
A.[表示]もしくは右クリック→[エンコード]→[日本語(自動選択)]やその言語の文字コードに則したものをクリック
Q.Web Archiveでダウンロードしたzipなどが開けない&CRCが違うと表示される
A.よくWeb Archiveは1byte欠けを起こすのでバイナリエディタなどで該当ファイルを開き、
16進数の最後の末尾に「00」を付加すると正常なファイルになることがあります。
Q.寄付したいんだけど?
こちらから金額,一度きりか毎月か,送金方法を選んで寄付してください
https://archive.org/donate
Q.すぐに保存したい場合は?
Save Page NowにURLを入力して「SAVE PAGE」ボタンを押す
https://web.archive.org/save/
Q.アカウント作ったらなんかいいことあるの?
A.ページのスクリーンショットを保存したり、ページの全てのリンク先を保存できる「Save outlinks」という機能が使える
Q.spn@archive.orgにメールでURLを送ったら保存されるの?
A.1週間後に保存完了のメールが届いたり、何も戻ってこない失敗した場合があるので、確実に保存したいなら辞めたほうがいい
3名無しさん@お腹いっぱい。
2023/07/28(金) 07:00:23.53 Q.インスタのURLが保存できないんだけど
A.ログインしないとコンテンツが表示されない仕様になったので保存自体が無理になってます
Q.robots.txtでia_archiverをDisallowしても無視されるの?
A.中古ドメインでサイト見れなくするやつのせいでrobots.txtを見ない仕様になったので無視されることも従うこともある。保存できることもあるので確認してみたほうが早い
Q.鯖落ちしてる?
A.ここで鯖状態を見れる
https://analytics0.archive.org/stats/wb.php
https://archive.org/stats/
Q.Temporarily Offline The Internet Archive's sites are temporarily offline. We apologize for the inconvenience. って何?
A.たまにメンテやってサイト見れなくなることがあるので、待ちましょう。ツイッター(@InternetArchive)でメンテ予告は発表しています
Q.Save Page Nowの制限などの仕様は?
A.ここを参照
https://docs.google.com/document/d/1Nsv52MvSjbLb2PCpHlat0gkzw0EvtSgpKHu4mk0MnrA/edit
Q.Save Page Nowで保存完了しても保存されたページが表示されないんだけど
A.完全にページが見れるようになるのと、/*/のページ一覧やカレンダーに反映されるまで時間かかるので最大数日待ってください
ほとんどは数分後には見えるようになってるはず、もしくはウェブブラウザのキャッシュを削除するといいかも
A.ログインしないとコンテンツが表示されない仕様になったので保存自体が無理になってます
Q.robots.txtでia_archiverをDisallowしても無視されるの?
A.中古ドメインでサイト見れなくするやつのせいでrobots.txtを見ない仕様になったので無視されることも従うこともある。保存できることもあるので確認してみたほうが早い
Q.鯖落ちしてる?
A.ここで鯖状態を見れる
https://analytics0.archive.org/stats/wb.php
https://archive.org/stats/
Q.Temporarily Offline The Internet Archive's sites are temporarily offline. We apologize for the inconvenience. って何?
A.たまにメンテやってサイト見れなくなることがあるので、待ちましょう。ツイッター(@InternetArchive)でメンテ予告は発表しています
Q.Save Page Nowの制限などの仕様は?
A.ここを参照
https://docs.google.com/document/d/1Nsv52MvSjbLb2PCpHlat0gkzw0EvtSgpKHu4mk0MnrA/edit
Q.Save Page Nowで保存完了しても保存されたページが表示されないんだけど
A.完全にページが見れるようになるのと、/*/のページ一覧やカレンダーに反映されるまで時間かかるので最大数日待ってください
ほとんどは数分後には見えるようになってるはず、もしくはウェブブラウザのキャッシュを削除するといいかも
4名無しさん@お腹いっぱい。
2023/07/28(金) 07:01:15.35 Q.「The capture is estimated to start in XX minutes.」って何?
A.Save Page Nowの保存サーバーの空きがなくて保存処理に時間がかかってる状態、急いでなければあとでやるのも手
Q.The same snapshot had been made XX minutes and XX seconds ago. We only allow new captures of the same URL every XX minutes.
A.同じURLを短期間の間に何度も保存できない仕様になっています、誰かが数分前に保存したか、自分で保存したときに一部の画像がかけて保存されている状態でも表示されることがあります
気になるなら1時間後ぐらいにもう一度保存してください
Q.The server didn't respond in time for https://(保存しようとしたURL)
A.極端にページの返答が遅いサイトを保存しようとするとこの表示が出ます、何度かやれば保存できることもあります
Q.「You have already reached the limit of active sessions」が出た
A.同じIPアドレスからの同時保存制限に引っかかってる状態。2021年5月24日以降はログインしていないユーザーは同時保存は3個まで。1分ほど待てば制限解除される
Q.「This URL has been already captured 10 times today. Please email us at "info@archive.org" if you would like to discuss this more.」が出た
A.1日に同じURLは10回まで保存できる制限に達したので、また明日(UTC)
A.Save Page Nowの保存サーバーの空きがなくて保存処理に時間がかかってる状態、急いでなければあとでやるのも手
Q.The same snapshot had been made XX minutes and XX seconds ago. We only allow new captures of the same URL every XX minutes.
A.同じURLを短期間の間に何度も保存できない仕様になっています、誰かが数分前に保存したか、自分で保存したときに一部の画像がかけて保存されている状態でも表示されることがあります
気になるなら1時間後ぐらいにもう一度保存してください
Q.The server didn't respond in time for https://(保存しようとしたURL)
A.極端にページの返答が遅いサイトを保存しようとするとこの表示が出ます、何度かやれば保存できることもあります
Q.「You have already reached the limit of active sessions」が出た
A.同じIPアドレスからの同時保存制限に引っかかってる状態。2021年5月24日以降はログインしていないユーザーは同時保存は3個まで。1分ほど待てば制限解除される
Q.「This URL has been already captured 10 times today. Please email us at "info@archive.org" if you would like to discuss this more.」が出た
A.1日に同じURLは10回まで保存できる制限に達したので、また明日(UTC)
5名無しさん@お腹いっぱい。
2023/07/28(金) 07:01:22.75 Q.「This URL has been excluded from the Wayback Machine. 」って何?
A. robots.txtのブロックや、サイトの運営者や著作権者がドメインやこのディレクトリごと非表示化の申請をした可能性があります、
ただしURLの保存はできますし、将来的にブロックが解除されて見れるようになる可能性もあります
Q.「Cannot get status of spn2-乱数」のエラーは何?
A.Save Page Nowで保存中にサーバーの状態が取得できなかったときのエラーで、/*/で保存されているか確認して、されてなければもう一度保存してください
Q.「404 Not Found」のエラーは何?
A.サイトが存在していてもこのエラーが出ることがあります。その場合は時間あけて一度保存してみましょう
Q.「Sorry Job failed」が出た
A.このエラーが出たとしても一部画像やスクリプトファイルが欠けた状態でページ保存できていることがありますので、/*/で確認してみてください
保存できてない場合はやり直してください
A. robots.txtのブロックや、サイトの運営者や著作権者がドメインやこのディレクトリごと非表示化の申請をした可能性があります、
ただしURLの保存はできますし、将来的にブロックが解除されて見れるようになる可能性もあります
Q.「Cannot get status of spn2-乱数」のエラーは何?
A.Save Page Nowで保存中にサーバーの状態が取得できなかったときのエラーで、/*/で保存されているか確認して、されてなければもう一度保存してください
Q.「404 Not Found」のエラーは何?
A.サイトが存在していてもこのエラーが出ることがあります。その場合は時間あけて一度保存してみましょう
Q.「Sorry Job failed」が出た
A.このエラーが出たとしても一部画像やスクリプトファイルが欠けた状態でページ保存できていることがありますので、/*/で確認してみてください
保存できてない場合はやり直してください
6名無しさん@お腹いっぱい。
2023/07/28(金) 07:01:40.39 便利なツール
https://github.com/webrecorder/webrecorder-player/
https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server#query-result-limits
https://github.com/hartator/wayback-machine-downloader
https://github.com/overcast07/wayback-machine-spn-scripts
https://github.com/akamhy/waybackpy
https://github.com/JustAnotherArchivist/snscrape
https://github.com/bibanon/tubeup
https://github.com/webrecorder/webrecorder-player/
https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server#query-result-limits
https://github.com/hartator/wayback-machine-downloader
https://github.com/overcast07/wayback-machine-spn-scripts
https://github.com/akamhy/waybackpy
https://github.com/JustAnotherArchivist/snscrape
https://github.com/bibanon/tubeup
7名無しさん@お腹いっぱい。
2023/07/28(金) 07:01:55.63 拒否URL関係まとめ
This URL has been excluded from the Wayback Machine.
https://note.com/
https://gigazine.net/
https://boards.4channel.org/
https://bokete.jp/
https://yoshidakenkou.net/
https://tanteifile.com/
https://motherless.com/
https://www.lancers.jp/
This URL is in our block list
https://finance.yahoo.co.jp/brokers-hikaku/ 以下全て
https://movie.eroterest.net/
https://anime.eroterest.net/
サイトの仕様で取れないもの
https://ch.dlsite.com/matome 記事本文が取得不可、todayなら取れる
https://www.pixiv.net/ 投コメのみ取得可、todayなら取れる
ArchiveTeamのexcludedまとめ
https://wiki.archiveteam.org/index.php/List_of_websites_excluded_from_the_Wayback_Machine
This URL has been excluded from the Wayback Machine.
https://note.com/
https://gigazine.net/
https://boards.4channel.org/
https://bokete.jp/
https://yoshidakenkou.net/
https://tanteifile.com/
https://motherless.com/
https://www.lancers.jp/
This URL is in our block list
https://finance.yahoo.co.jp/brokers-hikaku/ 以下全て
https://movie.eroterest.net/
https://anime.eroterest.net/
サイトの仕様で取れないもの
https://ch.dlsite.com/matome 記事本文が取得不可、todayなら取れる
https://www.pixiv.net/ 投コメのみ取得可、todayなら取れる
ArchiveTeamのexcludedまとめ
https://wiki.archiveteam.org/index.php/List_of_websites_excluded_from_the_Wayback_Machine
8名無しさん@お腹いっぱい。
2023/07/28(金) 07:02:57.18 アーカイブ済のURL一覧を出力する方法
1. http://web.archive.org/cdx/search/cdx?url=example.com*&;output=txt にアクセス
2. example.comのところをアーカイブしたページのトップページURLに変える。*を誤って消さないようにすること
3. 大量のテキストが出るので全選択してコピー
4. Excel立ち上げてCtrl+Aで全選択して貼り付け
5. 「テキストから列へ」を選んでスペースを基準にセルを区切る
6. セル列のアルファベット文字をクリックしたらその列が全選択になるからURLの列をコピーしてテキストエディタに貼り付けるなりする
同じURLでも保存した時間分の数書いてあるから置換ツールで重複した行を消すこと
IAのURLsでは10000個までしか表示できないがこの方法使ってアーカイブされたURLの正確な総数がわかるはず
WEB版のExcelだと貼り付け時に容量オーバーで受け付けてくれないことがあるからその場合はLibreOffice Calcでも使えばいい
LibreOfficeの場合貼り付け後、表全体の全選択を解除し、1回セルAをクリックしてセルAを全選択した後、データ→テキストから列へ を選ぶことでセル分け可能
引用元: https://exposureninja.com/blog/extract-urls-archive-org/
https://mevius.5ch.net/test/read.cgi/esite/1628793497/332
1. http://web.archive.org/cdx/search/cdx?url=example.com*&;output=txt にアクセス
2. example.comのところをアーカイブしたページのトップページURLに変える。*を誤って消さないようにすること
3. 大量のテキストが出るので全選択してコピー
4. Excel立ち上げてCtrl+Aで全選択して貼り付け
5. 「テキストから列へ」を選んでスペースを基準にセルを区切る
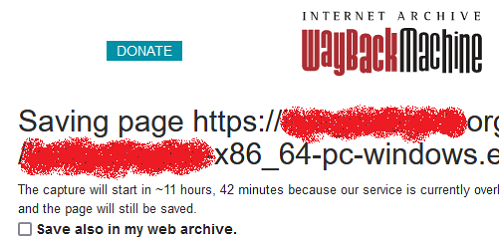
6. セル列のアルファベット文字をクリックしたらその列が全選択になるからURLの列をコピーしてテキストエディタに貼り付けるなりする
同じURLでも保存した時間分の数書いてあるから置換ツールで重複した行を消すこと
IAのURLsでは10000個までしか表示できないがこの方法使ってアーカイブされたURLの正確な総数がわかるはず
WEB版のExcelだと貼り付け時に容量オーバーで受け付けてくれないことがあるからその場合はLibreOffice Calcでも使えばいい
LibreOfficeの場合貼り付け後、表全体の全選択を解除し、1回セルAをクリックしてセルAを全選択した後、データ→テキストから列へ を選ぶことでセル分け可能
引用元: https://exposureninja.com/blog/extract-urls-archive-org/
https://mevius.5ch.net/test/read.cgi/esite/1628793497/332
2023/07/28(金) 07:25:43.19
>>1おつ
Internet Archive総合 (web.archive.org) #2
https://mevius.5ch.net/test/read.cgi/esite/1475246713/5
5 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2016/10/01(土) 04:24:53.46
テンプレのQ&A二件、まだそんなやり方が通用すると思ってる奴いるの?
Internet Archive総合 (web.archive.org) #2
https://mevius.5ch.net/test/read.cgi/esite/1475246713/5
5 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2016/10/01(土) 04:24:53.46
テンプレのQ&A二件、まだそんなやり方が通用すると思ってる奴いるの?
10名無しさん@お腹いっぱい。
2023/07/28(金) 16:21:28.75 おつでありんす
11名無しさん@お腹いっぱい。
2023/07/28(金) 19:06:10.70 todayだとヤフーニュースが保存できなくなってる
だからInternet Archiveで保存することが増えた
慶応vs横浜だけじゃない…甲子園目指す球児とファンを悩ます高校野球「パイア問題」とは?
news.yahoo.co.jp/profile/comments/55eb7cbd-6f69-41ed-ab91-6d7a3ebd5d16
だからInternet Archiveで保存することが増えた
慶応vs横浜だけじゃない…甲子園目指す球児とファンを悩ます高校野球「パイア問題」とは?
news.yahoo.co.jp/profile/comments/55eb7cbd-6f69-41ed-ab91-6d7a3ebd5d16
12名無しさん@お腹いっぱい。
2023/07/28(金) 19:09:18.35 私も19年前鹿児島県大会の夏、三塁塁審の誤審により三点本塁打となり高校野球を終えました。
主将を務めていた私は何度も三塁塁審へ抗議にいきましたが、塁審は「私が間違う訳がない」の一点張り。
その日に放送されたニュースでもしっかりファウルである映像が映し出されましたが判定が覆ったわけでもなく、
むしろその誤審をした審判は今や鹿児島県高野連の審判長まで登り詰めております。
ただ試合後主審の方が私を呼び出し、「審判も人間だから間違うときもあるからね」と声を掛けられました。
誰が見てもわかる誤審であっても審判長にまで登りつめるためには誤審を認めるわけにはいかない、
審判の方々も会社と一緒でそういったなかでされていて大変なのかもしれないとこの歳になって少しわかってきました。
todayでも↑のコメントを保存したかったなあ…
主将を務めていた私は何度も三塁塁審へ抗議にいきましたが、塁審は「私が間違う訳がない」の一点張り。
その日に放送されたニュースでもしっかりファウルである映像が映し出されましたが判定が覆ったわけでもなく、
むしろその誤審をした審判は今や鹿児島県高野連の審判長まで登り詰めております。
ただ試合後主審の方が私を呼び出し、「審判も人間だから間違うときもあるからね」と声を掛けられました。
誰が見てもわかる誤審であっても審判長にまで登りつめるためには誤審を認めるわけにはいかない、
審判の方々も会社と一緒でそういったなかでされていて大変なのかもしれないとこの歳になって少しわかってきました。
todayでも↑のコメントを保存したかったなあ…
2023/07/29(土) 03:23:34.53
盲人でも野球の審判を業務として行えるという実例ですね
14名無しさん@お腹いっぱい。
2023/07/29(土) 14:34:01.29 twitterのプロフィールはwaybackmachineで保存できなくなった
個別のツイートは保存できるけど、コメント欄は保存できないし、いろいろ改悪されたなあ
個別のツイートは保存できるけど、コメント欄は保存できないし、いろいろ改悪されたなあ
2023/07/31(月) 10:26:16.62
tubeupでひたすらサムネイルだけ上げてる奴って何が目的なんだ?
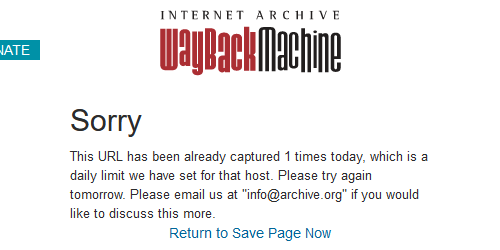
他の人がアップロード出来なくなるから普通に迷惑なんだが
他の人がアップロード出来なくなるから普通に迷惑なんだが
16名無しさん@お腹いっぱい。
2023/08/01(火) 12:14:52.09 ニコニコとかYouTubeってarchiveで保存しても動画再生出来ないの?
17名無しさん@お腹いっぱい。
2023/08/01(火) 14:26:51.272023/08/02(水) 11:49:36.01
2023/08/02(水) 14:26:37.14
動画サイトが動画直リン保存すればいける場合もあんのか
2023/08/04(金) 14:12:38.34
またTwitterのプロフィール取れなくなってるわ
あのさぁ・・・
あのさぁ・・・
2023/08/05(土) 21:26:33.08
あれ?また取れるようになってるな
非ログイン状態でも見れるプロフィールと見れないやつがある?
条件が分からん
非ログイン状態でも見れるプロフィールと見れないやつがある?
条件が分からん
23名無しさん@お腹いっぱい。
2023/08/06(日) 01:13:10.24 なんかtwitterのプロフィール保存すると、過去ツイがランダムに表示されるだけで、最新のツイートが保存されてない。
もう訳わからんわw
もう訳わからんわw
2023/08/07(月) 10:27:43.52
archive.orgって画像複数を一括保存とか出来る?
いちいち一つずつURL入力保存しないといけないの?
いちいち一つずつURL入力保存しないといけないの?
2023/08/07(月) 10:37:01.96
>>24
API が公開されているから、画像に限らずそれ利用するスクリプトを組めばよい。
https://docs.google.com/document/d/1Nsv52MvSjbLb2PCpHlat0gkzw0EvtSgpKHu4mk0MnrA/edit
API が公開されているから、画像に限らずそれ利用するスクリプトを組めばよい。
https://docs.google.com/document/d/1Nsv52MvSjbLb2PCpHlat0gkzw0EvtSgpKHu4mk0MnrA/edit
2023/08/08(火) 07:22:55.57
>>24
Have you ever wanted to archive all the web pages linked from an email message?
Well, you are in luck because now you can forward that email to savepagenow@archive.org”
and after a few minutes you will get an email back filled with Wayback Machine playback URLs.
Have you ever wanted to archive all the web pages linked from an email message?
Well, you are in luck because now you can forward that email to savepagenow@archive.org”
and after a few minutes you will get an email back filled with Wayback Machine playback URLs.
2023/08/08(火) 12:31:37.42
>>7
>
> サイトの仕様で取れないもの
> https://ch.dlsite.com/matome 記事本文が取得不可、todayなら取れる
> https://www.pixiv.net/ 投コメのみ取得可、todayなら取れる
>
↑今春までならtodayで取った完全アーカイブをarchive.orgへ再取り出来たんだが拒否URLにされたのか弾かれるようになってしまった。。
>
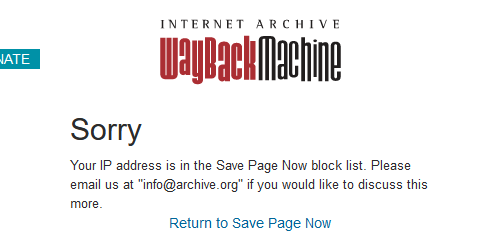
> サイトの仕様で取れないもの
> https://ch.dlsite.com/matome 記事本文が取得不可、todayなら取れる
> https://www.pixiv.net/ 投コメのみ取得可、todayなら取れる
>
↑今春までならtodayで取った完全アーカイブをarchive.orgへ再取り出来たんだが拒否URLにされたのか弾かれるようになってしまった。。
2023/08/08(火) 12:46:26.56
前スレ埋まってないんだから前スレに書きなよ
29名無しさん@お腹いっぱい。
2023/08/10(木) 00:08:00.56 dclogもサービス終了
2023/08/10(木) 06:52:14.96
>>29
終了告知から終了まで1か月もないとはひどいサービスだな
終了告知から終了まで1か月もないとはひどいサービスだな
2023/08/13(日) 02:05:43.24
音楽レーベル、デジタル化されたレコードコレクションをめぐりインターネット・アーカイブを提訴
https://www.reuters.com/legal/music-labels-sue-internet-archive-over-digitized-record-collection-2023-08-12/
https://www.reuters.com/legal/music-labels-sue-internet-archive-over-digitized-record-collection-2023-08-12/
32名無しさん@お腹いっぱい。
2023/08/13(日) 18:25:16.62 Sheetsのbatch処理ここ数日ずっとqueuedのままや
そんなに使ってる人おるんか
そんなに使ってる人おるんか
2023/08/14(月) 01:51:11.53
archiveってpornhubとかエロ動画直リン保存ってしていいの?
2023/08/14(月) 05:36:17.08
2023/08/14(月) 13:55:59.20
>>31
日本語記事も出た
ソニーら音楽各社、著作権侵害でInternet Archiveを提訴。SPレコード2749作品以上をデジタル化・公開
https://www.techno-edge.net/article/2023/08/13/1742.html
日本語記事も出た
ソニーら音楽各社、著作権侵害でInternet Archiveを提訴。SPレコード2749作品以上をデジタル化・公開
https://www.techno-edge.net/article/2023/08/13/1742.html
2023/08/14(月) 19:47:23.54
>>33
internet archiveの規約を見た感じ特にルールは設けられてなさそうだけど、
archive teamによるとコンテンツが削除されたり、アカウントが凍結されたりする可能性はあるらしい
余談だけど、archive teamは元々ポルノはネット上で最も分散保存されているコンテンツだからアーカイブしないという方針だったんだけど
wikiの編集履歴確認したら、今年8月からは通常のコンテンツと同様の扱いにするという方針に切り替えたっぽいな
https://wiki.archiveteam.org/index.php/Porn
internet archiveの規約を見た感じ特にルールは設けられてなさそうだけど、
archive teamによるとコンテンツが削除されたり、アカウントが凍結されたりする可能性はあるらしい
余談だけど、archive teamは元々ポルノはネット上で最も分散保存されているコンテンツだからアーカイブしないという方針だったんだけど
wikiの編集履歴確認したら、今年8月からは通常のコンテンツと同様の扱いにするという方針に切り替えたっぽいな
https://wiki.archiveteam.org/index.php/Porn
37名無しさん@お腹いっぱい。
2023/08/16(水) 07:35:06.43 最近フラッシュのページのアーカイブ見るとruffleっていうSWFエミュレータが起動してフラッシュを再生してくれるようになったな
2023/08/17(木) 09:37:24.83
xtubeの動画のアーカイブもなんとかなりませんか
どうせどっかにあるんだろ
どうせどっかにあるんだろ
2023/08/21(月) 07:41:35.73
SPN2のAPIのドキュメントに、「anonymous user」って表記があるんだけど、anonymous でAPI叩くには何を指定すれば良いの?
authorizationヘッダを付けずにAPI呼ぶと、
"You need to be logged in to use Save Page Now."
ってエラーになっちゃう。
anonymousの制約で十分だから、APIキー無しで使いたいんだけどな
authorizationヘッダを付けずにAPI呼ぶと、
"You need to be logged in to use Save Page Now."
ってエラーになっちゃう。
anonymousの制約で十分だから、APIキー無しで使いたいんだけどな
2023/08/21(月) 17:51:35.50
>>39
それ、応答を HTML でも返せるところを
Accept ヘッダでわざわざ JSON 形式を要求すること自体が要アカウントっぽいんだよね。
どーしてまたそんな所に匿名ユーザ制限が入ってるのかは解らんけど。
それ、応答を HTML でも返せるところを
Accept ヘッダでわざわざ JSON 形式を要求すること自体が要アカウントっぽいんだよね。
どーしてまたそんな所に匿名ユーザ制限が入ってるのかは解らんけど。
2023/08/21(月) 22:43:21.39
現状のSPN2APIはよく分からん仕様が多くて「痒い所に手が届かない」感じなので
あまり深く考えない方がいい
あまり深く考えない方がいい
2023/08/22(火) 22:54:25.65
ヤフー知恵袋、SPNだと取れるのにoutlinksの方だけエラーになってるぽいな
43名無しさん@お腹いっぱい。
2023/08/23(水) 22:13:20.02 ここ最近自動でアーカイブされてないこと多いよな。
御叱りでも受けたか?
御叱りでも受けたか?
44名無しさん@お腹いっぱい。
2023/08/23(水) 22:15:20.98 >>14 イーロンの仕業か。
2023/08/24(木) 09:10:55.59
ここ数日やけに接続エラーが起きてると思ったらこれなんだよね。
スクリプトは当面 HTTP へ切り替えるかぁ。

スクリプトは当面 HTTP へ切り替えるかぁ。

2023/08/24(木) 18:22:24.75
2023/08/26(土) 03:04:26.70
久々に SPN2 API のドキュメントを見返していたら、
/save/ に新設のパラメータがあることに気づいたぁ。
use_user_agent=<XXX>
Use custom HTTP User-Agent value when capturing the target page.
2022-07-28 日付けの版で追加されてたのね。
/save/ に新設のパラメータがあることに気づいたぁ。
use_user_agent=<XXX>
Use custom HTTP User-Agent value when capturing the target page.
2022-07-28 日付けの版で追加されてたのね。
2023/08/26(土) 11:12:00.83
Sorry Job failed
と表示されるarchive.orgのページが保存される謎バグに遭遇して笑った
ただの表示バグだと思いたい
と表示されるarchive.orgのページが保存される謎バグに遭遇して笑った
ただの表示バグだと思いたい
49名無しさん@お腹いっぱい。
2023/08/28(月) 17:44:50.52 Atwikiってspn で取れなくなってる?
エラー吐いてる
エラー吐いてる
2023/08/28(月) 18:00:19.46
と、何のエラーか説明すらできない言語障碍児が申しております。


51名無しさん@お腹いっぱい。
2023/08/28(月) 18:12:11.36 おま環じゃなかったか
アニオタwiki消えそうだから保存しようとしたんだけどなー
Archiveboxで自分でwarc取るしかないか
センキュー
アニオタwiki消えそうだから保存しようとしたんだけどなー
Archiveboxで自分でwarc取るしかないか
センキュー
2023/08/28(月) 19:13:33.15
HTTP status=403
atwiki側が意図的に排除してる
エラー吐いてる、だけじゃ何もわからんな
atwiki側が意図的に排除してる
エラー吐いてる、だけじゃ何もわからんな
2023/08/28(月) 19:38:17.09
atwikiって前は取れた気がするけど
方針変えたのか?
方針変えたのか?
2023/08/28(月) 20:32:04.13
2023/08/29(火) 17:46:42.89
Googleだとなぜかhttpの方がインデックスされてるせいで繋がらないな
というかいい加減httpからhttpsに転送するようにして欲しい
というかいい加減httpからhttpsに転送するようにして欲しい
2023/08/31(木) 09:07:02.89
Internet Archive総合 (web.archive.org) #4
https://mevius.5ch.net/test/read.cgi/esite/1628793497/975
975 名前:名無しさん@お腹いっぱい。[] 投稿日:2023/07/24(月) 07:55:27.47
放置してたらURL8万行分集めてて、もう飽きたからこれアーカイブしてdatアーカイブやめます
保存されるやつみたら文字化けしてるし意味あるのかなといった感じでもある
普通の過去ログやる方が有意義におもう
↑エアプ野郎w
https://mevius.5ch.net/test/read.cgi/esite/1628793497/975
975 名前:名無しさん@お腹いっぱい。[] 投稿日:2023/07/24(月) 07:55:27.47
放置してたらURL8万行分集めてて、もう飽きたからこれアーカイブしてdatアーカイブやめます
保存されるやつみたら文字化けしてるし意味あるのかなといった感じでもある
普通の過去ログやる方が有意義におもう
↑エアプ野郎w
2023/08/31(木) 11:07:06.36
http://homepage2.nifty.com/J-R/enjoy%20pich.htm
↑のアーカイブを見ようと思ったら「This URL has been excluded from the Wayback Machine.」となってて、つまり除外設定されてるんだけど
これの理由(誰が、いつ申請したか)を知る事って出来る?
禁止しているドメインの一覧は多分↓なんだろうけど、このページ自体は2019年くらいから作られるし、リストに追記される理由とか何も書いてないから詳しくがわからん
https://wiki.archiveteam.org/index.php/List_of_websites_excluded_from_the_Wayback_Machine
個人が作るHPスペースをまるごと除外設定するのが通るのは、インターネットアーカイブの目的としてもちょっと勘弁して欲しいなあ
個人HPこそ後世に残したい
↑のアーカイブを見ようと思ったら「This URL has been excluded from the Wayback Machine.」となってて、つまり除外設定されてるんだけど
これの理由(誰が、いつ申請したか)を知る事って出来る?
禁止しているドメインの一覧は多分↓なんだろうけど、このページ自体は2019年くらいから作られるし、リストに追記される理由とか何も書いてないから詳しくがわからん
https://wiki.archiveteam.org/index.php/List_of_websites_excluded_from_the_Wayback_Machine
個人が作るHPスペースをまるごと除外設定するのが通るのは、インターネットアーカイブの目的としてもちょっと勘弁して欲しいなあ
個人HPこそ後世に残したい
2023/08/31(木) 22:19:54.68
2023/09/01(金) 02:04:41.12
>>58
多分このことじゃね?
https://web.archive.org/web/20230711093514/https://agree.5ch.net/operate/dat/1608930977.dat
多分このことじゃね?
https://web.archive.org/web/20230711093514/https://agree.5ch.net/operate/dat/1608930977.dat
2023/09/01(金) 06:24:58.23
スクリプト回してるのにim_とかid_とか知らないって嘘くせぇ
https://web.archive.org/web/20230711093514im_/https://agree.5ch.net/operate/dat/1608930977.dat
https://web.archive.org/web/20230711093514im_/https://agree.5ch.net/operate/dat/1608930977.dat
2023/09/01(金) 13:11:43.12
>>57
理由は公開されないけど基本的にサイトの管理者が除外申請した場合だね
確かにアーカイブの目的には反してるが、ここをしっかりしないと著作権侵害で突かれる可能性があるので
あとexcludedであってdeletedではないのでIAには残ってるはず、オンラインでアクセス不可になるだけ
理由は公開されないけど基本的にサイトの管理者が除外申請した場合だね
確かにアーカイブの目的には反してるが、ここをしっかりしないと著作権侵害で突かれる可能性があるので
あとexcludedであってdeletedではないのでIAには残ってるはず、オンラインでアクセス不可になるだけ
62名無しさん@お腹いっぱい。
2023/09/02(土) 07:00:06.31 YouTUbeの再生ページがアーカイブされるの遅過ぎだろ。
何やってんだよインターネットアーカイブに保存する人は!全然チェックされてないじゃん!
やる気あんのか?寝てたのか?
どうして誰も保存しないんだ?自動アーカイブはどうした?
https://www.youtube.com/watch?v=jjZEQ9Nocp4
https://www.youtube.com/watch?v=lnlyZlIRO1U
何やってんだよインターネットアーカイブに保存する人は!全然チェックされてないじゃん!
やる気あんのか?寝てたのか?
どうして誰も保存しないんだ?自動アーカイブはどうした?
https://www.youtube.com/watch?v=jjZEQ9Nocp4
https://www.youtube.com/watch?v=lnlyZlIRO1U
63名無しさん@お腹いっぱい。
2023/09/02(土) 07:42:50.72 YouTubeの再生ページがアーカイブされるのがかなり遅いケースがもう10か月以上も続いている。
公開から10時間後とか。
自動アーカイブはどうしたのか?
公開から10時間後とか。
自動アーカイブはどうしたのか?
2023/09/02(土) 13:11:42.88
5chをアーカイブしてもエラーページになる事が増えたなぁ
重くなってるのか?
重くなってるのか?
65名無しさん@お腹いっぱい。
2023/09/03(日) 18:03:57.56 一番上に書いてあるvideoとかmusicってなんですか?
いろいろありますけど保存してもいいんですかね?
いろいろありますけど保存してもいいんですかね?
2023/09/03(日) 19:52:30.07
昔と違い私的理由で使う人が多すぎて
ゴミ集積場化が止まらない
ゴミ集積場化が止まらない
2023/09/03(日) 22:28:57.02
68名無しさん@お腹いっぱい。
2023/09/04(月) 17:39:35.18 >>64
同感
たとえば「【文春砲】令和の米騒動、現場写真がリークされる」というスレッドも
8月31日の11:32:22は保存できているのに、それ以降はエラーが起きて保存されていない
web.archive.org/web/20230000000000*/https://nova.5ch.net/test/read.cgi/livegalileo/1693474206
同感
たとえば「【文春砲】令和の米騒動、現場写真がリークされる」というスレッドも
8月31日の11:32:22は保存できているのに、それ以降はエラーが起きて保存されていない
web.archive.org/web/20230000000000*/https://nova.5ch.net/test/read.cgi/livegalileo/1693474206
2023/09/05(火) 10:44:06.47
同じスレを何度も保存する意味あるの?
2023/09/05(火) 17:30:52.63
1000までいってないなら意味あるんじゃない
71名無しさん@お腹いっぱい。
2023/09/05(火) 20:42:01.45 もう「なんでも実況(ガリレオ)」板のスレは過去ログの魚拓とれないのかもな
【悲報】安倍晋三語録、「同意」を表すものが存在しない
nova.5ch.net/test/read.cgi/livegalileo/1693837620
IAではserver errorとなるしアーカイブトゥデイでも「Not Found (yet?)」となる → archive.is/I6WEN
【悲報】安倍晋三語録、「同意」を表すものが存在しない
nova.5ch.net/test/read.cgi/livegalileo/1693837620
IAではserver errorとなるしアーカイブトゥデイでも「Not Found (yet?)」となる → archive.is/I6WEN
2023/09/05(火) 23:40:36.69
昔の魚拓見ようにも重いのかエラー出るな
2023/09/06(水) 00:36:21.59
>>71
nova.5ch.net は 7 月から継続的に DDoS 攻撃を受けているサーバのうちの一つ。
その対応で、おそらく日本以外の IP 向けに L4 レベルのアクセス制限を掛けている。
https://agree.5ch.net/test/read.cgi/operate/1673084281/16-
nova.5ch.net は 7 月から継続的に DDoS 攻撃を受けているサーバのうちの一つ。
その対応で、おそらく日本以外の IP 向けに L4 レベルのアクセス制限を掛けている。
https://agree.5ch.net/test/read.cgi/operate/1673084281/16-
2023/09/06(水) 15:40:13.70
75名無しさん@お腹いっぱい。
2023/09/07(木) 17:59:45.87 【悲報】17歳の上玉白人美少女ちゃん、交通事故の罪で終身刑を言い渡される
nova.5ch.net/test/read.cgi/livegalileo/1693978274
このスレもサーバーエラーで魚拓とれなかったからグーグルのキャッシュ経由で魚拓とった
archive.li/pGUd4
nova.5ch.net/test/read.cgi/livegalileo/1693978274
このスレもサーバーエラーで魚拓とれなかったからグーグルのキャッシュ経由で魚拓とった
archive.li/pGUd4
2023/09/09(土) 08:46:02.23
家のWi-FiでCONNECTION REFUSEDしか出ないから試しに携帯回線につなぎ替えたら普通に繋がった。
手動で取ってただけでアク禁にされたのか
手動で取ってただけでアク禁にされたのか
2023/09/09(土) 09:07:31.51
2023/09/09(土) 22:32:08.21
>>76だけど半日くらいで解除されたっぽい
2023/09/10(日) 12:26:18.58
>>73-74
eggもエラー起きるな
eggもエラー起きるな
2023/09/12(火) 01:16:30.06
Twitterまた取れなくなってね?
2023/09/13(水) 01:14:09.55
前スレのころ20分ぐらいつながらないことがあったが、
それ以上に長くつながらない・・・
それ以上に長くつながらない・・・
2023/09/13(水) 07:16:08.88
81の件、ようやくつながった
83名無しさん@お腹いっぱい。
2023/09/14(木) 16:24:12.75 twitter、じゃなくてX取れなくなってるな
個別のポストはtodayの方で辛うじて取れるが
個別のポストはtodayの方で辛うじて取れるが
2023/09/15(金) 05:44:55.86
twitterで良くね
Xとか勝手に名称変えたアホ以外誰も言ってねえわ
Xとか勝手に名称変えたアホ以外誰も言ってねえわ
2023/09/15(金) 11:00:18.27
ジャスコ、ダイエー、サティ、ダイヤモンドシティ、イオン、
86archive.is/tTrQN
2023/09/15(金) 20:45:51.70 前スレ955への返信だがグーグルキャッシュなどを経由すれば
好き嫌いドットコムのコメント欄も魚拓とれる場合がある
webcache.googleusercontent.com/search?q=cache:syMmr8fOqbkJ:https://suki-kira.com/people
/result/%25E3%2582%2586%25E3%2581%259F%25E3%2581%25BC%25E3%2582%2593
好き嫌いドットコムのコメント欄も魚拓とれる場合がある
webcache.googleusercontent.com/search?q=cache:syMmr8fOqbkJ:https://suki-kira.com/people
/result/%25E3%2582%2586%25E3%2581%259F%25E3%2581%25BC%25E3%2582%2593
2023/09/18(月) 12:38:04.07
2023/09/19(火) 01:23:34.92
ツイートと付随する動画像をCSVでまとめて落とせる国産ツールない?
イーロンになってからアーカイブサイトにいれるだけじゃ不安だから、自前で持っておいて必要に応じてアップできるようにしたい
イーロンになってからアーカイブサイトにいれるだけじゃ不安だから、自前で持っておいて必要に応じてアップできるようにしたい
2023/09/20(水) 16:11:43.42
Batch process Google Sheetsがabort出来ないバグ何とかしてくれ
相手側に負荷がかかってたらどうすんだよ
相手側に負荷がかかってたらどうすんだよ
9089
2023/09/20(水) 16:18:49.76 やっと止まったわ、遅すぎ
91名無しさん@お腹いっぱい。
2023/09/21(木) 10:05:32.27 5ちゃんも有料化云々でヤバそうだし
スレアーカイブしといた方が良さそうだな…
そろそろ消えそうな予感
スレアーカイブしといた方が良さそうだな…
そろそろ消えそうな予感
2023/09/21(木) 13:38:51.45
いつ復旧するかなー


2023/09/23(土) 18:28:51.16
Attempts to archive this video failed.
はなんなんだよ
はなんなんだよ
94名無しさん@お腹いっぱい。
2023/09/24(日) 13:01:59.07 savepagenowを実行したあとにgoogleのサポートページ?に飛ばされるのはどういう仕様?
95名無しさん@お腹いっぱい。
2023/09/24(日) 14:22:50.44 twitterの記録取れなくなるのは将来に禍根を残すと思うわ。
数百年後に歴史を振り返った時にSNSは史料的な価値があると思う。
数百年後に歴史を振り返った時にSNSは史料的な価値があると思う。
2023/09/24(日) 18:43:53.30
今のツイッターって?failedScript=vendorつけても無理になったの?
2023/09/25(月) 18:24:55.68
フウーεε=( ~ε~ )y-゚゚゚
2023/09/29(金) 16:40:42.99
teacup. byGMOレンタル掲示板あんま残ってねえな
99名無しさん@お腹いっぱい。
2023/10/03(火) 16:40:59.85 もう5chの過去ログ課金しないと見れないっぽいね
2023/10/04(水) 10:45:27.46
>>99
現役鯖の分はまだ落ちてくるけどなぁ
https://mevius.5ch.net/esite/oyster/1628/1628793497.dat
/oyster/ 以下のディレクトリインデックスが掘れなくなってはいるが
現役鯖の分はまだ落ちてくるけどなぁ
https://mevius.5ch.net/esite/oyster/1628/1628793497.dat
/oyster/ 以下のディレクトリインデックスが掘れなくなってはいるが
2023/10/04(水) 14:13:19.96
Sorry
Cannot resolve host ipv6.icanhazip.com.
IPv6 の名前解決ができなくなってる
Cannot resolve host ipv6.icanhazip.com.
IPv6 の名前解決ができなくなってる
2023/10/05(木) 21:27:26.21
todayがちと重い
2023/10/07(土) 15:40:46.22
>>99
単純に重いだけじゃない?
単純に重いだけじゃない?
104名無しさん@お腹いっぱい。
2023/10/07(土) 18:44:36.46 今繋がらないんだけど、私だけですか?
105104
2023/10/07(土) 18:57:20.21 Wi-Fiに切り替えたら繋がった。
どうやらアク禁らしい。
普通に閲覧してただけだし、何も心当たりないんだけど…
どうやらアク禁らしい。
普通に閲覧してただけだし、何も心当たりないんだけど…
107104
2023/10/07(土) 23:17:39.682023/10/08(日) 11:31:56.88
人間レベルの閲覧でアク禁になるなんて聞いたことないが
ただの勘違いじゃないの?
ただの勘違いじゃないの?
2023/10/08(日) 11:55:37.48
画像が大量にあるページでそのほとんど取れてなかったりするとすぐ開けなくなる
2023/10/08(日) 13:14:20.29
>>109
> 画像が大量にあるページでそのほとんど取れてなかったり
その取れてない画像、全て/save/にリダイレクトされてるから
結果として大量にアーカイブ要求を発行することになるんだよね
んで、その時にアーカイブされるのは3つ程度であとは全て429エラー
運が悪いとそのままアク禁
> 画像が大量にあるページでそのほとんど取れてなかったり
その取れてない画像、全て/save/にリダイレクトされてるから
結果として大量にアーカイブ要求を発行することになるんだよね
んで、その時にアーカイブされるのは3つ程度であとは全て429エラー
運が悪いとそのままアク禁
2023/10/10(火) 14:58:47.09
>>99
過去ログについては一応、2chSCへも殆どがミラーされてるはずだけどな…。
過去ログについては一応、2chSCへも殆どがミラーされてるはずだけどな…。
2023/10/12(木) 23:37:32.61
油断は禁物
あとpink系は全部だめ
5ch新設板系も全部だめ
あとpink系は全部だめ
5ch新設板系も全部だめ
113名無しさん@お腹いっぱい。
2023/10/12(木) 23:58:45.47 scはクロールされてるなと思って後で確認すると途中でクロールが止まってそのままというのがかなりある
こういう状態になるとクロール再開しないケースが多く5ch側が飛んだ時に頭のほうしか控えが取れてなかったりする
こういう状態になるとクロール再開しないケースが多く5ch側が飛んだ時に頭のほうしか控えが取れてなかったりする
2023/10/16(月) 02:19:32.91
過去ログ、今年中は見れない可能性あるらしいな・・・
0119Ace ★
2023/10/13(金) 09:40:26.65ID:CAP_USER
過去ログについてですが、現状はアーカイブ圧縮状態で
展開再配置は相当に時間がかかる見込みです。
完了は年を越す可能性もあります。
https://agree.5ch.net/test/read.cgi/operate/1697113482/119
0119Ace ★
2023/10/13(金) 09:40:26.65ID:CAP_USER
過去ログについてですが、現状はアーカイブ圧縮状態で
展開再配置は相当に時間がかかる見込みです。
完了は年を越す可能性もあります。
https://agree.5ch.net/test/read.cgi/operate/1697113482/119
2023/10/18(水) 23:04:25.87
たまに総アーカイブ数が294 billionって表示されるの何なんだ?
2023/10/20(金) 22:59:55.77
>>112
一応なんG板とか、2014年春以降に新設された板でもSC側のbbsmenu一覧ページに追加されてないだけで、
[ http://tomcat.2ch.(えすしー)/livegalileo/ ]
…の鯖名から開けばアーカイブされてたりするけど、PINKともども最近の過去ログについては本鯖のモノが未だ活きてる。
一応なんG板とか、2014年春以降に新設された板でもSC側のbbsmenu一覧ページに追加されてないだけで、
[ http://tomcat.2ch.(えすしー)/livegalileo/ ]
…の鯖名から開けばアーカイブされてたりするけど、PINKともども最近の過去ログについては本鯖のモノが未だ活きてる。
117名無しさん@お腹いっぱい。
2023/10/23(月) 17:58:57.35 X保存できるようになってる
118名無しさん@お腹いっぱい。
2023/10/23(月) 17:58:58.33 X保存できるようになってる
119名無しさん@お腹いっぱい。
2023/10/23(月) 17:59:05.79 X保存できるようになってる
120名無しさん@お腹いっぱい。
2023/10/23(月) 18:00:35.82 連投すまん
ミスった
ミスった
2023/10/24(火) 14:07:36.28
2023/10/24(火) 14:07:46.22
2023/10/25(水) 20:59:15.52
video.twimgとれなくなった?
2023/10/27(金) 02:04:52.34
>>123
普通に取れるけど
普通に取れるけど
125名無しさん@お腹いっぱい。
2023/11/02(木) 00:20:55.25 こんなのがいつのまに
2022年11月18日 23時00分レビュー
無料&広告なしで個人サイトを作成できるGeocities風サービス「Neocities」を使ってみたよレビュー
https://gigazine.net/news/20221118-neocities-free-website/
2022年11月18日 23時00分レビュー
無料&広告なしで個人サイトを作成できるGeocities風サービス「Neocities」を使ってみたよレビュー
https://gigazine.net/news/20221118-neocities-free-website/
2023/11/05(日) 02:15:27.98
利用者の多いコンテンツの生殺与奪を特定小数人が握ってるのは危なっかしいよな
ttps://hayabusa9.5ch.net/test/read.cgi/mnewsplus/1698901347/
まあつべはバックアップを隠し持ってそうだけど こんな金になりそうなもん手放さねえだろうし 一般人が直に利用できないだけで
ttps://hayabusa9.5ch.net/test/read.cgi/mnewsplus/1698901347/
まあつべはバックアップを隠し持ってそうだけど こんな金になりそうなもん手放さねえだろうし 一般人が直に利用できないだけで
127名無しさん@お腹いっぱい。
2023/11/05(日) 17:54:34.46 日本の書籍が著作権ありのもたまにいいのがアップされてたのが、騒動以後いっこもアップされなくなったなあ
結構暇つぶしにいいのに
結構暇つぶしにいいのに
2023/11/08(水) 01:45:12.70
質問です
・今開いているサイトの魚拓をワンクリックで取る方法はありますか?
(いちいちInternet Archiveのサイトを開いてコピーしたURLをペーストして決定を押すのがちょっと面倒です
)
・サイト全体(orサイトの複数ページ)を自動で保存してくれる機能はありますか?
・今開いているサイトの魚拓をワンクリックで取る方法はありますか?
(いちいちInternet Archiveのサイトを開いてコピーしたURLをペーストして決定を押すのがちょっと面倒です
)
・サイト全体(orサイトの複数ページ)を自動で保存してくれる機能はありますか?
2023/11/08(水) 11:53:44.52
130名無しさん@お腹いっぱい。
2023/11/08(水) 12:48:50.052023/11/08(水) 13:50:28.69
アクティブチームw


132名無しさん@お腹いっぱい。
2023/11/09(木) 20:53:09.04 どうしてもすぐにアーカイブしたい動画があるならtubeupを使って自分でうpするか
Yt-dlpを使ってメタデータを含めてローカルに落とすのが理想や!
Yt-dlpを使ってメタデータを含めてローカルに落とすのが理想や!
133名無しさん@お腹いっぱい。
2023/11/10(金) 23:40:24.43 ArchiveTeamは特定の動画(削除の危機がある, ニュース, 政治etc)に限定して保存してるから、保存したい動画は手動保存する必要がある
リソースは有限だからね
↓詳細
https://wiki.archiveteam.org/index.php/YouTube#Scope
リソースは有限だからね
↓詳細
https://wiki.archiveteam.org/index.php/YouTube#Scope
134名無しさん@お腹いっぱい。
2023/11/11(土) 13:29:16.82 Wayback Machineに保存されてるそこそこ古めのページを表示すると、一部の画像が表示されない事ってよくあるよね。
あれって何でああなってるの?たとえば以下のページなど。
https://web.archive.org/web/20021017173116/http://www.namco.co.jp/home/cs/lineup/mrdriller/page01.html
このページは2002年保存だけど、比較的新しい2010年とかに保存されたページでも同現象になってたりする。
当時保存した人も、ちゃんと保存できてるか確認して、当時は問題なく表示されてたんだと思う。
今俺たちが保存してるサイトも、10年後には画像がところどころ抜け落ちて不完全な状態になるのかと不安。
あれって何でああなってるの?たとえば以下のページなど。
https://web.archive.org/web/20021017173116/http://www.namco.co.jp/home/cs/lineup/mrdriller/page01.html
このページは2002年保存だけど、比較的新しい2010年とかに保存されたページでも同現象になってたりする。
当時保存した人も、ちゃんと保存できてるか確認して、当時は問題なく表示されてたんだと思う。
今俺たちが保存してるサイトも、10年後には画像がところどころ抜け落ちて不完全な状態になるのかと不安。
2023/11/11(土) 13:32:47.70
確認されてないから画像が抜け落ちてる
2023/11/11(土) 15:59:18.06
>>134
そもそも Internet Archive でヘッドレスブラウザを実装したのがほんの数年前のことで、
それまでは指示された単一のファイルをアーカイブするだけだったから。
アーカイブされた HTML をクライアント側のブラウザで表示したときに
個々の画像等の保存リクエストが Internet Archive へ発行されるような実装が
なされたこともあったが、それ自体も 2010 年代中盤だったはず。
そもそも Internet Archive でヘッドレスブラウザを実装したのがほんの数年前のことで、
それまでは指示された単一のファイルをアーカイブするだけだったから。
アーカイブされた HTML をクライアント側のブラウザで表示したときに
個々の画像等の保存リクエストが Internet Archive へ発行されるような実装が
なされたこともあったが、それ自体も 2010 年代中盤だったはず。
137名無しさん@お腹いっぱい。
2023/11/11(土) 19:27:03.13 そうかなぁ?
俺はInternet Archive側にある画像ファイルが何らかの理由で勝手に消滅したと思ってる。
以下のサイトとかもそう。画像が1つも保存されてないのはおかしいだろ。
https://web.archive.org/web/20131007222449/http://www.spike-chunsoft.co.jp/fr/index.html
俺はInternet Archive側にある画像ファイルが何らかの理由で勝手に消滅したと思ってる。
以下のサイトとかもそう。画像が1つも保存されてないのはおかしいだろ。
https://web.archive.org/web/20131007222449/http://www.spike-chunsoft.co.jp/fr/index.html
2023/11/11(土) 19:39:27.54

2023/11/11(土) 20:41:42.88
>>137
https://ja.wikipedia.org/wiki/%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%8D%E3%83%83%E3%83%88%E3%82%A2%E3%83%BC%E3%82%AB%E3%82%A4%E3%83%96
IA自身がクローラーを回して収集活動を始めるまでの歴史について知っておくと良い。
https://ja.wikipedia.org/wiki/%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%8D%E3%83%83%E3%83%88%E3%82%A2%E3%83%BC%E3%82%AB%E3%82%A4%E3%83%96
IA自身がクローラーを回して収集活動を始めるまでの歴史について知っておくと良い。
2023/11/11(土) 21:56:56.93
昔のエッチサイトで自分が見たいところだけ抜け落ちてる悲しみ(´・ω・`)
2023/11/13(月) 01:18:15.56
IAのアーカイブって色んな団体のアーカイブがまとまったものだからな、SPNなんてごく一部だよ
画像も収集してる団体もあれば、HTMLだけを取得してる団体もあるのでアーカイブ次第
例えばウェイバックマシンを使ってるとよく目にするCommon Crawlはほぼ画像が取得されてない
画像も収集してる団体もあれば、HTMLだけを取得してる団体もあるのでアーカイブ次第
例えばウェイバックマシンを使ってるとよく目にするCommon Crawlはほぼ画像が取得されてない
142名無しさん@お腹いっぱい。
2023/11/13(月) 11:01:00.35 確実に保存したい時は
InternetArchiveとArchive.todayどっちもアーカイブしてるわ
それで大体残ると思うけどどうだろ
InternetArchiveとArchive.todayどっちもアーカイブしてるわ
それで大体残ると思うけどどうだろ
2023/11/13(月) 21:58:51.62
>>141
それで精度だったり保存量にばらつきがあるんすね
それで精度だったり保存量にばらつきがあるんすね
144名無しさん@お腹いっぱい。
2023/11/14(火) 22:23:03.18 ここ最近自動アーカイブがされてないようだけど一体どうしたんだ?
2023/11/15(水) 13:06:21.31
2023/11/15(水) 13:33:45.41
>>145
クッキー喰ったことにすればアーカイブはできるな。
使うのは API の capture_cookie パラメータ。
https://web.archive.org/web/20231115043115/sirius10.net/Games/hgames.php
クッキー喰ったことにすればアーカイブはできるな。
使うのは API の capture_cookie パラメータ。
https://web.archive.org/web/20231115043115/sirius10.net/Games/hgames.php
147名無しさん@お腹いっぱい。
2023/11/15(水) 16:29:16.84 えっ?年齢認証のページも保存できたの?初めて知った。
以前、以下のページを保存したかったけど諦めたんだ。
https://www.konami.com/games/pcemini/jp/ja/
もしこのページ保存できるなら、上部メニューの8ページほど保存しといてほしい。もしくはそのAPIの使い方を具体的に教えてほしい。
まだ誰も上手く保存できてないみたいだし。
以前、以下のページを保存したかったけど諦めたんだ。
https://www.konami.com/games/pcemini/jp/ja/
もしこのページ保存できるなら、上部メニューの8ページほど保存しといてほしい。もしくはそのAPIの使い方を具体的に教えてほしい。
まだ誰も上手く保存できてないみたいだし。
148名無しさん@お腹いっぱい。
2023/11/15(水) 16:34:01.70 保存してほしいのは以下の6個のURL。もし保存できるのであればだけど。
https://www.konami.com/games/pcemini/jp/ja/
https://www.konami.com/games/pcemini/topics/jp/ja/topics_9
https://www.konami.com/games/pcemini/feature/jp/ja/
https://www.konami.com/games/pcemini/faq/jp/ja/
https://www.konami.com/games/pcemini/inquiry/jp/ja/
https://www.konami.com/games/pcemini/product/jp/ja/
https://www.konami.com/games/pcemini/jp/ja/
https://www.konami.com/games/pcemini/topics/jp/ja/topics_9
https://www.konami.com/games/pcemini/feature/jp/ja/
https://www.konami.com/games/pcemini/faq/jp/ja/
https://www.konami.com/games/pcemini/inquiry/jp/ja/
https://www.konami.com/games/pcemini/product/jp/ja/
2023/11/15(水) 16:54:07.39
150名無しさん@お腹いっぱい。
2023/11/15(水) 17:04:47.722023/11/15(水) 23:20:06.19
>>146
すげえ、ありがとう
すげえ、ありがとう
2023/11/18(土) 14:45:36.85
If something goes wrong please click here to send us an error report.
ってやつ、下じゃなくて上に配置してくれないかな・・・
何回誤送信したか分からん
ってやつ、下じゃなくて上に配置してくれないかな・・・
何回誤送信したか分からん
153名無しさん@お腹いっぱい。
2023/11/18(土) 15:42:54.81 twitter保存できないことが最近増えてるみたいだけど、archivetodayでも保存できない場合は、cacheリンクをぶち込むと保存できるでー
154名無しさん@お腹いっぱい。
2023/11/19(日) 14:41:27.28 twitter以外の保存できないサイトも、
https://webcache.googleusercontent.com/search?q=cache:保存したいリンク
をWabackmachineに入れればキャッシュを保存できる。
https://webcache.googleusercontent.com/search?q=cache:保存したいリンク
をWabackmachineに入れればキャッシュを保存できる。
2023/11/19(日) 14:44:57.55
認証要る系は無理
2023/11/19(日) 19:17:19.50
twitterならnitterで良くね?
157名無しさん@お腹いっぱい。
2023/11/19(日) 19:21:06.50 リダイレクトページを保存して過去のアーカイブ上書きして使いづらくする問題
なんで放置されてんだよ!
なんで放置されてんだよ!
158名無しさん@お腹いっぱい。
2023/11/20(月) 04:47:38.50 俺も基本nitterキャプってるなTwitter取得する時は
2023/11/21(火) 01:55:39.65
"The requested video has been archived but is not currently available for playback."と"Attempts to archive this video failed."が出たときが一番ダルい
160名無しさん@お腹いっぱい。
2023/11/22(水) 20:57:37.32 イーロン・マスクのせいで、1tweetごとにarchiveしないといけなくなったけど、
より問題なのは、tweet群が本人の削除やアカウント停止などで消されてしまったら、
archiveがあってもtweet同士のつながりがわからなくなること。
以前はtweetを1カ所か何カ所かwayback machineで押さえれば、スレッド丸ごとarchiveできたのに。
より問題なのは、tweet群が本人の削除やアカウント停止などで消されてしまったら、
archiveがあってもtweet同士のつながりがわからなくなること。
以前はtweetを1カ所か何カ所かwayback machineで押さえれば、スレッド丸ごとarchiveできたのに。
2023/11/23(木) 07:29:06.67
何度保存しても「Hrm. The Wayback Machine has not archived that URL.」が出続ける。
162名無しさん@お腹いっぱい。
2023/11/23(木) 16:23:31.19163名無しさん@お腹いっぱい。
2023/11/25(土) 06:53:47.532023/11/25(土) 07:21:35.68
2023/11/25(土) 15:36:03.02
SPNって一日1000ページ保存が上限なのか。初めて引っかかった。outlink込みでやってたからか。
あと最近頻繁にログアウトしてしまうんだけどこれも不具合なのかな。
あと最近頻繁にログアウトしてしまうんだけどこれも不具合なのかな。
166名無しさん@お腹いっぱい。
2023/11/27(月) 21:08:31.71 >>162
戻る可能性もありそう。
ツイッターの閲覧制限 「経済的な理由という指摘もある」と辛坊治郎
https://news.1242.com/article/448206
Twitter閲覧制限 の理由:データスクレイピング の全てを わかりやすく 説明します
https://sotatek.jp/blogs/all-about-the-reason-behind-twitter-new-view-limit/
「情報はタダじゃない」訴える意図? Twitter閲覧制限 “スクレイピング”…サーバー負荷にマスク氏不満か
https://news.ntv.co.jp/category/society/9517009c0a124432a4ae38cecc2a2cf4
【解説】ツイッター“閲覧制限”なぜ? 考えられる2つの理由 マスク氏の狙いは
https://news.ntv.co.jp/category/society/78ed7d1aae84431889171d51800beb37
Twitterの閲覧制限が起きた理由|今後のビジネスへの影響は?
https://blog.formzu.com/twitter_limit
戻る可能性もありそう。
ツイッターの閲覧制限 「経済的な理由という指摘もある」と辛坊治郎
https://news.1242.com/article/448206
Twitter閲覧制限 の理由:データスクレイピング の全てを わかりやすく 説明します
https://sotatek.jp/blogs/all-about-the-reason-behind-twitter-new-view-limit/
「情報はタダじゃない」訴える意図? Twitter閲覧制限 “スクレイピング”…サーバー負荷にマスク氏不満か
https://news.ntv.co.jp/category/society/9517009c0a124432a4ae38cecc2a2cf4
【解説】ツイッター“閲覧制限”なぜ? 考えられる2つの理由 マスク氏の狙いは
https://news.ntv.co.jp/category/society/78ed7d1aae84431889171d51800beb37
Twitterの閲覧制限が起きた理由|今後のビジネスへの影響は?
https://blog.formzu.com/twitter_limit
2023/11/28(火) 12:24:55.48

168名無しさん@お腹いっぱい。
2023/11/28(火) 21:40:26.81 イーロンの野郎また何かやらかしたのか。
2023/11/29(水) 10:54:45.08
どっとうpろだ.orgサービス終了かよ
知らなかった
知らなかった
2023/11/30(木) 19:42:48.90
忘れた頃に消えてくれるからお世話になったなぁ・・・
長いことおつかれさんでした
長いことおつかれさんでした
2023/12/01(金) 16:35:49.47
saveできない状態
2023/12/01(金) 18:34:12.83
普段は「Not Found」が出ても何遍か更新すると正常に戻るが、今は何遍更新しても・・・
2023/12/01(金) 19:28:00.38
マジか。保存対象URL側に問題あるのかと諦めて魚拓で済ましたけどIA側の問題だったのか
2023/12/01(金) 20:03:23.58
URL側の場合は「Not Found」というか普段から「このURLは保存不可」的なのが出るが、
今はどのサイトを入力しても「Not Found」
今はどのサイトを入力しても「Not Found」
2023/12/01(金) 21:10:57.63
2023/12/01(金) 21:28:40.39
今日朝からnot foundだったから来てみたらおま環じゃなかったか
2023/12/01(金) 23:30:32.34
ようやくできるようになったが、4時間待ち(待ち時間は環境によるだろうが)
2023/12/01(金) 23:31:28.89
復活したけど、これじゃ今日のページ存できないな
The capture will start in ~7 hours, 39 minutes because our service is currently overloaded. You may close your browser window and the page will still be saved.
The capture will start in ~7 hours, 39 minutes because our service is currently overloaded. You may close your browser window and the page will still be saved.
2023/12/02(土) 15:23:15.03
待ち時間未明よりは減ってるが、まだ1時間待ち(環境によるだろうが)
ただし、PDF絡みの取得は問題なし
ただし、PDF絡みの取得は問題なし
180名無しさん@お腹いっぱい。
2023/12/02(土) 15:52:02.12 重い
2023/12/03(日) 02:47:23.34
14 hoursとか取得時間かかりすぎ
2023/12/03(日) 19:22:18.20
やっと直ったか
2023/12/03(日) 19:46:55.79
ページを保存しようとしたら
The capture will start in ~3 hours, 5 minutes because our service is currently overloaded. You may close your browser window and the page will still be saved.
と言われて、まだ終わらないけど、MP4動画単体を保存したら瞬時に保存された。
2023/12/03(日)19:39:14
URL: https://video.twimg.com/amplify_video/1727180400236417024/vid/avc1/1280x720/WJL1FSGpy8aLWnvc.mp4
Job: https://web.archive.org/save/status/spn2-a3a61ee7a77e38b016777f4e7c9b1139d337b0d8 [success][0.29s][初]
成功: https://web.archive.org/web/20231203103915/https://video.twimg.com/amplify_video/1727180400236417024/vid/avc1/1280x720/WJL1FSGpy8aLWnvc.mp4 - 2023/12/03(日)19:39:15
The capture will start in ~3 hours, 5 minutes because our service is currently overloaded. You may close your browser window and the page will still be saved.
と言われて、まだ終わらないけど、MP4動画単体を保存したら瞬時に保存された。
2023/12/03(日)19:39:14
URL: https://video.twimg.com/amplify_video/1727180400236417024/vid/avc1/1280x720/WJL1FSGpy8aLWnvc.mp4
Job: https://web.archive.org/save/status/spn2-a3a61ee7a77e38b016777f4e7c9b1139d337b0d8 [success][0.29s][初]
成功: https://web.archive.org/web/20231203103915/https://video.twimg.com/amplify_video/1727180400236417024/vid/avc1/1280x720/WJL1FSGpy8aLWnvc.mp4 - 2023/12/03(日)19:39:15
2023/12/04(月) 03:03:18.62
>>183
.jpg とか .png とか .zip とか、ヘッドレスブラウザでレンダせず
ファイル単体を保存するだけで済むものはそんな感じ。
.pdf も outlinks の走査はされるけど何故か速い。
.jpg とか .png とか .zip とか、ヘッドレスブラウザでレンダせず
ファイル単体を保存するだけで済むものはそんな感じ。
.pdf も outlinks の走査はされるけど何故か速い。
2023/12/05(火) 01:10:50.73
でた蔵の過去のテレビ番組のアーカイブ2022年12月以前の削除されちゃったんだな、最悪
gooといい価格コムといい削除するなら最初から公開しなきゃいいのに
NHKも一時期過去の番組表見れないようにしてたし何の目的なんだろうな
維持するのも金がかかるのかねえ
gooといい価格コムといい削除するなら最初から公開しなきゃいいのに
NHKも一時期過去の番組表見れないようにしてたし何の目的なんだろうな
維持するのも金がかかるのかねえ
186名無しさん@お腹いっぱい。
2023/12/05(火) 10:15:27.60 更新終了および閉鎖のお知らせ
2017年7月より更新を続けてきたウェブメディア「wezzy」ですが、2023年12月31日をもって更新を終了する運びとなりました。長年のご愛読ありがとうございました。
2024年3月31日にサイトの完全閉鎖を予定しております。
https://wezz-y.com/archives/95862
2017年7月より更新を続けてきたウェブメディア「wezzy」ですが、2023年12月31日をもって更新を終了する運びとなりました。長年のご愛読ありがとうございました。
2024年3月31日にサイトの完全閉鎖を予定しております。
https://wezz-y.com/archives/95862
187名無しさん@お腹いっぱい。
2023/12/05(火) 10:15:30.24 更新終了および閉鎖のお知らせ
2017年7月より更新を続けてきたウェブメディア「wezzy」ですが、2023年12月31日をもって更新を終了する運びとなりました。長年のご愛読ありがとうございました。
2024年3月31日にサイトの完全閉鎖を予定しております。
https://wezz-y.com/archives/95862
2017年7月より更新を続けてきたウェブメディア「wezzy」ですが、2023年12月31日をもって更新を終了する運びとなりました。長年のご愛読ありがとうございました。
2024年3月31日にサイトの完全閉鎖を予定しております。
https://wezz-y.com/archives/95862
188名無しさん@お腹いっぱい。
2023/12/05(火) 20:35:42.29 こんな糞重いクルクルクルクルしてるだけのゴミクズサイト
すでに2億円も寄付されてるの糞受けるな
裏金アベノイミン党みたいな連中だ
すでに2億円も寄付されてるの糞受けるな
裏金アベノイミン党みたいな連中だ
2023/12/06(水) 10:55:02.43
Not Found
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
saveできない
また逝ってるのかな
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
saveできない
また逝ってるのかな
2023/12/06(水) 12:06:41.28
またエラー吐いてる・・・
2023/12/06(水) 17:58:46.73
まーた404 NOT FOUNDだぞー
2023/12/06(水) 19:14:32.73
OH!! NO!!
2023/12/06(水) 20:29:25.03
やっと復旧した
┃ 午前9:18 ・ 2023年12月6日
┃ https://twitter.com/textfiles/status/1732192819098292677
┃ Jason Scott @textfiles
┃ Power has gone out at the @internetarchive primary datacenter; waiting for it to return.
┃ 午前10:04 ・ 2023年12月6日
┃ https://twitter.com/internetarchive/status/1732204429066289608
┃ Internet Archive @internetarchive
┃ Sorry, http://archive.org and http://openlibrary.org will be back in a few,
┃
┃ but a short term power outage was long enough to make recovery take a little while.
┃
┃ We apologize.
https://twitter.com/thejimwatkins
┃ 午前9:18 ・ 2023年12月6日
┃ https://twitter.com/textfiles/status/1732192819098292677
┃ Jason Scott @textfiles
┃ Power has gone out at the @internetarchive primary datacenter; waiting for it to return.
┃ 午前10:04 ・ 2023年12月6日
┃ https://twitter.com/internetarchive/status/1732204429066289608
┃ Internet Archive @internetarchive
┃ Sorry, http://archive.org and http://openlibrary.org will be back in a few,
┃
┃ but a short term power outage was long enough to make recovery take a little while.
┃
┃ We apologize.
https://twitter.com/thejimwatkins
2023/12/07(木) 15:12:31.98
停電多すぎね?アメリカってそんな停電するの?
2023/12/11(月) 10:14:59.64
あ゙あ゙あ゙あ゙あ゙ーーー

2023/12/11(月) 19:40:20.47
ここ何日か>>195のような表示がそのときそのときで出たり出なかったり
取得そのものができないよりは増しとはいえ・・・
取得そのものができないよりは増しとはいえ・・・
2023/12/11(月) 19:45:40.20
>>196
やっぱそうだよね、自分の環境のせいかと思ってたけど
やっぱそうだよね、自分の環境のせいかと思ってたけど
2023/12/11(月) 21:54:33.55
Donateしまくらなきゃな
199195
2023/12/11(月) 22:16:37.71 11 時間 42 分経過、結局アーカイブされてなかったからリクエスト発行し直した。
てゆーか 10 時間とか 20 時間とか言われても、数分後に同じ URL のアーカイブを
再リクエストしたらタイミングによってはすぐ保存してくれることもあるので
こういう時はやり直すのが正解だと理解することにした。
てゆーか 10 時間とか 20 時間とか言われても、数分後に同じ URL のアーカイブを
再リクエストしたらタイミングによってはすぐ保存してくれることもあるので
こういう時はやり直すのが正解だと理解することにした。
2023/12/12(火) 01:25:40.30
緑色の一日おき程度に取得した不完全なのを見かけるけどこういう事象の跡なのね
201名無しさん@お腹いっぱい。
2023/12/12(火) 19:24:45.55 Save outlinksで取得出来るページ数減らされてる…
202名無しさん@お腹いっぱい。
2023/12/12(火) 20:23:08.77 何個まで?
203名無しさん@お腹いっぱい。
2023/12/12(火) 20:25:41.13 まあここ最近、調子悪いからな。
しばらくすれば元に戻るかも。
しばらくすれば元に戻るかも。
2023/12/12(火) 20:51:11.11
近い内にサーバー飛んでサ終かもな
205名無しさん@お腹いっぱい。
2023/12/12(火) 21:35:01.32 Sorry
You cannot make more than 100 captures per day. Please email us at "info@archive.org" if you would like to discuss this more.
You cannot make more than 100 captures per day. Please email us at "info@archive.org" if you would like to discuss this more.
206名無しさん@お腹いっぱい。
2023/12/12(火) 22:59:52.35 なんかめちゃスムーズにspnリクエスト送れるようになってる
昨日ぐらいまでめっちゃ糞詰まり起こしてたのに
昨日ぐらいまでめっちゃ糞詰まり起こしてたのに
2023/12/12(火) 23:51:14.97

2023/12/12(火) 23:55:59.07
Sorry
Job failed
ってIAの画面がアーカイブされてる?ときって失敗ってことなんかな
Job failed
ってIAの画面がアーカイブされてる?ときって失敗ってことなんかな
2023/12/13(水) 00:05:36.88
2023/12/13(水) 00:13:02.17
せっかく>>206と思ったら今度は・・・
今までの1割とは落差がでかい
今までの1割とは落差がでかい
2023/12/13(水) 03:24:05.46
何回やってもどのサイトでもsorryになって保存できない
2023/12/13(水) 04:01:02.50
ろくに英語も読めないのにここでアーカイブ取ろうとしてるからだよ
2023/12/13(水) 08:31:24.05
?
日本語のサイトしか保存した事ないけど…
つか1日100件なんて保存してないのに⇓が出る
前にキャッシュcookie消去したらarchiveでの履歴も消えちゃったから消すの嫌なんだけどなあ
Sorry
You cannot make more than 100 captures per day. Please email us at "info@archive.org" if you would like to discuss this more
日本語のサイトしか保存した事ないけど…
つか1日100件なんて保存してないのに⇓が出る
前にキャッシュcookie消去したらarchiveでの履歴も消えちゃったから消すの嫌なんだけどなあ
Sorry
You cannot make more than 100 captures per day. Please email us at "info@archive.org" if you would like to discuss this more
2023/12/13(水) 08:59:55.49
100件も取得してなくても出るとか・・・ますます謎
2023/12/13(水) 11:42:51.22
2023/12/13(水) 17:44:14.23
画像とか含めてじゃないの
2023/12/13(水) 18:18:11.85
2023/12/13(水) 19:04:25.63
>>207
同時実行可能なセッション数も微妙に調整してますね
2023/02/18(土) {"available":6,"daily_captures":0,"daily_captures_limit":100000,"processing":0}
2023/08/21(月) {"available":6,"daily_captures":0,"daily_captures_limit":80000,"processing":0}
2023/09/06(水) {"available":6,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/09/29(金) {"available":8,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/11/23(木) {"available":8,"daily_captures":0,"daily_captures_limit":50000,"processing":0}
2023/12/12(火) {"available":7,"daily_captures":0,"daily_captures_limit":30000,"processing":0}
同時実行可能なセッション数も微妙に調整してますね
2023/02/18(土) {"available":6,"daily_captures":0,"daily_captures_limit":100000,"processing":0}
2023/08/21(月) {"available":6,"daily_captures":0,"daily_captures_limit":80000,"processing":0}
2023/09/06(水) {"available":6,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/09/29(金) {"available":8,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/11/23(木) {"available":8,"daily_captures":0,"daily_captures_limit":50000,"processing":0}
2023/12/12(火) {"available":7,"daily_captures":0,"daily_captures_limit":30000,"processing":0}
2023/12/13(水) 22:13:35.46
一方、アカウントなしの場合は>>4にあるとおり1分あたり3件
昨年の途中まで4件、今年でもわずかに4件だったことも
https://mevius.5ch.net/test/read.cgi/esite/1628793497/453
https://mevius.5ch.net/test/read.cgi/esite/1628793497/637
https://mevius.5ch.net/test/read.cgi/esite/1628793497/729
昨年の途中まで4件、今年でもわずかに4件だったことも
https://mevius.5ch.net/test/read.cgi/esite/1628793497/453
https://mevius.5ch.net/test/read.cgi/esite/1628793497/637
https://mevius.5ch.net/test/read.cgi/esite/1628793497/729
2023/12/14(木) 09:04:07.36
「日付」が切り替わってカウント数が0に戻るのは日本時間朝9時です
2023/12/15(金) 17:24:20.13
SPN2APIでリファラーって送る方法ある?
2023/12/15(金) 22:35:38.95
無いね
ページ内で使われてる画像なんかには送られてるみたいだけど
ページ内で使われてる画像なんかには送られてるみたいだけど
2023/12/15(金) 22:44:59.91
>>222
無いか〜・・・、サンクス
無いか〜・・・、サンクス
224名無しさん@お腹いっぱい。
2023/12/16(土) 01:38:13.04 nitter.net保存できなくなってる。
nitter.czならtodayの方で保存できるが
nitter.czならtodayの方で保存できるが
225名無しさん@お腹いっぱい。
2023/12/17(日) 20:30:36.67 Twitterはもう保存できなくなったのか?
保存した後、だいぶ経ってから保存されているはずの日付を見に行ったら中身が何もない。
そういうのばかり。
保存した後、だいぶ経ってから保存されているはずの日付を見に行ったら中身が何もない。
そういうのばかり。
2023/12/18(月) 15:22:07.99
Twitter側の仕様変更のせいで見た目はアーカイブできなくなった
ソースを見るとツイート内容はアーカイブされてるっぽい
ソースを見るとツイート内容はアーカイブされてるっぽい
227名無しさん@お腹いっぱい。
2023/12/18(月) 15:57:48.09 本家のtwitter.comも、nitter.netもウェイバックマシンでは保存できなくなってる。
今は、nitter.czをarchive.todayの方にぶち込むしか方法がない。
今は、nitter.czをarchive.todayの方にぶち込むしか方法がない。
2023/12/18(月) 16:54:37.67
今でも更新続ければ保存はできるけど、数日待たないとできなかったりで安定はしない
229名無しさん@お腹いっぱい。
2023/12/21(木) 04:31:49.98 登録しても制限をかけるなら、有料プランを導入してくれ
2023/12/21(木) 09:52:22.88
最近すこし保存しようとして更新するとすぐアク禁されて駄目だわ
231名無しさん@お腹いっぱい。
2023/12/22(金) 15:05:19.09 アク禁ってされたことないんだけど、どんな表示でるんだ
232名無しさん@お腹いっぱい。
2023/12/22(金) 15:05:21.69 アク禁ってされたことないんだけど、どんな表示でるんだ
233名無しさん@お腹いっぱい。
2023/12/22(金) 15:06:53.26 すまん連投になってもた
2023/12/22(金) 15:15:17.32
2023/12/23(土) 17:21:40.52
2〜3秒に1回位のアクセスに抑えておけばまずアク禁はされないと思うが
236名無しさん@お腹いっぱい。
2023/12/24(日) 20:12:20.28 アーカイブチームの皆さんは自分の事しか考えてないの?
あれだけ顧客第一つったろ!
あれだけ顧客第一つったろ!
2023/12/25(月) 14:38:28.21
次はアーカイブチームとインターネットアーカイブは無関係って事を覚えような
239名無しさん@お腹いっぱい。
2023/12/26(火) 07:40:40.52 自動保存できなくなったの?
2023/12/28(木) 19:50:12.24
https://archive.is/rt7gI
Archive.org is DOWN for everyone.
Archive.org is DOWN for everyone.
2023/12/29(金) 15:27:27.42
SPNとSPN-outlinksで結果が変わるの謎過ぎるな
SPNだと取れるのにoutlinksの方はエラーが出るサイトがたまにある
わざわざ別の環境使ってるのか?
SPNだと取れるのにoutlinksの方はエラーが出るサイトがたまにある
わざわざ別の環境使ってるのか?
2023/12/29(金) 16:01:08.08
と書いておいて何のエラーか一切説明しない低能
243名無しさん@お腹いっぱい。
2024/01/03(水) 15:31:04.592024/01/05(金) 00:43:45.29
archive.todayのほう死んでます?
2024/01/05(金) 02:20:34.95
一時間くらい前、ぐるぐるアイコンを表示したままリロードを繰り返す状態だったな。
2024/01/05(金) 21:00:47.72
アーカイブ開こうとすると実アドレスの方に飛ばされる症状が出てる
アーカイブに保存された形跡はある ただこれも保存済みアドレスが検索で出たりでなかったりがある
アーカイブに保存された形跡はある ただこれも保存済みアドレスが検索で出たりでなかったりがある
2024/01/07(日) 08:45:36.21
相変わらずこの時間帯の Tor 経由でのアーカイブは厳しいw
あと 15 分待つか

あと 15 分待つか

2024/01/08(月) 16:23:46.89
既出だったらスマン
アーカイブされたページ自体をユーザ側のアクションで検索エンジンのインデックスに登録することって可能なんかな
検索してみるといくつかの日本のサイトのアーカイブがGoogleにインデックス登録されてるんだよな
でもWaybackが自分でクロール申請したはずはないから何か方法があるんじゃないかと思ってる
例えば自分で立てたサイトにアーカイブへの直リンクを貼っておいて、自分のサイトをインデックス登録してリンク先をクロールさせるとか
アーカイブされたページ自体をユーザ側のアクションで検索エンジンのインデックスに登録することって可能なんかな
検索してみるといくつかの日本のサイトのアーカイブがGoogleにインデックス登録されてるんだよな
でもWaybackが自分でクロール申請したはずはないから何か方法があるんじゃないかと思ってる
例えば自分で立てたサイトにアーカイブへの直リンクを貼っておいて、自分のサイトをインデックス登録してリンク先をクロールさせるとか
2024/01/09(火) 05:18:09.59
うまいことpixivのアーカイブ取る方法はないものか
250名無しさん@お腹いっぱい。
2024/01/09(火) 19:55:25.902024/01/10(水) 07:22:01.53
うーむ
特定のホストにて、各 URL につき「一時間以上空けろ」ではなく
「一日一回のみアーカイブ可」ということか。
ちなみにホスト名は www.sqlite.org。
特定のホストにて、各 URL につき「一時間以上空けろ」ではなく
「一日一回のみアーカイブ可」ということか。
ちなみにホスト名は www.sqlite.org。

2024/01/10(水) 11:46:54.75
そんなにSPNの条件厳しくなったのか
2024/01/10(水) 15:40:19.81
昔このスレに居たスポーツ新聞野郎なら発狂してる事案w
2024/01/10(水) 16:08:44.56
2024/01/11(木) 00:50:47.06
ログインしても数個取るとすぐログアウトさせられるのはおま環?
2024/01/11(木) 02:24:05.23
クッキーを消した、有効期限切れ (一年間)、それ以外の原因でのログアウトは無いな。
2024/01/11(木) 16:04:39.91
2024/01/12(金) 18:40:22.52
Save Page Now browser crashed on http://naenara.com.kp/main/index/ja/first.
2024/01/14(日) 05:07:51.98
初めて目にしたかも


2024/01/15(月) 00:29:16.40
IAで、ディレクトリ内のファイル名に対して検索をする方法ってある?
2024/01/15(月) 00:29:45.25
IAで、ディレクトリ内のファイル名に対して検索をする方法ってある?
2024/01/15(月) 00:30:15.98
ごめんダブった
2024/01/15(月) 00:59:42.60
>>260-261
タイムスタンプ部分とディレクトリ名末尾に "*" とか
https://web.archive.org/web/*/www.sqlite.org/2023/*
検索対象の母数が一万件を超える場合は CDX Server API でリストを出してから
ローカルで抽出とか
https://mevius.5ch.net/test/read.cgi/esite/1628793497/332-333
タイムスタンプ部分とディレクトリ名末尾に "*" とか
https://web.archive.org/web/*/www.sqlite.org/2023/*
検索対象の母数が一万件を超える場合は CDX Server API でリストを出してから
ローカルで抽出とか
https://mevius.5ch.net/test/read.cgi/esite/1628793497/332-333
2024/01/15(月) 02:24:29.46
>>263
リプありがとうございます。
せっかく教えてくださったのに、自分の説明が足らなくて分からなかったのですが、やりたいことはこんな感じです
たとえば、↓のshow allを開くとディレクトリ内のコンテンツが表示されますが
その中のG71-VNW1013.isoを検索して見つける事はできますか?
ttps://archive.org/details/msi-afterburner-driver-and-utility
ttps://archive.org/search
に入力して検索をした場合、タイトルや説明欄しか拾わないので
どうしたものかと思っていました
リプありがとうございます。
せっかく教えてくださったのに、自分の説明が足らなくて分からなかったのですが、やりたいことはこんな感じです
たとえば、↓のshow allを開くとディレクトリ内のコンテンツが表示されますが
その中のG71-VNW1013.isoを検索して見つける事はできますか?
ttps://archive.org/details/msi-afterburner-driver-and-utility
ttps://archive.org/search
に入力して検索をした場合、タイトルや説明欄しか拾わないので
どうしたものかと思っていました
2024/01/15(月) 03:12:52.31
ファイル名での検索が可能なら、例えばこんなアップロードは
もっと閲覧数が増えているのではないかと思います。
https://archive.org/details/vps0000000000020160306
もっと閲覧数が増えているのではないかと思います。
https://archive.org/details/vps0000000000020160306
2024/01/15(月) 11:04:23.01
>>265
そっか…ありがとうございましたm(_ _)m
そっか…ありがとうございましたm(_ _)m
2024/01/15(月) 14:20:12.75
検索システムはもっと強化してほしいよなぁ
一度も閲覧されてない化石と化したアーカイブとか大量にありそう
まぁあまり強化するとDMCA案件が増えそうなので悩ましいけど
一度も閲覧されてない化石と化したアーカイブとか大量にありそう
まぁあまり強化するとDMCA案件が増えそうなので悩ましいけど
268名無しさん@お腹いっぱい。
2024/01/17(水) 09:51:54.39 ログインしても同時保存制限厳しい…(4つまで)
あと、一気にまとめて取得する方法ってないの?一個一個やってると面倒臭い
あと、一気にまとめて取得する方法ってないの?一個一個やってると面倒臭い
2024/01/17(水) 18:53:45.11

2024/01/17(水) 19:26:47.07
>>268
savepagenow@archive.org に電子メールを送信/転送するとメール中のURIをアーカイブした結果のメールが数~数十分後に返信されてくる
savepagenow@archive.org に電子メールを送信/転送するとメール中のURIをアーカイブした結果のメールが数~数十分後に返信されてくる
271名無しさん@お腹いっぱい。
2024/01/18(木) 00:05:13.23 「ウェブ魚拓」や「archive.today」では保存できるのに「wayback machine」ではできないということは、
Xは「wayback machine」を嫌がっているということか?
ウェブ魚拓
https://megalodon.jp/
archive.today
https://archive.md/
Xは「wayback machine」を嫌がっているということか?
ウェブ魚拓
https://megalodon.jp/
archive.today
https://archive.md/
2024/01/18(木) 00:12:17.43
別に今でもX保存できるけど
273名無しさん@お腹いっぱい。
2024/01/18(木) 00:59:42.30 >>272
保存した日付のところを見に行った?
たとえばこれ。
Saved 1 time January 13, 2024.
https://web.archive.org/web/20240000000000*/https://twitter.com/BasedMikeLee/status/1745945126793626064
https://megalodon.jp/2024-0117-2350-04/https://twitter.com:443/BasedMikeLee/status/1745945126793626064
https://archive.md/clxnV
https://twitter.com/thejimwatkins
保存した日付のところを見に行った?
たとえばこれ。
Saved 1 time January 13, 2024.
https://web.archive.org/web/20240000000000*/https://twitter.com/BasedMikeLee/status/1745945126793626064
https://megalodon.jp/2024-0117-2350-04/https://twitter.com:443/BasedMikeLee/status/1745945126793626064
https://archive.md/clxnV
https://twitter.com/thejimwatkins
2024/01/18(木) 02:24:21.59
「保存」は出来てるよ、表示が崩れてるだけ
CTRL+Uでソースを見ればツイート内容は保存されてるのが分かる
CTRL+Uでソースを見ればツイート内容は保存されてるのが分かる
2024/01/18(木) 02:40:16.78
https://web.archive.org/web/20240117173332/https://twitter.com/googlejapan/status/1747091305128477149
これなんかは動画まで含めてちゃんと取れたことを確認した
https://twitter.com/thejimwatkins
これなんかは動画まで含めてちゃんと取れたことを確認した
https://twitter.com/thejimwatkins
2024/01/18(木) 02:49:37.22
>>274
見られないなら保存した意味がない。
見られないなら保存した意味がない。
2024/01/19(金) 21:26:20.93
インターネットアーカイブのブログ、ずっと同じ糖質に粘着されてるの笑う
それでも削除しないのは流石だがw
それでも削除しないのは流石だがw
2024/01/28(日) 01:57:58.03
スラドのアーカイブを取ろうと思ったら、このサイト記事一覧ページって無いのか?
ajaxでmore moreで辿るしか無いんだろうか・・・
もう終わりだよ
ajaxでmore moreで辿るしか無いんだろうか・・・
もう終わりだよ
2024/01/28(日) 02:34:53.07
>>278
日付別の一覧、例えば昨日 (2024-01-26) のストーリー一覧なら
https://srad.jp/story/24/01/26/
から
https://mobile.srad.jp/story/24/01/24/2339228/
https://mobile.srad.jp/story/24/01/24/2346248/
https://it.srad.jp/story/24/01/24/2351254/
https://srad.jp/story/24/01/25/1337233/
https://it.srad.jp/story/24/01/25/1340217/
・・・
と記事番号とカテゴリ名を含む URL は得られるかと思います。
日付別の一覧、例えば昨日 (2024-01-26) のストーリー一覧なら
https://srad.jp/story/24/01/26/
から
https://mobile.srad.jp/story/24/01/24/2339228/
https://mobile.srad.jp/story/24/01/24/2346248/
https://it.srad.jp/story/24/01/24/2351254/
https://srad.jp/story/24/01/25/1337233/
https://it.srad.jp/story/24/01/25/1340217/
・・・
と記事番号とカテゴリ名を含む URL は得られるかと思います。
280279
2024/01/28(日) 02:39:44.69 おっとそれは一昨日だったw
PC を UTC タイムゾーンで動かしているのでうっかり・・・
PC を UTC タイムゾーンで動かしているのでうっかり・・・

281名無しさん@お腹いっぱい。
2024/01/28(日) 09:17:36.54 >>273
https://web.archive.org/web/20240126113327/https://twitter.com/s96shiho/status/1723541214925029490
これもそうだけど、スマホでなら見られるのにPCだと見られないのはなぜだろうか?
>>275
それはPCでも見られた。
https://twitter.com/thejimwatkins
https://web.archive.org/web/20240126113327/https://twitter.com/s96shiho/status/1723541214925029490
これもそうだけど、スマホでなら見られるのにPCだと見られないのはなぜだろうか?
>>275
それはPCでも見られた。
https://twitter.com/thejimwatkins
2024/01/28(日) 13:04:59.85
2024/01/28(日) 15:30:54.71
あと3日半だから絶望的じゃん
2024/01/28(日) 15:51:21.68
月曜日に発表があって週末が1回しかないって急すぎるよ。
しかもスラドってコメント欄がperlのajaxで読み込んでるからアーカイブだとまともに表示できないだろうし
しかもスラドってコメント欄がperlのajaxで読み込んでるからアーカイブだとまともに表示できないだろうし
285名無しさん@お腹いっぱい。
2024/01/29(月) 09:18:53.73 savepagenow@archive.org に取得したいページのURL送ったんだけど、ほとんどError! Capture timed outになる・・・
これってサーバー重くて失敗したのかな?
これってサーバー重くて失敗したのかな?
2024/01/31(水) 16:01:30.81
Save Page Now browser crashed
なんかエラー吐いて来るね・・・
取れてる奴もあるけど違いがわからん
なんかエラー吐いて来るね・・・
取れてる奴もあるけど違いがわからん
2024/01/31(水) 16:14:30.83
それ Linux バイナリをアーカイブさせると良く出くわすな。
force_get=on を指定すると問題無く行けてるから、おそらく
コンテンツをヘッドレスブラウザでレンダしようとして失敗してるんだと思う。
force_get=on を指定すると問題無く行けてるから、おそらく
コンテンツをヘッドレスブラウザでレンダしようとして失敗してるんだと思う。
288名無しさん@お腹いっぱい。
2024/02/01(木) 05:22:38.32 Srad はアーカイブチームが動いてるって見たけど
個人でバックアップしている人もおるんか
個人でバックアップしている人もおるんか
2024/02/01(木) 14:17:08.29
スラド閉鎖撤回したな
まぁ不安定な状況である事には変わらないからアーカイブはした方が良い
まぁ不安定な状況である事には変わらないからアーカイブはした方が良い
2024/02/02(金) 15:14:07.28
The capture will start in ~1 hour, 1 minute because our service is currently overloaded.
また1時間後とか言われるようになっちゃった・・・
また1時間後とか言われるようになっちゃった・・・
2024/02/02(金) 18:58:54.38
個人的に巡回ソフトでアーカイブ出来てたシンプル極まりない頃が懐かしい
292名無しさん@お腹いっぱい。
2024/02/04(日) 09:19:08.45 Save Page Now browser crashed
ヤフオクのページを取得しようとすると出る
ヤフオクのページを取得しようとすると出る
2024/02/04(日) 12:09:51.36
アーカイブしても画像が保存されないのキツイな
昔から収集方法変えてないみたいだけど
運営陣は変えるつもりないんだろうか
色々相性問題とかあって変えられないのかな?
昔から収集方法変えてないみたいだけど
運営陣は変えるつもりないんだろうか
色々相性問題とかあって変えられないのかな?
294名無しさん@お腹いっぱい。
2024/02/04(日) 12:32:11.99 >>293
大ぼら乙
大ぼら乙
295名無しさん@お腹いっぱい。
2024/02/04(日) 13:30:12.10 サイトによるのでは
2024/02/04(日) 16:23:38.85
今でも画像はアーカイブ開いて取得しないといけない
2024/02/04(日) 16:36:51.96
【2020 年頃まで】
画像の保存は完全にユーザ任せ
(クローラを使っていたり、或いは
普通のブラウザでも保存開始後にすぐ閉じたりすると保存されない)
【それ以降】
ヘッドレスブラウザを実装、ある程度の画像は同時にアーカイブできるようになった
>>293 の言う昔って、いつの話よ?
画像の保存は完全にユーザ任せ
(クローラを使っていたり、或いは
普通のブラウザでも保存開始後にすぐ閉じたりすると保存されない)
【それ以降】
ヘッドレスブラウザを実装、ある程度の画像は同時にアーカイブできるようになった
>>293 の言う昔って、いつの話よ?
2024/02/05(月) 21:56:56.61
動的サイトを取ろうとして取れないと勘違いしてるパターンじゃない?
画像は4年前から取れてるし、最近だと自動でアウトリンクまで辿ってくれるようになってるが
画像は4年前から取れてるし、最近だと自動でアウトリンクまで辿ってくれるようになってるが
2024/02/06(火) 10:29:25.54
Tor を使っていると、本当にいろんな体験ができるw
この時の出口ノードは 🇳🇴 185.243.218.61。
この時の出口ノードは 🇳🇴 185.243.218.61。

2024/02/07(水) 01:46:05.35
Google検索のキャッシュリンクが廃止で過去のページが閲覧不可に
https://pc.watch.impress.co.jp/docs/news/1566730.html
>Googleは、検索結果ページで利用できたWebページのキャッシュへのリンクを削除した。
これまで検索結果の各Webページのキャッシュにアクセスできるリンクが用意されており、Webページの過去の状態や削除される前の状態などが確認できたが、このリンクが削除されたかたち。検索演算子「cache:」を使ったアクセスはまだ行なえるが、将来的にはこちらも利用できなくなる予定だという。
これにともないGoogleでは、キャッシュへのリンクに代わって、Internet Archiveへのリンクを追加したいとも考えているという。
https://pc.watch.impress.co.jp/docs/news/1566730.html
>Googleは、検索結果ページで利用できたWebページのキャッシュへのリンクを削除した。
これまで検索結果の各Webページのキャッシュにアクセスできるリンクが用意されており、Webページの過去の状態や削除される前の状態などが確認できたが、このリンクが削除されたかたち。検索演算子「cache:」を使ったアクセスはまだ行なえるが、将来的にはこちらも利用できなくなる予定だという。
これにともないGoogleでは、キャッシュへのリンクに代わって、Internet Archiveへのリンクを追加したいとも考えているという。
301名無しさん@お腹いっぱい。
2024/02/08(木) 07:44:47.71 オープンになったことで話題のBlueskyはarchive.todayで昔のTwitterみたいにスレッド丸ごとアーカイブできるようだ。
ところがWayback Machineでは保存できないみたい。
ところがWayback Machineでは保存できないみたい。
302名無しさん@お腹いっぱい。
2024/02/08(木) 10:56:12.30 >>300
IAにリンク貼るならGoogleから多額の寄付金もらえそう
IAにリンク貼るならGoogleから多額の寄付金もらえそう
303名無しさん@お腹いっぱい。
2024/02/08(木) 11:50:26.632024/02/08(木) 12:15:36.70
流れをぶった切って済まんが
https://download.sysinternals.com/ 配下の URL にて >>251 に遭遇。
ソフトウェア配布サイトをターゲットにした措置だとは思うが
Sysinternals のようにファイル名にリビジョン番号を記載せず
同じ URL のまま中身を差し替えていくサイトでは、
短期間で更新が繰り返されると保存されないリビジョンが出てくる。
https://download.sysinternals.com/ 配下の URL にて >>251 に遭遇。
ソフトウェア配布サイトをターゲットにした措置だとは思うが
Sysinternals のようにファイル名にリビジョン番号を記載せず
同じ URL のまま中身を差し替えていくサイトでは、
短期間で更新が繰り返されると保存されないリビジョンが出てくる。
2024/02/10(土) 16:54:28.54
This URL has been already captured 6 times today, which is a daily limit we have set for that host. Please try again tomorrow.
10回制限からなんか減った?
10回制限からなんか減った?
2024/02/10(土) 17:13:12.85
2024/02/10(土) 21:36:47.45
>>306
いや以前は10回制限だったのに6回になったなってだけ
いや以前は10回制限だったのに6回になったなってだけ
2024/02/10(土) 22:21:20.99
309名無しさん@お腹いっぱい。
2024/02/12(月) 13:36:03.14 Wayback Machineってdoc形式のファイルやdocx形式のファイルも保存できるんだね
ホント便利だな
ホント便利だな
2024/02/12(月) 16:04:03.39
一日一回のみとか10回のみのエラーってAPIドキュメントには無いよね?
特別に指定されてるんだろうか
特別に指定されてるんだろうか
311名無しさん@お腹いっぱい。
2024/02/14(水) 16:25:56.42 X(twitter)はnitter.czにリンクを変えて、archive.todayにぶち込んで保存してる。
他にも方法あるかもしれんけど
他にも方法あるかもしれんけど
312名無しさん@お腹いっぱい。
2024/02/15(木) 18:30:11.00 そういやnitterの開発終了したんだってな
今のところ動いてるインスタンスはあるけど、これからどうなんだろ
今のところ動いてるインスタンスはあるけど、これからどうなんだろ
313名無しさん@お腹いっぱい。
2024/02/15(木) 23:04:23.48 これからどうやってtwitter保存すればいいんだろう
2024/02/17(土) 01:09:16.83
youtubeの動画保存って無くなったのか?
youtubecrawlのコレクションは増え続けてるから動いてるはずなんだが、未だに保存されん・・・
国内メディアのニュース動画だからブロックされてる訳でも無いと思うんだがなぁ
youtubecrawlのコレクションは増え続けてるから動いてるはずなんだが、未だに保存されん・・・
国内メディアのニュース動画だからブロックされてる訳でも無いと思うんだがなぁ
315名無しさん@お腹いっぱい。
2024/02/17(土) 09:06:16.83 >>313
Twitter保存できるようになってましたよ
https://web.archive.org/web/20240216073841/https://twitter.com/elonmusk/status/1757474164850798632
https://web.archive.org/web/20240216154723/https://twitter.com/elonmusk/status/1757840768923021363
https://web.archive.org/web/20240217000150/https://twitter.com/elonmusk/status/1757924482885583112
https://twitter.com/thejimwatkins
Twitter保存できるようになってましたよ
https://web.archive.org/web/20240216073841/https://twitter.com/elonmusk/status/1757474164850798632
https://web.archive.org/web/20240216154723/https://twitter.com/elonmusk/status/1757840768923021363
https://web.archive.org/web/20240217000150/https://twitter.com/elonmusk/status/1757924482885583112
https://twitter.com/thejimwatkins
316名無しさん@お腹いっぱい。
2024/02/17(土) 18:37:04.84 >>315
ホンマや
ホンマや
2024/02/21(水) 03:43:18.85
>>281 が PC でも見られる、ってことは保存し直しの必要は無しか。
しかしアーカイブの表示内容が変化するってのは、別の意味で気持ち悪い。
しかしアーカイブの表示内容が変化するってのは、別の意味で気持ち悪い。
318名無しさん@お腹いっぱい。
2024/02/21(水) 16:29:14.97 ページ数、なかなか9000億超えないな
2024/02/21(水) 17:19:47.55
今もだけど、たまにアーカイブ数が減るのは何なんだろうか
しばらくすると元に戻るけど
しばらくすると元に戻るけど
2024/02/21(水) 21:40:13.97
取得時間がまた2時間とか伸びて面倒
321名無しさん@お腹いっぱい。
2024/02/24(土) 02:00:32.15 ヘッダー部分の下からが表示されないんだねど自分だけかな。キャッシュ消したり再起動しても直らん
2024/02/26(月) 16:37:22.05
323名無しさん@お腹いっぱい。
2024/03/03(日) 13:23:54.98 ブルースカイは、アカウントの設定(ログアウトしたユーザーからの可視性)よっては取得できないから注意
2024/03/03(日) 16:09:52.87
セッションハイジャック耐性の無いサイトなら
capture_cookie パラメータ辺り使えば行けるんだけどなぁ
capture_cookie パラメータ辺り使えば行けるんだけどなぁ
2024/03/03(日) 23:23:39.94
数日前からtodayの調子が悪くて調べたらcloudflareDNSと相性悪いのか
2024/03/04(月) 06:55:51.29
ページを保存させて完了画面も確認したのに、そのページが表示されないな
カレンダー形式の一覧に反映されるまでにはこれまでも時間がかかっていたけど
保存ページ自体が数十分待っても出てこないのは初めて
カレンダー形式の一覧に反映されるまでにはこれまでも時間がかかっていたけど
保存ページ自体が数十分待っても出てこないのは初めて
2024/03/04(月) 07:06:56.05
今もう一度見てみたら、既にカレンダー形式の日付には青丸が付いているのに
さっき保存した保存時刻(UTC)をクリックしてもその内容が表示されないという現象が起きてる
さっき保存した保存時刻(UTC)をクリックしてもその内容が表示されないという現象が起きてる
2024/03/04(月) 14:03:06.47
最近はよくある
半日くらい待つと出てくる
半日くらい待つと出てくる
329名無しさん@お腹いっぱい。
2024/03/05(火) 17:33:40.00 i.imgur.comのページは一瞬で保存できるのなんでなんだろ
2024/03/05(火) 19:50:05.76
331名無しさん@お腹いっぱい。
2024/03/06(水) 01:49:37.87 ニコニコ動画のフォロワー欄が途中までしか保存されない問題ってどうすれば解決できますか?
www.nicovideo.jp/user/23396749/follow/follower
https://archive.is/4Efzj
上記のユーザーならフォロワーは僅か40なので情報量が大きすぎるという訳でもないはずなのですが
www.nicovideo.jp/user/23396749/follow/follower
https://archive.is/4Efzj
上記のユーザーならフォロワーは僅か40なので情報量が大きすぎるという訳でもないはずなのですが
2024/03/10(日) 15:14:50.96
5chのnovaサーバーだけ取れなくなってる?
333名無しさん@お腹いっぱい。
2024/03/10(日) 15:18:40.98 今日調子悪い?
334名無しさん@お腹いっぱい。
2024/03/10(日) 15:18:44.98 今日調子悪い?
2024/03/10(日) 15:35:56.28
2024/03/10(日) 19:42:19.84
https://nova.5ch.net/livegalileo/
https://nova.5ch.net/novatr/
各板のトップは国外から見られるが、個別スレを開こうとすると 520 エラーが返る。
Internet Archive のサーバは米国にあるから当然エラーとなる。
https://nova.5ch.net/novatr/
各板のトップは国外から見られるが、個別スレを開こうとすると 520 エラーが返る。
Internet Archive のサーバは米国にあるから当然エラーとなる。

2024/03/11(月) 01:13:22.82
今日は一日繋がらなかったな
2024/03/11(月) 21:15:52.76
>>331
じゅんじゅ@\( ・ω・)/ www.nicovideo.jp/user/41124243
元グリーンベレー user/13675361 ・ lalala user/2765923
蘭‐Ran‐ user/18878661 ・ めざすくん user/27507212
わるよい user/3953893 ・ ゆ〜の user/2915294
sou user/11352489 ・ モッチチ user/6511183 ・ 海鼠 user/4114082
じゅんじゅ@\( ・ω・)/ www.nicovideo.jp/user/41124243
元グリーンベレー user/13675361 ・ lalala user/2765923
蘭‐Ran‐ user/18878661 ・ めざすくん user/27507212
わるよい user/3953893 ・ ゆ〜の user/2915294
sou user/11352489 ・ モッチチ user/6511183 ・ 海鼠 user/4114082
2024/03/11(月) 21:21:31.64
イモグラの画像、保存できてない時有るな
2024/03/15(金) 02:19:07.21
ビタミーナ王国物語以外でイモグラなんてワードを見かけるとは夢にも思わなかった
2024/03/15(金) 03:07:50.06
【保存・記録】ウェブアーカイブ総合 Page.02
https://mevius.5ch.net/test/read.cgi/internet/1700519014/
https://mevius.5ch.net/test/read.cgi/internet/1700519014/
2024/03/15(金) 16:03:39.90
imgur 画像のリファラ検査が始まり、直リンが禁止されてアーカイヴできなくなった。
https://i.imgur.com/8oRShxz.jpeg
↓
https://imgur.com/8oRShxz
ページ内の埋め込み画像はリファラが送られるが、この URL では駄目。
↓
https://imgur.com/8oRShxz/embed
この URL のアーカイヴを保存させればよい。
↓
結果
https://web.archive.org/web/20240315065808im_/i.imgur.com/8oRShxzl.jpg
https://i.imgur.com/8oRShxz.jpeg
↓
https://imgur.com/8oRShxz
ページ内の埋め込み画像はリファラが送られるが、この URL では駄目。
↓
https://imgur.com/8oRShxz/embed
この URL のアーカイヴを保存させればよい。
↓
結果
https://web.archive.org/web/20240315065808im_/i.imgur.com/8oRShxzl.jpg
2024/03/16(土) 14:31:32.48
2024/03/17(日) 02:41:47.70
dotupがやたらと嫌われてたけど俺はimgurの方が嫌いだわ( ´_ゝ`)
2024/03/20(水) 18:03:48.97
Loadingでずっと進まないんだけど
今archive.todayってTwitter保存できないの?
archive.orgの方は出来るみたいだけど
アドレスが長くなるからtodayの方を使いたい
>>342
関係ないけど
リファラ検査で出始めたJaneのimgurサムネイルエラーは
https://egg.5ch.net/test/read.cgi/software/1708963746/185n
で回避した
今archive.todayってTwitter保存できないの?
archive.orgの方は出来るみたいだけど
アドレスが長くなるからtodayの方を使いたい
>>342
関係ないけど
リファラ検査で出始めたJaneのimgurサムネイルエラーは
https://egg.5ch.net/test/read.cgi/software/1708963746/185n
で回避した
2024/03/20(水) 18:47:49.51
>>346
なんだ山下の犬か
なんだ山下の犬か
2024/03/22(金) 05:15:15.83
NHKが運営するネット上の特設ページ、続々と運営終了。放送法改正を見据えた動きか
https://internet.watch.impress.co.jp/docs/yajiuma/1577805.html
2024年4月1日10:00をもちまして、以下特設ページの掲載を終了(番組ストリーミングを含む)いたします。(NHKゴガク)
https://www.nhk.or.jp/gogaku/
NHK、「政治マガジン」など6サイト更新停止へ 新サービスを検討(朝日新聞デジタル)
https://www.asahi.com/articles/ASS375VHPS36UCVL04P.html
NHKやばいな。どんどんデジタルサービス終了させている。声調確認くんとか、凄く良かったのに。デジタル頑張っていた中の人たちが気の毒。(Togetter)
https://togetter.com/li/2334548
https://internet.watch.impress.co.jp/docs/yajiuma/1577805.html
2024年4月1日10:00をもちまして、以下特設ページの掲載を終了(番組ストリーミングを含む)いたします。(NHKゴガク)
https://www.nhk.or.jp/gogaku/
NHK、「政治マガジン」など6サイト更新停止へ 新サービスを検討(朝日新聞デジタル)
https://www.asahi.com/articles/ASS375VHPS36UCVL04P.html
NHKやばいな。どんどんデジタルサービス終了させている。声調確認くんとか、凄く良かったのに。デジタル頑張っていた中の人たちが気の毒。(Togetter)
https://togetter.com/li/2334548
2024/03/23(土) 15:57:54.15
特許や意匠権の参考文献にURLが記載されてる事って多いんだけどさ
昔のホームページだと404かつ何処にもアーカイブされてないとかざら何だよな
せめてその辺は国がアーカイブしないと将来的に困ったことにならんのか?と思う
昔のホームページだと404かつ何処にもアーカイブされてないとかざら何だよな
せめてその辺は国がアーカイブしないと将来的に困ったことにならんのか?と思う
2024/03/23(土) 18:36:41.16
今死んでるな?
2024/03/23(土) 20:47:29.68
>>349
この国の政府って困ったことに未来にも過去にも興味が全くないですよ
この国の政府って困ったことに未来にも過去にも興味が全くないですよ
352名無しさん@お腹いっぱい。
2024/03/24(日) 02:26:23.042024/03/24(日) 13:22:02.87
>>352
これ特許庁自体は保存されてるけど、参考文献URLまで保存されてるってどこかに書いてある?
これ特許庁自体は保存されてるけど、参考文献URLまで保存されてるってどこかに書いてある?
2024/03/25(月) 09:41:34.78
https://archive.org/web/images/icon_savePage.png
なぜか "Save Page Now" の前のアイコンが
https://archive.org/about/404.html へリダイレクトされてしまっている。

なぜか "Save Page Now" の前のアイコンが
https://archive.org/about/404.html へリダイレクトされてしまっている。

2024/03/28(木) 12:58:45.39
現在繋がらない?
2024/03/28(木) 13:00:30.23
15分くらい前まで繋がってたけど今は繋がらないね、Temporarily Offlineだからメンテ中かな
2024/03/28(木) 13:39:19.92
ttps://twitter.com/textfiles/status/1773203790159565077
また停電だってよ去年もあったね
https://twitter.com/thejimwatkins
また停電だってよ去年もあったね
https://twitter.com/thejimwatkins
2024/03/28(木) 14:33:39.21
503エラーちょこちょこ出るけど、復帰したね乙でした
2024/03/28(木) 15:36:57.20
Queue-Itの待合室経由みたいに、いったんリダイレクトされてJavascript動作してから本サイトにリダイレクトされるようなサイトはどうやってアーカイブするの?
save page nowではなくて、自PCでアクセスして表示したページをそのままアーカイブできる機能とかあればしりたい。
save page nowではなくて、自PCでアクセスして表示したページをそのままアーカイブできる機能とかあればしりたい。
2024/03/29(金) 09:32:43.89
詐欺紛いのサイトがアーカイブを徹底的に拒否しているのは笑える
https://www.sotwe.com/DuceTCG
https://www.sotwe.com/DuceTCG
2024/03/29(金) 09:45:43.27
>>360
拒否してるのはサイトじゃなくてTwitterWebViewerの方だった。俺の勘違い
拒否してるのはサイトじゃなくてTwitterWebViewerの方だった。俺の勘違い
2024/03/29(金) 09:53:56.79
2024/04/01(月) 14:58:37.43
UAによって弾いてるぽい
2024/04/02(火) 02:31:48.54
imgur、画像の直リンは無理だとしても postpagebeta=0 というクッキーを食べたことにして
こういうアーカイブを取れば行けるなぁ。
つまり capture_cookie パラメータを使用。
https://web.archive.org/web/1/imgur.com/EwuqXZU
こういうアーカイブを取れば行けるなぁ。
つまり capture_cookie パラメータを使用。
https://web.archive.org/web/1/imgur.com/EwuqXZU
2024/04/02(火) 02:48:58.54
これは失敗。
https://web.archive.org/web/1/imgur.com/sBfrwVv
imgur でアダルト判定を食らった画像を表示させて "Yes, I'm over 18" をクリックしたときに追加されるクッキーの中に
over18=1 ってのがあるけど、それも食べたことにすれば行けるかな。
https://web.archive.org/web/1/imgur.com/sBfrwVv
imgur でアダルト判定を食らった画像を表示させて "Yes, I'm over 18" をクリックしたときに追加されるクッキーの中に
over18=1 ってのがあるけど、それも食べたことにすれば行けるかな。
2024/04/02(火) 02:59:57.86
2024/04/02(火) 15:12:43.62
SPNではできないやつ?
2024/04/02(火) 19:17:02.33
どうも postpagebeta=0 のクッキーだけ送っておけば、
リファラ無しの画像直リンでも OK っぽいな。
>>367
スクリプト使うのも Save Page Now のページを使うのも、やってる事は全く同じなんだけど
後者では入力できないパラメータを送る必要があるんだよね。
https://web.archive.org/save/ を表示させて、次のブックマークレットで入力欄を追加してから
上の欄に imgur の画像 URL、下の欄に postpagebeta=0 を入力してボタンを押せば
たぶん保存できる。
https://pastebin.com/uEZ1Dbqi
リファラ無しの画像直リンでも OK っぽいな。
>>367
スクリプト使うのも Save Page Now のページを使うのも、やってる事は全く同じなんだけど
後者では入力できないパラメータを送る必要があるんだよね。
https://web.archive.org/save/ を表示させて、次のブックマークレットで入力欄を追加してから
上の欄に imgur の画像 URL、下の欄に postpagebeta=0 を入力してボタンを押せば
たぶん保存できる。
https://pastebin.com/uEZ1Dbqi
369インターネットアーカイブ
2024/04/02(火) 23:58:17.492024/04/04(木) 04:15:40.02
>>368
保存できていたのに保存できなくなったぽい?
保存できていたのに保存できなくなったぽい?
2024/04/04(木) 05:45:40.47
2024/04/04(木) 13:26:28.62
imgur の画像直リンが、クッキーを付けてあってもリダイレクトされるようになってしまったかも。
それでも拡張子の無い https://imgur.com/xxxxxxx 形式の URL を
クッキー付きでアーカイブさせれば、画像にはリファラが送られるので保存はできている。
それでも拡張子の無い https://imgur.com/xxxxxxx 形式の URL を
クッキー付きでアーカイブさせれば、画像にはリファラが送られるので保存はできている。
2024/04/06(土) 22:10:26.61
Resources (ページ内画像等) としてアーカイブされた URL がカレンダ表示に登場するまでに
時間が掛かってる
時間が掛かってる

2024/04/07(日) 12:36:44.17
APIでリファラも送れるようにしてくれないかな
cookieやUAは送れるのにリファラは対応してないの何で?
cookieやUAは送れるのにリファラは対応してないの何で?
2024/04/07(日) 16:46:14.94
間違った転送先を保存してしまい何故か修正できないヤツ
https://web.archive.org/web/20240407072915/https://i.imgur.com/UtKDI8X.jpeg
アニメ絵と実写エロ注意
https://web.archive.org/web/20240407072915/https://i.imgur.com/UtKDI8X.jpeg
アニメ絵と実写エロ注意
2024/04/07(日) 17:16:13.24
大文字小文字違いかw
uTKdi8x
UtKDI8X
uTKdi8x
UtKDI8X
2024/04/08(月) 16:06:38.65
archive.today
数日前からX(旧Twitter)のアーカイブできなくなってる?
数日前からX(旧Twitter)のアーカイブできなくなってる?
378名無しさん@お腹いっぱい。
2024/04/09(火) 18:51:29.66 >>377
自分も、ここ最近X(旧Twitter)のアーカイブが取得できなくて困ってる。
自分も、ここ最近X(旧Twitter)のアーカイブが取得できなくて困ってる。
2024/04/10(水) 21:37:00.24
404だ
380名無しさん@お腹いっぱい。
2024/04/14(日) 14:05:36.49 Not Found
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
381アーカイブ
2024/04/15(月) 06:08:58.29 またイモグラ保存できなくなったんじゃないだろうな
もうイモグラは使わないでくれ
もうイモグラは使わないでくれ
2024/04/15(月) 11:30:27.65
383アーカイブ
2024/04/15(月) 14:34:30.98 OutLinksを使うと保存できてる時もあるっぽいな。
これが原因か?
これが原因か?
384アーカイブ
2024/04/15(月) 16:54:08.33 いや関係無いっぽいな。
試しにスクリプトが上げてるグ□画像を保存してみたらOutLinksなんて無くても一発で取れた。
取れる画像と取れない画像があるのか?
試しにスクリプトが上げてるグ□画像を保存してみたらOutLinksなんて無くても一発で取れた。
取れる画像と取れない画像があるのか?
2024/04/15(月) 21:48:34.29
ゲッ、いつの間に同一URLの保存回数が一日5回までに減ってやがる…
https://web.archive.org/web/0im_/https://files.catbox.moe/xei3k9.PNG
19年の頃は保存回数制限もなく保存再開出来る時間も10分間隔だったんだがなぁ…
https://web.archive.org/web/0im_/https://files.catbox.moe/xei3k9.PNG
19年の頃は保存回数制限もなく保存再開出来る時間も10分間隔だったんだがなぁ…
2024/04/15(月) 21:58:25.42
387アーカイブ
2024/04/16(火) 08:03:08.50 保存回数上限がホスト毎に決められているけど、回数はURL毎に数えているってことか。
2024/04/17(水) 02:34:56.23
自分がアーカイブを取ってるサイトは大概 1 回だけなんだよなぁ。
389名無しさん@お腹いっぱい。
2024/04/19(金) 22:35:13.33 そろそろやばいやばいっていわれてるけど、Archive.liがなくなる事ってあるのかね。
そもそもあいつの資金源どうなってんだ?
そもそもあいつの資金源どうなってんだ?
390名無しさん@お腹いっぱい。
2024/04/19(金) 22:39:26.28 運営費がかさむかさむって言ってたし、ロシアでの運営じゃ厳しいだろ。
国を出ないなら、このまま吹き飛びそうだな。
国を出ないなら、このまま吹き飛びそうだな。
391名無しさん@お腹いっぱい。
2024/04/20(土) 13:11:21.35 【質問】Wayback machineで既に誰かがウェブサイトをアーカイブしていたときサイトのアーカイブは更新されるのか
拡張機能web archivesでwayback machineを選択する→既にアーカイブされている1年前のものが表示される
画像などが保存されていないので現在の最新の状態で完全なものをアーカイブしたいんですが可能なんですかね?やり方がわかりません
gyazo.com/2dea0146024edc6952878c8d25b9b572
拡張機能web archivesでwayback machineを選択する→既にアーカイブされている1年前のものが表示される
画像などが保存されていないので現在の最新の状態で完全なものをアーカイブしたいんですが可能なんですかね?やり方がわかりません
gyazo.com/2dea0146024edc6952878c8d25b9b572
392名無しさん@お腹いっぱい。
2024/04/20(土) 13:57:11.01 Wayback machineで除名を申し入れされたとして、
それはそのウェブサイトは見かけ上保存はできてそうなんだけど閲覧できないだけ?
そのドメインを後から手に入れる事ができ、除名を解いたら、それまでに保存を要請してきたウェブサイトを見る事ができるようになると?
それはそのウェブサイトは見かけ上保存はできてそうなんだけど閲覧できないだけ?
そのドメインを後から手に入れる事ができ、除名を解いたら、それまでに保存を要請してきたウェブサイトを見る事ができるようになると?
393名無しさん@お腹いっぱい。
2024/04/20(土) 13:57:11.53 Wayback machineで除名を申し入れされたとして、
それはそのウェブサイトは見かけ上保存はできてそうなんだけど閲覧できないだけ?
そのドメインを後から手に入れる事ができ、除名を解いたら、それまでに保存を要請してきたウェブサイトを見る事ができるようになると?
それはそのウェブサイトは見かけ上保存はできてそうなんだけど閲覧できないだけ?
そのドメインを後から手に入れる事ができ、除名を解いたら、それまでに保存を要請してきたウェブサイトを見る事ができるようになると?
2024/04/20(土) 15:31:34.61
395名無しさん@お腹いっぱい。
2024/04/23(火) 19:37:25.85 アーカイブチーム、いや、いつもアーカイブしている人たちは全員本当にやる気を感じない
YouTubeの動画のページが公開された時、すぐに保存されないケースが多いし。
YouTubeの動画のページが公開された時、すぐに保存されないケースが多いし。
2024/04/23(火) 20:04:37.85
2024/04/29(月) 03:17:02.51
あー重い重い
2024/04/29(月) 19:58:05.90
ttps://www.courts.go.jp/app/files/hanrei_jp/995/088995_hanrei.pdf
グリーの弁護士、Wayback MachineのURL日付部分を日本時間基準だと勘違いして日付が一致しないとか言ってて草
検証の部分でUTC時間だから問題ないとちゃんと反論されていてよかった、ついでに裁判も負けてる
グリーの弁護士、Wayback MachineのURL日付部分を日本時間基準だと勘違いして日付が一致しないとか言ってて草
検証の部分でUTC時間だから問題ないとちゃんと反論されていてよかった、ついでに裁判も負けてる
399アーカイヴ
2024/04/30(火) 22:20:03.49 さっきまでめっちゃ調子よかったのに503
2024/04/30(火) 22:42:01.31
てかメンテの表示出てるじゃん。今夜はもう無理かな。
>>391 URLをそのままSPNで保存すればいいよ。そうすれば日付違いで保存されて表示されるはず。
>>392-393 前のドメイン権利者が除外要請を出した時と連絡先など一致してなかったり譲渡されたと嘘付いても、解除通るの?
>>395 ArchiveTeamの巡回を待ってるなら、自分でSPNから保存したほうが早いよ。動画ファイルも半分ぐらいの確率で保存してくれる。
削除予告が出ていて緊急なら#down-the-tubeのチャットで理由書いてコマンド打てばいい。量が多いと完璧に保存されないけど失うよりはいいし。両方やっとけば残る確率高くなる。
>>396 てか>>130で文句言ってるXGeNeLWnYdcの動画ファイル保存されてないね。昨日試しにSPNで保存したけど1日経ってもファイル保存されてねえわ。
>>391 URLをそのままSPNで保存すればいいよ。そうすれば日付違いで保存されて表示されるはず。
>>392-393 前のドメイン権利者が除外要請を出した時と連絡先など一致してなかったり譲渡されたと嘘付いても、解除通るの?
>>395 ArchiveTeamの巡回を待ってるなら、自分でSPNから保存したほうが早いよ。動画ファイルも半分ぐらいの確率で保存してくれる。
削除予告が出ていて緊急なら#down-the-tubeのチャットで理由書いてコマンド打てばいい。量が多いと完璧に保存されないけど失うよりはいいし。両方やっとけば残る確率高くなる。
>>396 てか>>130で文句言ってるXGeNeLWnYdcの動画ファイル保存されてないね。昨日試しにSPNで保存したけど1日経ってもファイル保存されてねえわ。
2024/04/30(火) 22:42:04.16
てかメンテの表示出てるじゃん。今夜はもう無理かな。
>>391 URLをそのままSPNで保存すればいいよ。そうすれば日付違いで保存されて表示されるはず。
>>392-393 前のドメイン権利者が除外要請を出した時と連絡先など一致してなかったり譲渡されたと嘘付いても、解除通るの?
>>395 ArchiveTeamの巡回を待ってるなら、自分でSPNから保存したほうが早いよ。動画ファイルも半分ぐらいの確率で保存してくれる。
削除予告が出ていて緊急なら#down-the-tubeのチャットで理由書いてコマンド打てばいい。量が多いと完璧に保存されないけど失うよりはいいし。両方やっとけば残る確率高くなる。
>>396 てか>>130で文句言ってるXGeNeLWnYdcの動画ファイル保存されてないね。昨日試しにSPNで保存したけど1日経ってもファイル保存されてねえわ。
>>391 URLをそのままSPNで保存すればいいよ。そうすれば日付違いで保存されて表示されるはず。
>>392-393 前のドメイン権利者が除外要請を出した時と連絡先など一致してなかったり譲渡されたと嘘付いても、解除通るの?
>>395 ArchiveTeamの巡回を待ってるなら、自分でSPNから保存したほうが早いよ。動画ファイルも半分ぐらいの確率で保存してくれる。
削除予告が出ていて緊急なら#down-the-tubeのチャットで理由書いてコマンド打てばいい。量が多いと完璧に保存されないけど失うよりはいいし。両方やっとけば残る確率高くなる。
>>396 てか>>130で文句言ってるXGeNeLWnYdcの動画ファイル保存されてないね。昨日試しにSPNで保存したけど1日経ってもファイル保存されてねえわ。
2024/04/30(火) 22:49:38.87
>>387
そういえば、ちょっと前にyoutube.comの1日の保存上限で8万回?ってエラー出てた。2年ぐらい前にエラー出た時はもっと数字が大きかった気がするけど。
確実に保存したいなら上限がリセットされるはずの日本時間午前9時から早い者勝ちで保存するしかないみたいだが。
そういえば、ちょっと前にyoutube.comの1日の保存上限で8万回?ってエラー出てた。2年ぐらい前にエラー出た時はもっと数字が大きかった気がするけど。
確実に保存したいなら上限がリセットされるはずの日本時間午前9時から早い者勝ちで保存するしかないみたいだが。
2024/05/02(木) 16:55:42.41
2024/05/04(土) 11:12:18.18
Tor Browser が Internet Archive の .onion 版が利用可能と検出してるけど
繋がらないんだよね・・・コード 0xF2 のエラーが返る
https://archive6zg5vrdwm4ljllgxleekeoj43lqayscd4d4kmhnyblq4h3ead.onion/
繋がらないんだよね・・・コード 0xF2 のエラーが返る
https://archive6zg5vrdwm4ljllgxleekeoj43lqayscd4d4kmhnyblq4h3ead.onion/

2024/05/04(土) 12:01:16.02
またメンテか
次はいつ復旧するのやら
次はいつ復旧するのやら
2024/05/04(土) 15:36:31.33
>>403
今見てみたら、動画ファイルの保存まではできてないみたい。
確認用コード
curl -I "https://web.archive.org/web/2oe_/http://wayback-fakeurl.archive.org/yt/img/XGeNeLWnYdc"
ターミナルで動かしてヘッダー部分だけ取得すると、転送先の動画ファイルURLがlocation:として出てこないで404エラーになってる。
保存されていればgooglevideo.comの長いURLが出てくるはず。保存されるまで何度かSPNで保存繰り返せばいいけど。
今見てみたら、動画ファイルの保存まではできてないみたい。
確認用コード
curl -I "https://web.archive.org/web/2oe_/http://wayback-fakeurl.archive.org/yt/img/XGeNeLWnYdc"
ターミナルで動かしてヘッダー部分だけ取得すると、転送先の動画ファイルURLがlocation:として出てこないで404エラーになってる。
保存されていればgooglevideo.comの長いURLが出てくるはず。保存されるまで何度かSPNで保存繰り返せばいいけど。
2024/05/04(土) 15:36:33.70
>>403
今見てみたら、動画ファイルの保存まではできてないみたい。
確認用コード
curl -I "https://web.archive.org/web/2oe_/http://wayback-fakeurl.archive.org/yt/img/XGeNeLWnYdc"
ターミナルで動かしてヘッダー部分だけ取得すると、転送先の動画ファイルURLがlocation:として出てこないで404エラーになってる。
保存されていればgooglevideo.comの長いURLが出てくるはず。保存されるまで何度かSPNで保存繰り返せばいいけど。
今見てみたら、動画ファイルの保存まではできてないみたい。
確認用コード
curl -I "https://web.archive.org/web/2oe_/http://wayback-fakeurl.archive.org/yt/img/XGeNeLWnYdc"
ターミナルで動かしてヘッダー部分だけ取得すると、転送先の動画ファイルURLがlocation:として出てこないで404エラーになってる。
保存されていればgooglevideo.comの長いURLが出てくるはず。保存されるまで何度かSPNで保存繰り返せばいいけど。
408アーカイヴ
2024/05/05(日) 15:10:31.41 Save Page Now browser crashed on https://imgur.com/p5BPbjq.
2024/05/05(日) 16:04:43.50
何回か連打してればバックグラウンドで保存に成功するケースが殆ど。

2024/05/06(月) 15:54:44.08
archive.todayってMicrosoftのサーバー経由してるのなんで?
MSのサーバーをhostsで遮断したら保存できなくなった
MSのサーバーをhostsで遮断したら保存できなくなった
2024/05/06(月) 21:39:08.18
>>7
quoraもサルベージできない
quoraもサルベージできない
2024/05/11(土) 14:20:52.07
全然違うfaviconが表示されるのってなんなんだろ
2024/05/12(日) 00:23:05.21
なんだこのエラー?
task_id must not be empty. Got None instead.
task_id must not be empty. Got None instead.
414名無しさん@お腹いっぱい。
2024/05/12(日) 15:27:19.16 archiveのアニメをWEBで見てたがすごく遅くて適当にVPNで日本で見たらすぐ見れた
IP規制してる??
IP規制してる??
415名無しさん@お腹いっぱい。
2024/05/16(木) 18:03:20.05 X(twitter)やインスタを保存するのにオススメの方法があったら教えて。
416名無しさん@お腹いっぱい。
2024/05/16(木) 18:57:43.42 すみません。
twitterアカウントを削除する前に、ツイート削除した場合、該当のツイートは見ることできますか??
twitterアカウントを削除する前に、ツイート削除した場合、該当のツイートは見ることできますか??
2024/05/16(木) 19:53:45.33
418名無しさん@お腹いっぱい。
2024/05/16(木) 20:01:40.36 >>417
ありがとうございます!
ありがとうございます!
2024/05/19(日) 09:47:52.15
Amazonの商品ページの過去を見ることできますか?
2024/05/24(金) 14:58:58.03
>>419
見れる(保存されていれば)
見れる(保存されていれば)
421名無しさん@お腹いっぱい。
2024/05/27(月) 03:27:05.36 今落ちてるか?
2024/05/27(月) 03:40:50.05
/save/status 以下の状態取得 API が生きてたりしてるけど他は 503
まぁそんな事もあるさ
まぁそんな事もあるさ
2024/05/27(月) 20:03:17.06
現在503になって繋がらないけど他の方々はどうだろうか?
2024/05/27(月) 23:01:42.52
一瞬繋がったり503に戻ったり
ダメな日だね
ダメな日だね
2024/05/28(火) 00:17:54.53
>>420
確かに昔ブックマークしたのは見れた。
確かに昔ブックマークしたのは見れた。
426346
2024/05/28(火) 01:43:54.31 最近archive.orgは繋がらないことが多いな
imgurの直リンはarchive.orgでは不可だったけど
archive.todayでは問題なく撮れた
ここ今、運営が頭狂でURLが貼れなくなってるね
imgurの直リンはarchive.orgでは不可だったけど
archive.todayでは問題なく撮れた
ここ今、運営が頭狂でURLが貼れなくなってるね
2024/05/28(火) 03:39:21.51
2024/05/28(火) 04:04:36.99
テレビ、ねぇ。
あまり見んからなぁ・・・
あまり見んからなぁ・・・
2024/05/28(火) 11:08:33.41
Yahoo!テレビの番組コメは長年特別扱いのテレ東もしっかり叩かれてたのが良かったのに3月で終わってしまった
2024/05/28(火) 22:27:45.16
昨日繋がらなかったのはどうやらDDOS攻撃食らってたからみたいね
ttps://gigazine.net/news/20240528-internet-archive-under-ddos-attack/
そして今現在また503や504になってるがまたDDOS攻撃食らってるのか…?
ttps://gigazine.net/news/20240528-internet-archive-under-ddos-attack/
そして今現在また503や504になってるがまたDDOS攻撃食らってるのか…?
2024/05/28(火) 22:59:38.15
今日は増しだと思ったら結局
もはや「まぁそんなことも」なんてレベルではない
もはや「まぁそんなことも」なんてレベルではない
2024/05/28(火) 23:45:39.54
なんでこの時期に突然DDOS…
433426
2024/05/28(火) 23:55:23.08 >>430
https://x.com/internetarchive/status/1795451463465845141
Internet ArchiveのTwitterを見れば状況が判ったな
archive.orgで撮れなくてarchive.todayで撮れるサイトが近頃多い
Instagramもarchive.orgでは不可だったけど
archive.todayでは問題なく撮れた
https://x.com/internetarchive/status/1795451463465845141
Internet ArchiveのTwitterを見れば状況が判ったな
archive.orgで撮れなくてarchive.todayで撮れるサイトが近頃多い
Instagramもarchive.orgでは不可だったけど
archive.todayでは問題なく撮れた
2024/05/29(水) 00:14:52.44
>433
使い方の差ではあるのだろうが個人的にはwebarchiveで出来てtodayで出来ない点として
・大容量zip等とかが保存可能かどうか(todayじゃそもそもzipどころかmp4やmp3すら保存出来なかったような…)
・検索エンジンで足がつくか否か(todayの場合割りと簡単に足がつきやすい)
・そしてwebarchiveで言う所のSave outlinks機能があるかどうか
というのが引っかかってね…(ほぼ鯖側に負担がかかるのばっかじゃねえかって話ではあるが…)
使い方の差ではあるのだろうが個人的にはwebarchiveで出来てtodayで出来ない点として
・大容量zip等とかが保存可能かどうか(todayじゃそもそもzipどころかmp4やmp3すら保存出来なかったような…)
・検索エンジンで足がつくか否か(todayの場合割りと簡単に足がつきやすい)
・そしてwebarchiveで言う所のSave outlinks機能があるかどうか
というのが引っかかってね…(ほぼ鯖側に負担がかかるのばっかじゃねえかって話ではあるが…)
2024/05/29(水) 02:47:36.00
today運営の素性がわからんしいつ消えるかもわからんしなー
436名無しさん@お腹いっぱい。
2024/05/29(水) 03:00:41.86 >>427
ギャーーーー!!これ今知った!!!
こういうのも貴重な情報だったのに…なんてこった。・゜・(ノД`)・゜・。
でた蔵はちょくちょく、表からのリンク先のページが無かったりするし
起こされた内容もだいぶ偏ってて不完全なのがどうもなあ…
ギャーーーー!!これ今知った!!!
こういうのも貴重な情報だったのに…なんてこった。・゜・(ノД`)・゜・。
でた蔵はちょくちょく、表からのリンク先のページが無かったりするし
起こされた内容もだいぶ偏ってて不完全なのがどうもなあ…
437 警備員[Lv.2][新芽]
2024/05/29(水) 03:54:52.06 wayback-gsheetsにアップデートはいってて驚いた
438433
2024/05/29(水) 07:19:08.25 >>434
archive.orgで撮って
撮れなかったらarchive.todayを使ってる
todayで撮れてorgで撮れないってどうなのかなって
>>435
それが問題
魚拓サイトなのに魚拓サイトが消えたら元も子もないw
todayはドメインが代わったりして大丈夫なのか感がある
archive.todayはURLがarchive.orgみたいに長くならないのが
5chなんかで使う時には良かったりもする
archive.orgを利用してて思うのは、
全く同じキャプチャが重複して何個も何個も撮られてて無駄だなって事と
セーブ時のSave error pages (HTTP Status=4xx, 5xx)の☑はデフォルト外しといた方が良いんじゃないかって事
archive.orgで撮って
撮れなかったらarchive.todayを使ってる
todayで撮れてorgで撮れないってどうなのかなって
>>435
それが問題
魚拓サイトなのに魚拓サイトが消えたら元も子もないw
todayはドメインが代わったりして大丈夫なのか感がある
archive.todayはURLがarchive.orgみたいに長くならないのが
5chなんかで使う時には良かったりもする
archive.orgを利用してて思うのは、
全く同じキャプチャが重複して何個も何個も撮られてて無駄だなって事と
セーブ時のSave error pages (HTTP Status=4xx, 5xx)の☑はデフォルト外しといた方が良いんじゃないかって事
2024/05/29(水) 07:39:31.64
視野が狭いな
2024/05/29(水) 20:22:01.58
todayのURL、916132832超えたらどうなるの
2024/06/01(土) 15:39:13.02
>>441
アルファベットが6桁になる、今の所は半分程度が使用されてるって数年前のブログに書いてた気がする
てかtodayって毎月30万近くかかってるらしいんだが、どうやって個人で維持できてるのか謎すぎるな・・・
アルファベットが6桁になる、今の所は半分程度が使用されてるって数年前のブログに書いてた気がする
てかtodayって毎月30万近くかかってるらしいんだが、どうやって個人で維持できてるのか謎すぎるな・・・
443名無しさん@お腹いっぱい。
2024/06/04(火) 19:32:52.16 度々すみませんm(_ _)m
一部のツイートを削除してからTwitterアカウントごと削除した場合、waybackmachineに収集されていれば削除した一部のツイート内容も見ることできますか??
一部のツイートを削除してからTwitterアカウントごと削除した場合、waybackmachineに収集されていれば削除した一部のツイート内容も見ることできますか??
2024/06/04(火) 20:38:01.07
445名無しさん@お腹いっぱい。
2024/06/05(水) 23:25:18.82 少なくともXに関してはtodayで取れるようになった
2024/06/06(木) 00:33:39.47
https://archive.is/XV7ro
Web.archive.org is DOWN for everyone.
Web.archive.org is DOWN for everyone.
2024/06/09(日) 06:35:08.16
いつの間にかx.fc2が取れなくなってるし…最悪
2024/06/09(日) 19:25:53.07
えっちなコンテンツが後世に残らなくなってしまう・・・
2024/06/12(水) 21:05:59.49
そろそろアップデートして欲しいなぁ、今風のサイトは取れないのが多くなってきた
450438
2024/06/13(木) 03:57:29.35 archive.todayでもTwitter(𝕏)が
>Something went wrong. Try reloading.
で記録されてしまって撮れなくなった模様
Twitterは、archive.orgで撮ってたのが見れなくなってたりしない?
表示されないのが多過ぎる気がする
Facebookは
archive.todayは撮れて
archive.orgでは撮れなかった
>>449
以前は普通に撮れてたのに
現在は撮れないサイトが多すぎるんだヨネ
>Something went wrong. Try reloading.
で記録されてしまって撮れなくなった模様
Twitterは、archive.orgで撮ってたのが見れなくなってたりしない?
表示されないのが多過ぎる気がする
Facebookは
archive.todayは撮れて
archive.orgでは撮れなかった
>>449
以前は普通に撮れてたのに
現在は撮れないサイトが多すぎるんだヨネ
2024/06/13(木) 07:49:52.66
特殊な構造のサイトが増えているということなんだろうな
2024/06/13(木) 17:33:20.62
Save Page Now could not capture this URL because it was unreachable.
2024/06/15(土) 02:11:44.72
youtubeの動画は取れてるんだけど、コメントが全然関係ない動画のやつになっている
2024/06/15(土) 02:36:09.67
それ、あるある
2024/06/18(火) 20:40:38.93
今日はだめな日
2024/06/18(火) 21:16:17.10
なんか新規取得しないな・・・
2024/06/19(水) 03:18:53.35
2024/06/19(水) 06:13:43.42
無くなる前にアーカイブ
過去ログ見れなくなる前にやっとけばよかったんだがね
https://i.imgur.com/jiMjBYa.jpeg
無くなったら無くなったでURLがわからないと辿れないから
過去ログβが無くなったら辿るのが困難になるのが困るな
一周回ってリンク集の需要が高まるかもしれない
過去ログ見れなくなる前にやっとけばよかったんだがね
https://i.imgur.com/jiMjBYa.jpeg
無くなったら無くなったでURLがわからないと辿れないから
過去ログβが無くなったら辿るのが困難になるのが困るな
一周回ってリンク集の需要が高まるかもしれない
2024/06/19(水) 16:14:18.56
獣姦する女・・・(;`・д・´)
2024/06/20(木) 02:48:05.92
もうずっと不調
461名無しさん@お腹いっぱい。
2024/06/21(金) 20:47:09.19 Twitterのプロフィールまではいけるんだが、そこから画像欄とかいいね欄が見られないのは仕様?
Something went wrong. Try reloading.のエラーが出て不便
Something went wrong. Try reloading.のエラーが出て不便
2024/06/21(金) 23:28:06.31
502 Bad Gateway
2024/06/22(土) 00:35:46.03
>>461
そもそもログインしないと見れなくね?
そもそもログインしないと見れなくね?
2024/06/23(日) 16:16:15.54
ここもかぁ


2024/06/24(月) 10:17:35.84
見たいWebページが「404エラー」になっていたとき、元のページ内容を見る方法はないの?
https://otona-life.com/book/235219/
https://otona-life.com/book/235219/
2024/06/25(火) 23:46:25.84
ファイルの形式による一日の保存回数制限。
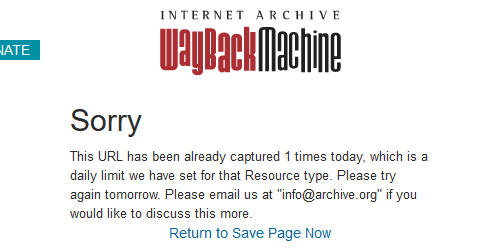

2024/06/27(木) 21:46:14.73
また不調か
2024/06/29(土) 14:49:22.21
10分前から
「Sorry
Cannot start capture」
10分ぐらい前までなんてことなかったのに突然
「Sorry
Cannot start capture」
10分ぐらい前までなんてことなかったのに突然
2024/06/29(土) 15:21:10.49
自作のスクリプトはこんなこと言ってたな。
API が返した JSON の一部の値を印字しているだけだが、メモリオーバーか?
いま再度試したらアーカイブに成功、復活したか。

API が返した JSON の一部の値を印字しているだけだが、メモリオーバーか?
いま再度試したらアーカイブに成功、復活したか。

2024/06/30(日) 11:39:49.24
2024/06/30(日) 12:29:36.36
まだ
Sorry
Cannot start capture
のままだな
Sorry
Cannot start capture
のままだな
2024/06/30(日) 13:12:10.15
俺もSorry Cannot start capture
2024/06/30(日) 16:54:17.08
復旧した…か?
2024/06/30(日) 17:37:13.93
直ったっぽい
2024/07/02(火) 06:27:54.45
インスタは保存できなくなった?
2024/07/02(火) 06:50:38.13
取得に失敗したurlもデイリーリミット300にカウントされるようになってて草
40台しか取れてねえ笑
40台しか取れてねえ笑
477名無しさん@お腹いっぱい。
2024/07/02(火) 11:10:06.062024/07/02(火) 13:27:30.92

2024/07/03(水) 03:23:28.45
リンク集は自分で持ってないと困る&
冗長的に野に放たれてないと価値がない&
リンク先消されたらあまり意味がない
インターネット暗黒時代近づいてるというかもう既に始まってるのかもしれんな
アーカイブも1個や2個じゃ足りないだろ
国は頼りねえし明日はどっちだ
冗長的に野に放たれてないと価値がない&
リンク先消されたらあまり意味がない
インターネット暗黒時代近づいてるというかもう既に始まってるのかもしれんな
アーカイブも1個や2個じゃ足りないだろ
国は頼りねえし明日はどっちだ
2024/07/03(水) 12:09:48.80
始まってるな
右から左にコピペしたかのようなキュレーションブログの乱立と
誤情報や嘘、政治的活動で溢れるSNSの台頭
右から左にコピペしたかのようなキュレーションブログの乱立と
誤情報や嘘、政治的活動で溢れるSNSの台頭
2024/07/03(水) 18:32:50.24
既存のブログやショッピングサイトなどをコピーしたものにマルウェアを仕込んでいる外国ccTLDのサイトとかもだな
そんなのが検索サイトで検索結果上位に出てくる始末
そんなのが検索サイトで検索結果上位に出てくる始末
482名無しさん@お腹いっぱい。
2024/07/05(金) 10:20:12.61 今必死にフォレストページの好きなサイトアーカイブしてるけど、一日200回の制限がキツいわ...
2024/07/05(金) 11:18:21.68

484名無しさん@お腹いっぱい。
2024/07/05(金) 21:39:10.33 スプシでアウトリンク有りにして1000個くらいアーカイブすればあっという間に5万件の制限かかるぞ
485名無しさん@お腹いっぱい。
2024/07/05(金) 21:45:39.28 typoした4万件だわごめん
https://i.ibb.co/z5r50gD/20240705214230.webp
https://i.ibb.co/z5r50gD/20240705214230.webp
2024/07/05(金) 23:58:42.35
アカウント作れよ
2024/07/05(金) 23:59:31.26
>>484
アウトリンクってjsとか画像とかしょっちゅう取り逃がすからあんまり使えないよな
アウトリンクってjsとか画像とかしょっちゅう取り逃がすからあんまり使えないよな
488名無しさん@お腹いっぱい。
2024/07/06(土) 05:12:31.93 ページの数が多かったらだるいけどそうじゃないなら適当な拡張機能でページ内のリンク全部取得すればいいだけだから使いようによってはかも
アカウントにあまりあったから482のやつ手伝おうかと思って試したんだけど、検索結果にでてくるHPがおくれて描画されるせいでアウトリンクにかからないのがしんどくてやめた
数千ページもちまちまURL取得するわけにもいかんし
こういうときにささっとスクリピングのスクリプト書いてURL取得するスキルが有ればずっと楽なんだろうけどね(泣)
アカウントにあまりあったから482のやつ手伝おうかと思って試したんだけど、検索結果にでてくるHPがおくれて描画されるせいでアウトリンクにかからないのがしんどくてやめた
数千ページもちまちまURL取得するわけにもいかんし
こういうときにささっとスクリピングのスクリプト書いてURL取得するスキルが有ればずっと楽なんだろうけどね(泣)
489名無しさん@お腹いっぱい。
2024/07/06(土) 17:09:45.88 今って一日4万件だけなのかもっと多くなかったっけ
2024/07/07(日) 22:44:32.87
>>489
Save Page Now 2 Public API の User Status 応答の変遷(日本時間午前9時過ぎ)
2023/02/18(土) {"available":6,"daily_captures":0,"daily_captures_limit":100000,"processing":0} この日から記録を始めた
2023/08/21(月) {"available":6,"daily_captures":0,"daily_captures_limit":80000,"processing":0}
2023/09/06(水) {"available":6,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/09/29(金) {"available":8,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/11/23(木) {"available":8,"daily_captures":0,"daily_captures_limit":50000,"processing":0}
2023/12/12(火) {"available":7,"daily_captures":0,"daily_captures_limit":30000,"processing":0}
2023/12/17(日) {"available":8,"daily_captures":0,"daily_captures_limit":50000,"processing":0}
2024/02/24(土) {"available":7,"daily_captures":0,"daily_captures_limit":40000,"processing":0}
2024/02/29(木) {"available":7,"daily_captures":0,"daily_captures_limit":30000,"processing":0}
2024/03/14(木) {"available":7,"daily_captures":0,"daily_captures_limit":40000,"processing":0}
Save Page Now 2 Public API の User Status 応答の変遷(日本時間午前9時過ぎ)
2023/02/18(土) {"available":6,"daily_captures":0,"daily_captures_limit":100000,"processing":0} この日から記録を始めた
2023/08/21(月) {"available":6,"daily_captures":0,"daily_captures_limit":80000,"processing":0}
2023/09/06(水) {"available":6,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/09/29(金) {"available":8,"daily_captures":0,"daily_captures_limit":70000,"processing":0}
2023/11/23(木) {"available":8,"daily_captures":0,"daily_captures_limit":50000,"processing":0}
2023/12/12(火) {"available":7,"daily_captures":0,"daily_captures_limit":30000,"processing":0}
2023/12/17(日) {"available":8,"daily_captures":0,"daily_captures_limit":50000,"processing":0}
2024/02/24(土) {"available":7,"daily_captures":0,"daily_captures_limit":40000,"processing":0}
2024/02/29(木) {"available":7,"daily_captures":0,"daily_captures_limit":30000,"processing":0}
2024/03/14(木) {"available":7,"daily_captures":0,"daily_captures_limit":40000,"processing":0}
2024/07/07(日) 23:01:26.63
503出てる
2024/07/08(月) 01:28:10.83
メンテか
2024/07/08(月) 05:31:22.66
メンテ終了したようだ
2024/07/08(月) 11:32:24.08
イモグラはどうでも良いグロ画像をキャプチャしたら取れた。
肝心なヤツはいつも取れない
肝心なヤツはいつも取れない
2024/07/09(火) 12:17:06.83
496あぼーん
NGNGあぼーん
2024/07/09(火) 16:18:52.82
ネットサービス板にスクリプト荒らし登場、か。
498あぼーん
NGNGあぼーん
2024/07/09(火) 19:15:27.15
5ch取ったらitestに飛ばされるようになったのか
2024/07/10(水) 00:58:57.63
またつながらない
2024/07/10(水) 01:35:04.90
つながった
2日前ほど時間がかからずに済んだ
2日前ほど時間がかからずに済んだ
2024/07/10(水) 08:03:41.68
数時間前にアーカイブを表示しようとURLを検索したら503エラー。今も直らない
503名無しさん@お腹いっぱい。
2024/07/15(月) 19:53:32.26 wayback-gsheets のキューが進まない。。。
2024/07/17(水) 18:56:41.27
866 billionから更新されんな
2024/07/18(木) 21:31:39.79
Vector がホームページサービスを終了だとよ。ダウンロードサービスは継続。
https://www.itmedia.co.jp/news/articles/2407/18/news117.html
https://www.itmedia.co.jp/news/articles/2407/18/news117.html
2024/07/19(金) 02:49:14.00
hpの方に詳しい情報を載せてる作者もままいるから損失もそれなりの規模だなぁ
なんもかんもなくなる日本
なんもかんもなくなる日本
2024/07/19(金) 08:43:01.22
まるで日本以外ではなんもかんも残ってるかのようだ
2024/07/19(金) 14:01:49.76
あら?503になって繋がらない…
onion版も一昨日から繋がらないしどうしたんだろ…
onion版も一昨日から繋がらないしどうしたんだろ…
2024/07/19(金) 17:12:03.45
いま復活してるけどちゃんと取れるか心配だ
2024/07/19(金) 17:36:17.10
取れないよ
2024/07/20(土) 14:59:01.95
ふむふむ
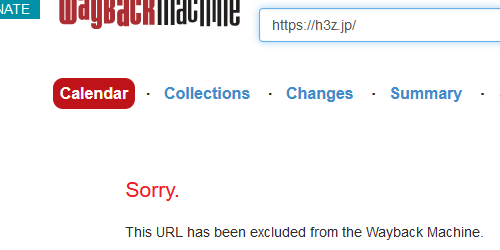

2024/07/21(日) 15:23:45.67
除外URLって異議申し立て出来ないの?
noteとかメルアドが漏洩した当時はログを消すのは理由があったけど
今でも出来ないのはビジネスの都合なだけじゃん
noteとかメルアドが漏洩した当時はログを消すのは理由があったけど
今でも出来ないのはビジネスの都合なだけじゃん
2024/07/22(月) 00:05:43.81
2024/07/22(月) 14:02:01.82
まぁどうしても保存したきゃ手間がかかって七面倒な上に証拠能力としての価値はスクショ同然になる問題点はあるがmht保存機能やらを使ってページをローカル保存して足が付きにくいように無関係な適当なファイル名やらに変更した上で難解なパスワード入れて圧縮したzipやら7zやらを適当なロダに上げて直リンをwebarchiveや20MB以内ならウェブ魚拓に保存すると言う奥の手も無くもない。
2024/07/22(月) 15:53:24.11
重いからか知らんけどCollections情報見えないな
2024/07/25(木) 20:09:51.21
1週間近く接続終わってるな
517名無しさん@お腹いっぱい。
2024/07/29(月) 07:20:04.82 xを保存したいんですけど、archive.orgは方法ありますか?
archive.phはいけるんですけど…
archive.phはいけるんですけど…
518名無しさん@お腹いっぱい。
2024/07/29(月) 08:30:28.47 今はarchive.phへ取ったTweetのURL( archive.ph/〜 )で、再びorgへ取れるようになってるんじゃない?
519名無しさん@お腹いっぱい。
2024/07/29(月) 08:31:05.15 ・・・今春辺りまで1年以上、ph内のアーカイブ済みページはorgへ再取り出来ない不便が続いてたみたいだけどさ。
2024/07/30(火) 14:02:34.70
ページ取得ミスする頻度が最近高すぎる・・・
そのくせに再取得まで時間空けなきゃいけないから面倒
そのくせに再取得まで時間空けなきゃいけないから面倒
2024/07/30(火) 19:25:54.71
寄付少なくて維持が大変なのかな
2024/07/30(火) 19:45:59.34
画像が取れないうえに何度やっても失敗する
2024/08/01(木) 01:14:56.77
Archive制限が多いな、結局mdへ取るしかなかったり。
2024/08/01(木) 14:20:28.07
https://www.itmedia.co.jp/news/articles/2408/01/news124.html
カカクコムは8月1日、アニメやゲームなど“アキバ系”のカルチャーを紹介する情報サイト「アキバ総研」を9月30日に終了すると発表した。
2002年8月の開設から22年の歴史に幕を閉じる。
終了後、記事やレビュー、投票など各種コンテンツはすべて閲覧できなくなる。
https://akiba-souken.com/article/66874/
カカクコムは8月1日、アニメやゲームなど“アキバ系”のカルチャーを紹介する情報サイト「アキバ総研」を9月30日に終了すると発表した。
2002年8月の開設から22年の歴史に幕を閉じる。
終了後、記事やレビュー、投票など各種コンテンツはすべて閲覧できなくなる。
https://akiba-souken.com/article/66874/
2024/08/01(木) 20:28:10.53
ページングが生きてるけど、最古のが2012-01-13。それより前の記事は一覧取れないのかな
https://akiba-souken.com/article/?page=2566
https://akiba-souken.com/article/14614/
タグ検索すると2010-05-21のも取れるから、どこかでインデックス切れてるのかな
https://akiba-souken.com/article/search/tag/?tag=%E5%BA%97%E8%88%97&page=69
https://akiba-souken.com/article/9017/
番号全部漁るしか無いのかな
https://akiba-souken.com/article/?page=2566
https://akiba-souken.com/article/14614/
タグ検索すると2010-05-21のも取れるから、どこかでインデックス切れてるのかな
https://akiba-souken.com/article/search/tag/?tag=%E5%BA%97%E8%88%97&page=69
https://akiba-souken.com/article/9017/
番号全部漁るしか無いのかな
2024/08/01(木) 21:21:55.59
22年も続いたのかあ・・・
2024/08/02(金) 12:49:22.59
>>525
元々アキバ総研の使ってた古いドメインは( http://akiba.kakaku.com/ )。
しかし最古のTopアーカイブが2007年なんで、もっと前はさらに別かな?
《 アキバ(秋葉原)の最新情報がわかる!アキバ総研
http://web.archive.org/web/20070112154118/http://akiba.kakaku.com/ 》
元々アキバ総研の使ってた古いドメインは( http://akiba.kakaku.com/ )。
しかし最古のTopアーカイブが2007年なんで、もっと前はさらに別かな?
《 アキバ(秋葉原)の最新情報がわかる!アキバ総研
http://web.archive.org/web/20070112154118/http://akiba.kakaku.com/ 》
528名無しさん@お腹いっぱい。
2024/08/02(金) 18:12:57.732024/08/02(金) 19:06:34.60
2002 年 8 月 26 日開設、その 3 日後のキャプチャ。
https://web.archive.org/web/20020829160703/kakaku.com/akiba/
https://web.archive.org/web/20020829160703/kakaku.com/akiba/
530名無しさん@お腹いっぱい。
2024/08/02(金) 19:37:59.44 比較的単純だから取りやすそう
2024/08/02(金) 22:58:13.55
>>529
J-Sky H" Palm PDA Lモード って時代を感じるな…
J-Sky H" Palm PDA Lモード って時代を感じるな…
2024/08/03(土) 00:12:56.02
YouTubeで消えた動画見ようとしてもCookieの認証が云々って出てそこから進めないんやが
Cookieはどうやって対策するのか、誰か教えてくれると助かる
Cookieはどうやって対策するのか、誰か教えてくれると助かる
2024/08/03(土) 02:08:46.06
再生画面すら保存しきれていない動画で
動画本体までアーカイブされているもんかねぇ
動画本体までアーカイブされているもんかねぇ
2024/08/03(土) 09:23:37.85
【 ■5ちゃんねる■過去ログ・過去ログ倉庫■運用情報・不具合報告■
http://agree.5ch.net/test/read.cgi/operate/1697962402/
93 名前:[sage] 投稿日:2024/03/07(木) 13:54 ID:
https://kohada.5ch.net/test/read.cgi/kankon/1369777130/
だめだ みれない
97 名前:[sage] 投稿日:2024/03/08(金) 14:12:29.76 ID:zwv+kDuO0
>> 93
http://mimizun.com/log/2ch/kankon/1369777130/
120 名前:[] 投稿日:2024/04/02(火) 13:04:41.44 ID:
ジムが何年前のインタビューで匿名掲示板バブルは過去の話しだと語っていたから今の5chでは現状維持が精一杯で過去ログ復旧にまで回せる資金はないだろね
153 名前:[sage] 投稿日:2024/05/01(水) 15:59:47.12 ID:
みみずん検索で我慢だな 】
535名無しさん@お腹いっぱい。
2024/08/03(土) 15:46:23.33 最近サ終したサイトってでんファミwiki以外になにかある?
536名無しさん@お腹いっぱい。
2024/08/04(日) 08:04:52.78 トップにリダイレクトされるのって仕様?
https://web.archive.org/web/20240803200528/https://akiba-souken.com/vote/v_1111/
https://web.archive.org/web/20240803200528/https://akiba-souken.com/vote/v_1111/
2024/08/04(日) 09:06:33.03
>>536
view-source:https://web.archive.org/web/20240803200528id_/akiba-souken.com/vote/v_1111/
144 行目にホスト名が akiba-souken.com かどうかのチェックが入ってる。
view-source:https://web.archive.org/web/20240803200528id_/akiba-souken.com/vote/v_1111/
144 行目にホスト名が akiba-souken.com かどうかのチェックが入ってる。

538名無しさん@お腹いっぱい。
2024/08/04(日) 09:40:43.69 >>537
つまりリダイレクトされちゃうからアーカイブとってもweb.archive.org上では閲覧できない?
つまりリダイレクトされちゃうからアーカイブとってもweb.archive.org上では閲覧できない?
539名無しさん@お腹いっぱい。
2024/08/04(日) 11:46:30.88 >>538
ページ内画像が低質化してしまったり省略されてしまう場合があるけど文章メインで読めりゃいいならCano-Lab等、PC2m系の携帯端末変換スクリプトを通すなり…。
強制リダイレクトを弾ける(無力化)ブラウザがあれば素で開けるだろうけど
―――
http://www.cano-lab.org/pc2m/pc2m.php?_ucb_c=300&_ucb_v=2&_ucb_u=https://web.archive.org/web/20240803200528/https://akiba-souken.com/vote/v_1111/
http://www.cano-lab.org/pc2m/pc2m.php?_ucb_c=300&_ucb_v=2&_ucb_u=https://akiba-souken.com/vote/v_1111/
ページ内画像が低質化してしまったり省略されてしまう場合があるけど文章メインで読めりゃいいならCano-Lab等、PC2m系の携帯端末変換スクリプトを通すなり…。
強制リダイレクトを弾ける(無力化)ブラウザがあれば素で開けるだろうけど
―――
http://www.cano-lab.org/pc2m/pc2m.php?_ucb_c=300&_ucb_v=2&_ucb_u=https://web.archive.org/web/20240803200528/https://akiba-souken.com/vote/v_1111/
http://www.cano-lab.org/pc2m/pc2m.php?_ucb_c=300&_ucb_v=2&_ucb_u=https://akiba-souken.com/vote/v_1111/
2024/08/04(日) 14:31:11.06
CloudFlareの認証画面を使うサイトも増えてきたなぁ
Cookie送れば突破出来るんかな、めんどい・・・
Cookie送れば突破出来るんかな、めんどい・・・
541名無しさん@お腹いっぱい。
2024/08/04(日) 16:25:09.20 >>539
uBoでweb.archive.org##+js(aopr, String.fromCharCode)のルール追加して対処しました!
uBoでweb.archive.org##+js(aopr, String.fromCharCode)のルール追加して対処しました!
542537
2024/08/04(日) 19:12:55.52543名無しさん@お腹いっぱい。
2024/08/04(日) 19:20:57.892024/08/05(月) 06:48:22.40
archive.today死んでるね
2024/08/05(月) 13:28:21.41
>>536
disable javascriptすれば見れるけど…
disable javascriptすれば見れるけど…
2024/08/06(火) 13:21:50.81
ドメイン毎の統計情報見れるようになったって事かこれ?
https://web.archive.org/details/tld:com
https://web.archive.org/details/tld:jp
https://web.archive.org/details/tld:com
https://web.archive.org/details/tld:jp
2024/08/07(水) 00:23:01.34
2024/08/07(水) 00:56:45.51
vectorもったいないよなぁ
2024/08/07(水) 03:42:51.14
archive.todayが一部の回線やブラウザを使うとアクセスできないかwelcome to nginxになる状態なんだけどこれどういう状態なんだ…
2024/08/07(水) 03:59:53.62
>>549
回線は関係ないやブラウザの問題だわ
回線は関係ないやブラウザの問題だわ
2024/08/07(水) 06:13:56.55
2024/08/07(水) 06:33:54.20
>>549
archive.today は、Cloudflare DNS Resolver の利用を拒否しているのでDNSの設定を自分でいじったのなら他に戻す
archive.today は、Cloudflare DNS Resolver の利用を拒否しているのでDNSの設定を自分でいじったのなら他に戻す
2024/08/07(水) 07:06:51.47
>>551,552
ありがとうクッキー消したら一旦は普通にアクセス出来るようになったわ
ちょくちょくタイムアウトするのはまた別の問題かしら
あと特定のサイトの画像を保存しようとするとまたwelcom to nginx状態になった
ありがとうクッキー消したら一旦は普通にアクセス出来るようになったわ
ちょくちょくタイムアウトするのはまた別の問題かしら
あと特定のサイトの画像を保存しようとするとまたwelcom to nginx状態になった
2024/08/07(水) 12:59:00.50
2024/08/07(水) 14:10:30.49
>>549
> archive.todayが一部の回線やブラウザを
>
取得済みアーカイブを開く時にブラウザUAが Internet ExplorerだとTopへ飛ばされるんで他へ設定変えなきゃならなくなってる。
> archive.todayが一部の回線やブラウザを
>
取得済みアーカイブを開く時にブラウザUAが Internet ExplorerだとTopへ飛ばされるんで他へ設定変えなきゃならなくなってる。
556あぼーん
NGNGあぼーん
557あぼーん
NGNGあぼーん
558あぼーん
NGNGあぼーん
559あぼーん
NGNGあぼーん
560あぼーん
NGNGあぼーん
561あぼーん
NGNGあぼーん
562あぼーん
NGNGあぼーん
563あぼーん
NGNGあぼーん
564あぼーん
NGNGあぼーん
565あぼーん
NGNGあぼーん
566あぼーん
NGNGあぼーん
2024/08/09(金) 13:11:43.85
ついにここにもスクリプトが来たのか
568あぼーん
NGNGあぼーん
569あぼーん
NGNGあぼーん
2024/08/12(月) 00:29:31.19
IAで、久しぶりにとある人のアカウントを見に行ったら
Uploadsの欄にThis patron has not uploaded any items yet.ってなってるって事は
全部消したか、消されたかってことなんかな?
他のタブを見るとReviewsには1件レビューの履歴があったけど、それだけだった
Uploadsの欄にThis patron has not uploaded any items yet.ってなってるって事は
全部消したか、消されたかってことなんかな?
他のタブを見るとReviewsには1件レビューの履歴があったけど、それだけだった
571名無しさん@お腹いっぱい。
2024/08/13(火) 11:22:16.10 なんじゃこりゃ
https://web.archive.org/web/0im_/https://files.catbox.moe/wcihet.png
https://web.archive.org/web/0im_/https://files.catbox.moe/wcihet.png
2024/08/14(水) 22:49:41.90
2024/08/15(木) 16:30:47.49
いまは一分間に 8 件までアーカイブできるのね。
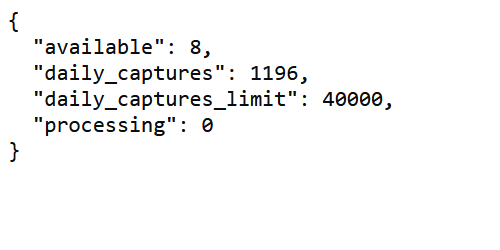

2024/08/15(木) 22:00:30.42
鯖落ちてる?
2024/08/16(金) 23:25:40.50
つながらなくなった
2024/08/16(金) 23:34:34.14
つながった
そこまで長引かなかったのがまだ増しか
そこまで長引かなかったのがまだ増しか
2024/08/17(土) 13:43:40.01
今日は全然取れないな
2024/08/18(日) 01:07:28.04
ここしばらくちゃんと取得したページが表示できるようになるまで1週間以上かかることがザラ
579名無しさん@お腹いっぱい。
2024/08/19(月) 09:27:51.14 Job failed
580名無しさん@お腹いっぱい。
2024/08/19(月) 18:19:27.05 ミルダムは無理だよな・・・
2024/08/20(火) 08:19:14.94
ミルダムって今見てきたけど、アーカイブは元々ほとんど残らないのかな?
何人か見たけど、アーカイブ 動画が0件の人ばっかり。
一人だけ2週間分のアーカイブが残ってる人が居たけど、そんな訳ないし
何人か見たけど、アーカイブ 動画が0件の人ばっかり。
一人だけ2週間分のアーカイブが残ってる人が居たけど、そんな訳ないし
2024/08/20(火) 08:23:05.22
2024/09/01 閉鎖 ミルダム https://support.mildom.com/hc/ja/articles/36550955435161
2024/09/30 閉鎖 アキバ総研 >>524-527
2024/12/20 閉鎖 vectorの作者個人ページ >>505
しかも閉鎖がほぼ10日後?急すぎるし・・・
2024/09/30 閉鎖 アキバ総研 >>524-527
2024/12/20 閉鎖 vectorの作者個人ページ >>505
しかも閉鎖がほぼ10日後?急すぎるし・・・
2024/08/20(火) 09:40:35.76
ミルダムって初めて聞いたw
運営企業とか辿っていくと、単にチャイナリスクが発現しただけにしか見えんな
運営企業とか辿っていくと、単にチャイナリスクが発現しただけにしか見えんな
2024/08/20(火) 19:02:09.02
ミルダム懐かしすぎる
まだあったのか
>>581
作成したアーカイブの保存期間
15日間保存※された後、期間中に一定数視聴がない場合削除されます。
※公式番組や他企業さまとの協賛案件など、運営が必要と判断したアーカイブは除きます。
https://support.mildom.com/hc/ja/articles/360057548353-%E3%82%A2%E3%83%BC%E3%82%AB%E3%82%A4%E3%83%96%E3%81%AE%E4%BF%9D%E5%AD%98-%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6
まだあったのか
>>581
作成したアーカイブの保存期間
15日間保存※された後、期間中に一定数視聴がない場合削除されます。
※公式番組や他企業さまとの協賛案件など、運営が必要と判断したアーカイブは除きます。
https://support.mildom.com/hc/ja/articles/360057548353-%E3%82%A2%E3%83%BC%E3%82%AB%E3%82%A4%E3%83%96%E3%81%AE%E4%BF%9D%E5%AD%98-%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6
2024/08/20(火) 19:26:58.55
サーバー落ちてるな
2024/08/20(火) 21:26:40.09
復帰して個々のアーカイブは表示できるようになったけど
アーカイブ一覧を表示させようとするとエラーが返る
アーカイブ一覧を表示させようとするとエラーが返る

2024/08/21(水) 21:10:42.95
複数窓すると制限かかるのな
2024/08/23(金) 09:27:55.59
オリエント工業が廃業とのこと。
https://web.archive.org/web/20240822083754/www.orient-doll.com/newsSingle/?no=436
昨晩よりテキトーに巡回してアーカイブをとってみたけど、取りこぼしがあるかも。
年齢認証が入ってるので、個別の画像などを除きそのままでのアーカイブは不可。
Web ブラウザで認証を通した後のクッキーを capture_cookie に喰わせれば行ける。
30 分くらいの無通信でセッションが切れるので、その場合は再認証の必要あり。
https://web.archive.org/web/20240822083754/www.orient-doll.com/newsSingle/?no=436
昨晩よりテキトーに巡回してアーカイブをとってみたけど、取りこぼしがあるかも。
年齢認証が入ってるので、個別の画像などを除きそのままでのアーカイブは不可。
Web ブラウザで認証を通した後のクッキーを capture_cookie に喰わせれば行ける。
30 分くらいの無通信でセッションが切れるので、その場合は再認証の必要あり。
2024/08/25(日) 23:26:02.78
連日Job failedばかり
590名無しさん@お腹いっぱい。
2024/08/26(月) 03:42:53.42 重くて使い物にならない
ゴミでしかない
ゴミでしかない
2024/08/26(月) 12:31:29.65
Save outlinksにチェックを入れてsave pageするとJob failedになるくさい?
表向きはログが残らないどこぞの生まれたばかりの掲示板のスレを元画像ごと保存しようとしたら上記のエラーになった…
Save outlinksが導入された当初は垢無しでも出来たのにどんだけ鯖への負担になってるのよこの項目
表向きはログが残らないどこぞの生まれたばかりの掲示板のスレを元画像ごと保存しようとしたら上記のエラーになった…
Save outlinksが導入された当初は垢無しでも出来たのにどんだけ鯖への負担になってるのよこの項目
2024/08/26(月) 15:09:43.56
2024/08/26(月) 15:23:59.23
Job failed と unreachable は数分おきに同じリクエストを繰り返したら
だいたい 3 回か 5 回くらいでアーカイブ成功するね
だいたい 3 回か 5 回くらいでアーカイブ成功するね
2024/08/29(木) 21:16:20.87
wayback-gsheetsはまあまあ問題なさそう
https://i.postimg.cc/gjDx3Gcm/image.png
https://i.postimg.cc/gjDx3Gcm/image.png
2024/08/30(金) 01:17:12.09
アキバ総研について色々調べたんでシェア
2002/08/29 頃にサイトがオープンして、当時のURLはこれ
http://kakaku.com/akiba/
当時の記事URLはこんな感じ。
http://kakaku.com/akiba/hayamimi/06/12/hayamimi20061229_Opteron290.htm
http://kakaku.com/akiba/hobby/06/12/hobby_20061229hobby_newcos.htm
2007年頃からサブドメインになった。
http://akiba.kakaku.com/
http://akiba.kakaku.com/hobby/0701/11/185503.php
http://akiba.kakaku.com/pc/0701/12/204420.php
ここまでの記事は、今は多分全部アクセス出来ない?
akiba-souken.com は2011/09/13 にオープンしたけど、当時はアニメの感想がメインだったっぽい
2012/09/13からニュース記事が配信されるようになって、この頃から記事のURLは以下の形式になった。
https://akiba-souken.com/article/67324/
当時はサイトリニューアル!ってプレスリリースも出していたみたい。
https://corporate.kakaku.com/press/release/20110913
https://corporate.kakaku.com/press/release/20120913
kakakucom配下の記事はもうアクセス出来ないから
今クロールを頑張るなら https://akiba-souken.com/article/[0-70000]/ って感じになるのかな
2002/08/29 頃にサイトがオープンして、当時のURLはこれ
http://kakaku.com/akiba/
当時の記事URLはこんな感じ。
http://kakaku.com/akiba/hayamimi/06/12/hayamimi20061229_Opteron290.htm
http://kakaku.com/akiba/hobby/06/12/hobby_20061229hobby_newcos.htm
2007年頃からサブドメインになった。
http://akiba.kakaku.com/
http://akiba.kakaku.com/hobby/0701/11/185503.php
http://akiba.kakaku.com/pc/0701/12/204420.php
ここまでの記事は、今は多分全部アクセス出来ない?
akiba-souken.com は2011/09/13 にオープンしたけど、当時はアニメの感想がメインだったっぽい
2012/09/13からニュース記事が配信されるようになって、この頃から記事のURLは以下の形式になった。
https://akiba-souken.com/article/67324/
当時はサイトリニューアル!ってプレスリリースも出していたみたい。
https://corporate.kakaku.com/press/release/20110913
https://corporate.kakaku.com/press/release/20120913
kakakucom配下の記事はもうアクセス出来ないから
今クロールを頑張るなら https://akiba-souken.com/article/[0-70000]/ って感じになるのかな
596名無しさん@お腹いっぱい。
2024/08/30(金) 01:39:48.502024/08/30(金) 01:54:10.40
>>596
過去のURLは>>529,527 に書いてあって
後はその中で最古の記事はどれか、最後の記事は何かをチマチマ調べただけ。
"2011年" "アキバ総研" でググったり。
あと、↓のapiでarchiveされてるURLの一覧がドメイン指定で一気に取得出来るから、それをローカルでDBに突っ込んでURL一覧を眺めながら過去どんなサービスがあったのか調べた。
http://web.archive.org/cdx/search/cdx?url=akiba-souken.com&output=json&limit=10&filter=statuscode:200
APIの仕様は以下のページ。
https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server
limitパラメーターを外すと全件出力されるから、curlとかでローカルにファイルとして保存して、それを色々解析するのがいいと思う。
過去のURLは>>529,527 に書いてあって
後はその中で最古の記事はどれか、最後の記事は何かをチマチマ調べただけ。
"2011年" "アキバ総研" でググったり。
あと、↓のapiでarchiveされてるURLの一覧がドメイン指定で一気に取得出来るから、それをローカルでDBに突っ込んでURL一覧を眺めながら過去どんなサービスがあったのか調べた。
http://web.archive.org/cdx/search/cdx?url=akiba-souken.com&output=json&limit=10&filter=statuscode:200
APIの仕様は以下のページ。
https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server
limitパラメーターを外すと全件出力されるから、curlとかでローカルにファイルとして保存して、それを色々解析するのがいいと思う。
598名無しさん@お腹いっぱい。
2024/08/31(土) 07:23:56.542024/09/01(日) 23:23:01.42
連日重たい・・潜在的なバグでもあるんかな
2024/09/02(月) 21:40:47.23
大昔の5ch過去ログも無料では復活しないかもしれぬから、みみずん鯖で保管されてる分だけでも一括アーカイブされればいいけど…。
《 携帯5chブラウザ ぬこ Part181
http://lavender.5ch.net/test/read.cgi/chakumelo/1721834468/
186 名前:携帯電話情報通知[] 投稿日:2024/09/01(日) 22:38 ID:
久しぶりに過去ログ見ようと思ったら、5chサーバ混雑またはサーバ落ちのため、レスを取得できませんでした。しばらく待ってリロードしてください。ってずっと出てくるんだけどもう見れないの?
192 名前:携帯電話情報通知[sage] 投稿日:2024/09/02(月) 06:41 ID:
>> 186
大昔の分はヌコの過去ログ検索でも板の綴りとスレッド数字列まで判明するから mimizunサービスにバックアップされてれば見れる。まあ実況系板はかなり補完漏れ生じてるようだが
〈 WOWOW 17
http://mimizun.com/log/2ch/weekly/1058205020/ 〉 》
2024/09/03(火) 09:12:04.60
いつの間にか2chの過去ログ見れるところが無くなってるんだよな
5ch公式はシステム作り直してます乞うご期待!とか年単位で言ってるし
他の過去ログサイトは全部潰れたし
こういう時にこそscの出番だろ と思って初めてアクセスしたけど、嫌儲みたいな人が多い板はともかくマイナーな板は繋がりもしなかったから全然駄目だ
https://agree.5ch.net/test/read.cgi/operate/1697962402/
5ch公式はシステム作り直してます乞うご期待!とか年単位で言ってるし
他の過去ログサイトは全部潰れたし
こういう時にこそscの出番だろ と思って初めてアクセスしたけど、嫌儲みたいな人が多い板はともかくマイナーな板は繋がりもしなかったから全然駄目だ
https://agree.5ch.net/test/read.cgi/operate/1697962402/
602名無しさん@お腹いっぱい。
2024/09/03(火) 20:56:15.45 >>524
ニュース WEBメディア「アキバ総研」が9月30日でサービス終了へ、惜しむ声続々
WEBメディア「アキバ総研」が2024年9月30日(月)15時をもってサービスを終了することを発表した。
「アキバ総研」ではアニメの最新ニュースのほか、各クール毎に放送されるアニメ一覧の公開やレビュー機能、投票企画や秋葉原の地元ネタなどの掲載で親しまれている。
「アキバ総研」サービス終了のお知らせ
「アキバ総研は、『アニメ&アキバ系カルチャー情報』を発信するメディアとして2002年からコンテンツ提供を続けてまいりましたが、この度、2024年9月30日(月)をもちましてサービスを終了することとなりました、
サービス終了に伴い、記事及びレビュー、投票などはすべて閲覧できなくなります。
改めまして、アキバ総研は2024年9月30日(月)をもちましてサービスを終了いたします、これまでご利用いただき、誠にありがとうございました。」
突然の終了発表を受け、SNSには「サービス終了は正直言って残念です。」・「サービス終了だなんてさみしい。」・「サービス終了と聞いて衝撃を受けた。」・「また一つの時代が終わる。」・「アキバ総研までなくなっちゃうなんて。」と、惜しむ声が続々と上がっている。
ニュース WEBメディア「アキバ総研」が9月30日でサービス終了へ、惜しむ声続々
WEBメディア「アキバ総研」が2024年9月30日(月)15時をもってサービスを終了することを発表した。
「アキバ総研」ではアニメの最新ニュースのほか、各クール毎に放送されるアニメ一覧の公開やレビュー機能、投票企画や秋葉原の地元ネタなどの掲載で親しまれている。
「アキバ総研」サービス終了のお知らせ
「アキバ総研は、『アニメ&アキバ系カルチャー情報』を発信するメディアとして2002年からコンテンツ提供を続けてまいりましたが、この度、2024年9月30日(月)をもちましてサービスを終了することとなりました、
サービス終了に伴い、記事及びレビュー、投票などはすべて閲覧できなくなります。
改めまして、アキバ総研は2024年9月30日(月)をもちましてサービスを終了いたします、これまでご利用いただき、誠にありがとうございました。」
突然の終了発表を受け、SNSには「サービス終了は正直言って残念です。」・「サービス終了だなんてさみしい。」・「サービス終了と聞いて衝撃を受けた。」・「また一つの時代が終わる。」・「アキバ総研までなくなっちゃうなんて。」と、惜しむ声が続々と上がっている。
2024/09/04(水) 13:44:39.02
もうこれ半分インターネット考古学だろ
2024/09/04(水) 20:09:53.72
サ終する時、サ主がIAにデータ提供してから閉めればこっちは保存しなくて済むから楽なんだけどな
2024/09/04(水) 22:14:35.35
公式にそれをしにくいのはまあ分かるけど
せめてURLの一覧をどっかに置いておいてくれたらこっちで登録するんだけどな
例えばアキバ総研の記事は /article/66874/ の数字の部分を上げていけばいいけど
1記事で2ページ目があったり、記事の中に画像があったりするとそっちのURLも登録しないといけない。
せめてURLの一覧をどっかに置いておいてくれたらこっちで登録するんだけどな
例えばアキバ総研の記事は /article/66874/ の数字の部分を上げていけばいいけど
1記事で2ページ目があったり、記事の中に画像があったりするとそっちのURLも登録しないといけない。
2024/09/08(日) 20:42:52.19
TVerプラス【サービス終了のお知らせ】
https://plus.tver.jp/
平素より「TVerプラス」をご利用いただき、誠にありがとうございます。
2024年9月30日をもちまして「TVerプラス」はサービスを終了させて
いただくこととなりました。
長らくのご愛顧、誠にありがとうございました。
https://plus.tver.jp/
平素より「TVerプラス」をご利用いただき、誠にありがとうございます。
2024年9月30日をもちまして「TVerプラス」はサービスを終了させて
いただくこととなりました。
長らくのご愛顧、誠にありがとうございました。
607名無しさん@お腹いっぱい。
2024/09/09(月) 06:43:27.03 ねとらじもいつの間にか終わってた発表から数日で終わりは悲しいな
2024/09/09(月) 07:48:35.37
5ちゃんの過去ログ見れないのは辛い
2024/09/09(月) 15:07:39.03
大昔のはmimizunで開け。
2024/09/09(月) 17:44:19.03
mimizunってまだ生きてたんだな…
試してみたけど、datは取れない感じなのかな
https://mimizun.com/blog/2012/02/post-694.html
http:// mimizun .c om/log/2ch/newsplus/1268106381/ はhtmlで見れるけど
$ curl -i -A "xxx Monazilla/1.00 xxx" "http:// mimizun. c om/log/2ch/newsplus/1268106381.dat"
を指定してもhtmlが返ってくる。
2024年にTwitterで御本人に質問している人が居るけど反応無いっぽい
x[.]com/1010Kui/status/1748324729457639583
試してみたけど、datは取れない感じなのかな
https://mimizun.com/blog/2012/02/post-694.html
http:// mimizun .c om/log/2ch/newsplus/1268106381/ はhtmlで見れるけど
$ curl -i -A "xxx Monazilla/1.00 xxx" "http:// mimizun. c om/log/2ch/newsplus/1268106381.dat"
を指定してもhtmlが返ってくる。
2024年にTwitterで御本人に質問している人が居るけど反応無いっぽい
x[.]com/1010Kui/status/1748324729457639583
2024/09/09(月) 17:45:33.71
from:mimizun 過去ログ とか dat で検索すると過去ログを調べるのに有用な情報が盛り沢山だな
2024/09/09(月) 18:26:29.62
みみずんのデータもいずれ手動登録しなきゃダメなのか
613名無しさん@お腹いっぱい。
2024/09/10(火) 02:47:28.52 twitterとるには結局どうすりゃ良いんだ
todayしかないか
todayしかないか
2024/09/10(火) 13:47:09.33
《 http://yomoyama-bbs.jp/test/read.cgi/2/2817/
3 名前:名無し[sage] 投稿日:2024-09-10 13:21 ID:
Twitter運営はUI改悪しまくりやがって会話ログも検索結果群もアーカイブ不良きたすに堕した。
ミラークライアントのMovatterとか、Nitter鯖の復活増を願うしかない 》
2024/09/10(火) 16:43:42.05
pythonでテキストファイル読み取って
SPNにURL送るようなスクリプト作ったんだが
送る感覚ってどれくらいがいいんだろう
1分に1URLとか?
流石にもっと早くしても鯖負担かからないだろうか
SPNにURL送るようなスクリプト作ったんだが
送る感覚ってどれくらいがいいんだろう
1分に1URLとか?
流石にもっと早くしても鯖負担かからないだろうか
2024/09/10(火) 18:02:46.03
>>615
一年くらい前は立て続けにアクセスすると TCP セッション自体がブロックされたりしてたけど
今は一秒間隔でも多分大丈夫。
とは言っても一分あたりの受け付けリスエスト数の上限があるから
随時 user status を読み取って、上限を超えてたら暫く (※) 待つような仕組みを入れないと
まともに動かないよ。
(※)
上の「一分あたりのリスエスト数」を管理しているカウンタは毎分 00 秒にリセットされる。
マシンの NTP 同期の精度にもよるけど、余裕を見て時計が次の 01 秒とか 05 秒とかになるまで
待たせておけば充分。
一年くらい前は立て続けにアクセスすると TCP セッション自体がブロックされたりしてたけど
今は一秒間隔でも多分大丈夫。
とは言っても一分あたりの受け付けリスエスト数の上限があるから
随時 user status を読み取って、上限を超えてたら暫く (※) 待つような仕組みを入れないと
まともに動かないよ。
(※)
上の「一分あたりのリスエスト数」を管理しているカウンタは毎分 00 秒にリセットされる。
マシンの NTP 同期の精度にもよるけど、余裕を見て時計が次の 01 秒とか 05 秒とかになるまで
待たせておけば充分。
2024/09/10(火) 18:09:39.06
それとは別に、同一サーバの長大ファイル群を連続してアーカイブさせる場合などは
向こうの並行ダウンロードセッション数があまり大きくならないように
こちらで抑えてあげないと、途中でちょん切れたものがアーカイブされてしまうのは
困った話。
向こうの並行ダウンロードセッション数があまり大きくならないように
こちらで抑えてあげないと、途中でちょん切れたものがアーカイブされてしまうのは
困った話。
2024/09/10(火) 20:35:08.79
アーカイブ職人
619名無しさん@お腹いっぱい。
2024/09/11(水) 03:49:37.132024/09/11(水) 06:32:54.48
既にほんの僅かだから復活鯖が増えぬと死んだ時点でオワコンへ…。
2024/09/12(木) 09:36:19.45
Google検索でキャッシュ復活へ Internet Archiveとの提携で
https://www.itmedia.co.jp/news/articles/2409/12/news085.html
https://www.itmedia.co.jp/news/articles/2409/12/news085.html
2024/09/12(木) 10:03:37.77
>>621
URL貼ったついでにアーカイブしておくとか、そういうのは頭に無いんだw
URL貼ったついでにアーカイブしておくとか、そういうのは頭に無いんだw
623名無しさん@お腹いっぱい。
2024/09/12(木) 12:32:19.462024/09/12(木) 14:56:31.65
ググルキャッシュは無くなると言われてたけれどリンクが無くなっただけで今もずっと機能してたしこれがIAに変わるなら今まで知らなかった人たちの削除申請が始まりそうです
2024/09/12(木) 15:03:00.33
消されたページは検索結果に出ないからキャッシュまで来れないだろうし大丈夫じゃね
その辺調べてIAまで辿り着ける人はもともと削除依頼してるだろうし
その辺調べてIAまで辿り着ける人はもともと削除依頼してるだろうし
2024/09/12(木) 16:14:42.67
グーグルキャッシュだと数時間前のキャッシュということも多々あったけど
Internet Archive だと数年前のキャッシュということもありそうだ
Internet Archive だと数年前のキャッシュということもありそうだ
2024/09/12(木) 18:24:45.00
試してみたが、そもそもキャッシュ自体が分かりづらい場所にあるなw
知らない人は見つけられなそう、まぁそっちの方がいいか
知らない人は見つけられなそう、まぁそっちの方がいいか
2024/09/12(木) 20:43:20.91
従来のキャッシュが廃止だと「テキストのみ表示」の機能も喪失となって不便出そう。
2024/09/12(木) 21:12:40.09
グーグルがキャッシュを保持しなくなったら検索すら機能しなくなるだろ
それがアクセスしやすい場所で公開されるかどうかとは別の話
それがアクセスしやすい場所で公開されるかどうかとは別の話
630名無しさん@お腹いっぱい。
2024/09/14(土) 02:50:08.13 archivetodayというゴミサイト開けないが
2024/09/14(土) 16:19:12.35
初歩的なこと聞いていい?
クレカで寄付の時に入れる名前って支援者一覧みたいに公開されたりしないよな?
クレカで寄付の時に入れる名前って支援者一覧みたいに公開されたりしないよな?
2024/09/15(日) 20:28:32.09
>>631
基本的にこういうサイトで寄付者を公開するときは本人の同意が必要なはず
基本的にこういうサイトで寄付者を公開するときは本人の同意が必要なはず
2024/09/15(日) 21:18:10.02
2024/09/16(月) 01:02:59.80
何でそんなに謙虚なんだよ
2024/09/16(月) 12:37:44.51
実名掲載されるのが嫌
同姓同名なんて腐るほどいるだろうけど気分的に
同姓同名なんて腐るほどいるだろうけど気分的に
636名無しさん@お腹いっぱい。
2024/09/16(月) 15:34:54.67 Wayback Machineで呼び出せな…、つまり死んでる
気になる記事があるときに限って
気になる記事があるときに限って
2024/09/18(水) 02:24:57.28
アーカイブ画面上部の時系列バーが復活。
うちの環境では消えてたんだよね、おま環なら広告ブロッカー辺りの設定を見直すわ。

うちの環境では消えてたんだよね、おま環なら広告ブロッカー辺りの設定を見直すわ。

638名無しさん@お腹いっぱい。
2024/09/18(水) 06:24:15.072024/09/18(水) 08:54:29.23
2024/09/19(木) 06:56:34.66
archive.today数日前はキューが1万件以上あって保存まで数時間かかる惨状だったが復調してきたね
リキャプチャ要求される間隔はかなり短くなった
リキャプチャ要求される間隔はかなり短くなった
2024/09/19(木) 19:05:30.37
>>624
> ググルキャッシュは無くなると言われてたけれどリンクが無くなっただけで今もずっと機能してたしこれがIAに変わるなら今まで知らなかった人たちの削除申請が始まりそうです
>
↑今日で旧来のGoogleキャッシュが完全に終わっちまったみたいだ…。
不便増えるわ。
> ググルキャッシュは無くなると言われてたけれどリンクが無くなっただけで今もずっと機能してたしこれがIAに変わるなら今まで知らなかった人たちの削除申請が始まりそうです
>
↑今日で旧来のGoogleキャッシュが完全に終わっちまったみたいだ…。
不便増えるわ。
2024/09/20(金) 20:34:33.75
503か
643名無しさん@お腹いっぱい。
2024/09/22(日) 07:48:48.69 X(旧Twitter)のポスト(ツイート)が取得できない
強制的にZachXBT/status/1425569468755890180?mx=2に飛ばされる
強制的にZachXBT/status/1425569468755890180?mx=2に飛ばされる
644名無しさん@お腹いっぱい。
2024/09/22(日) 07:49:36.70 ちなみにarchivetodayだと取得可能
2024/09/22(日) 16:17:54.58
いつも重いなと思ってたら平日の昼間なら軽くて夜が重かったんだな
646名無しさん@お腹いっぱい。
2024/09/23(月) 18:45:31.132024/09/24(火) 01:28:52.61
Twitter運営にBANされるからもう晒さんでほしかった。
2024/09/24(火) 12:31:51.82
nitterはもう・・・
649名無しさん@お腹いっぱい。
2024/09/25(水) 18:26:45.93 todayでインスタ取れるようになったな
2024/09/25(水) 23:57:41.84
意外とIAって知られてないよね
まあ知られたら知られたで色々規制厳しくなって
アーカイブ消えまくるんだろうけど
アーカイブを増やそうと有名にすればするほど
騒がれてアーカイブが消えていくジレンマ
まあ知られたら知られたで色々規制厳しくなって
アーカイブ消えまくるんだろうけど
アーカイブを増やそうと有名にすればするほど
騒がれてアーカイブが消えていくジレンマ
2024/09/26(木) 05:18:36.77
【 【ネット】ついにGoogle検索のキャッシュ提供が完全終了
http://egg.5ch.net/test/read.cgi/scienceplus/1727269320/
――
ついにGoogle検索のキャッシュ提供が完全終了
http://asahi.5ch.net/test/read.cgi/newsplus/1727231285/
116 名前:名無し[] 投稿日:2024/09/26(木) 05:12 ID:
各大学レポジトリの歴史論文とかPDFだから、HTMLへ変換されたGoogleキャッシュが便利だったのに…。 】
2024/09/26(木) 10:46:57.84
>>601
大昔のスレ参照(共有)するのにスレタイとアドレスは最低持ってないと大変 それでも外部のまとめがヒットするとは限らんし
scは太古のログを持ってない 結構深刻な問題 archiveに入れたかどうかで命運分かれてしまってる
sc発足以降のクロールはまばらだが時々チェックしておくと参考になる 5chのドメイン部分を雑に2ch。scと打ち替えてもリダイレクトされる
実況などのスレ落ち早い板のクロールは苦手だが専門板はわりとまともに動作 メモ用にも使える
5ch新設板とpink系はクロールしない(2chではないため ただ一部例外あるっぽい)
スレ立てスクリプトの被害は5chよりも2chのほうが多大なのでメモスレなどを形成した場合は注意
またクロールしたスレをスレタイ検索で探すのは困難(対応している適当な検索があまりない)なので必要なものは控えをとる
大昔のスレ参照(共有)するのにスレタイとアドレスは最低持ってないと大変 それでも外部のまとめがヒットするとは限らんし
scは太古のログを持ってない 結構深刻な問題 archiveに入れたかどうかで命運分かれてしまってる
sc発足以降のクロールはまばらだが時々チェックしておくと参考になる 5chのドメイン部分を雑に2ch。scと打ち替えてもリダイレクトされる
実況などのスレ落ち早い板のクロールは苦手だが専門板はわりとまともに動作 メモ用にも使える
5ch新設板とpink系はクロールしない(2chではないため ただ一部例外あるっぽい)
スレ立てスクリプトの被害は5chよりも2chのほうが多大なのでメモスレなどを形成した場合は注意
またクロールしたスレをスレタイ検索で探すのは困難(対応している適当な検索があまりない)なので必要なものは控えをとる
2024/09/26(木) 12:53:16.70
>>547
魔法のiランド 2025/03/31にカクヨムに統合
https://maho.jp/info/entry/maho_i_will_no_longer_available
手動でエクスポートインポートする機能が提供されてるけど全ユーザー自動ではないから消える作品も沢山有るんだろうな
コンテンツ本文はjavascriptで書いてるからアーカイヴするには工夫が必要そう
軽く見ただけで2007年とかの作品あるから、消えるのは惜しすぎる…なんとかしたい
魔法のiランド 2025/03/31にカクヨムに統合
https://maho.jp/info/entry/maho_i_will_no_longer_available
手動でエクスポートインポートする機能が提供されてるけど全ユーザー自動ではないから消える作品も沢山有るんだろうな
コンテンツ本文はjavascriptで書いてるからアーカイヴするには工夫が必要そう
軽く見ただけで2007年とかの作品あるから、消えるのは惜しすぎる…なんとかしたい
2024/09/26(木) 13:03:21.46
IA上で適当ながら作品のURLを入れてみたら、ページの保存はされてるけど本文は読めない状態だった。
本文は動的にgraphQLから取得してる。
スクレイピンク時にURLをシャープ込みで正しく指定して、javascriptが実行されれば保存出来そうだがどうかな…
本文は動的にgraphQLから取得してる。
スクレイピンク時にURLをシャープ込みで正しく指定して、javascriptが実行されれば保存出来そうだがどうかな…
655定期
2024/09/26(木) 15:11:36.96【 600 名前:名無しさん[sage] 投稿日:2024/09/02(月) 21:40
大昔の5ch過去ログも無料では復活せぬかもしれんから、みみずん鯖で保管されてる分だけでも一括アーカイブされればいいけど…。
《 携帯5chブラウザ ぬこ Part181
http://lavender.5ch.net/test/read.cgi/chakumelo/1721834468/
186 名前:携帯電話情報通知[] 投稿日:2024/09/01(日) 22:38 ID:
久しぶりに過去ログ見ようと思ったら、5chサーバ混雑またはサーバ落ちのため、レスを取得できませんでした。しばらく待ってリロードしてください。ってずっと出てくるんだけどもう見れないの?
192 名前:携帯電話情報通知[sage] 投稿日:2024/09/02(月) 06:41 ID:
>> 186
大昔の分はヌコの過去ログ検索で板サーバ名の綴りとスレッド数字列まで判明するから mimizunサービスにバックアップされてれば見れる。まあ実況系板はかなり補完漏れ生じてるようだが
〈 WOWOW 17
http://mimizun.com/log/2ch/weekly/1058205020/ 〉 》 】
2024/09/26(木) 15:29:10.14
>>650
明らかにデジタル焚書だよね
明らかにデジタル焚書だよね
2024/09/26(木) 15:32:05.42
ついにGoogle検索のキャッシュ提供が完全終了 [おっさん友の会★]
https://asahi.5ch.net/test/read.cgi/newsplus/1727231285/
https://asahi.5ch.net/test/read.cgi/newsplus/1727231285/
2024/09/26(木) 17:17:30.38
せめてスレッドのホスト名、スレッドキー、タイトルの一覧くらいはどこかで確保したいんだよなあ
2024/09/26(木) 18:16:07.28
去年あたりの規制前に5chのアーカイブしとけば良かったなぁ・・・
まさかこんな事になるとは思わなかった
まさかこんな事になるとは思わなかった
2024/09/27(金) 00:14:10.81
去年に頑張って5chの過去ログを過去サーバー含めてスレタイ一覧スクレイピングしたよな…githubの自分のレポジトリにスクレイピング用のソース残ってるし
と思ったらその後CドライブのSSDが吹っ飛んだからその時に一緒に消えたんだった…
なんJがスレッド数がめちゃくちゃ多くてページ数がすごい事になってた記憶
と思ったらその後CドライブのSSDが吹っ飛んだからその時に一緒に消えたんだった…
なんJがスレッド数がめちゃくちゃ多くてページ数がすごい事になってた記憶
2024/09/27(金) 11:05:15.95
国家事業での保護も民間での保護も法整備も必要
だが当面何一つ進みそうにない我が国
海外勢がやみくもに取得して利益独占しそう(IAも一応これ) 原本がないものの権利の主張は難しいし
だが当面何一つ進みそうにない我が国
海外勢がやみくもに取得して利益独占しそう(IAも一応これ) 原本がないものの権利の主張は難しいし
2024/09/27(金) 21:57:26.30
↓だってさ。
「状況どう?」って聞いたその日にこの書き込みがあったから、まさか「今日ぶっ壊れた」って事は無いだろう。
「アーカイブを展開するところからやり直している」とは一言も書いてないのが気になるんだよなあ…
"アーカイブの展開"は手間がかかってまだ着手してない。つまり本当にアーカイブの中にデータが揃っているかも現状不明で
下手するとアーカイブ出来てませんでした も全然あるよなあ…
■5ちゃんねる■過去ログ・過去ログ倉庫■運用情報・不具合報告■
https://agree.5ch.net/test/read.cgi/operate/1697962402/357
357 名前:Ace ★[] 投稿日:2024/09/27(金) 14:50:10.24 ID:CAP_USER
残念なお知らせです。
過去ログ鯖は着々と作業をしていた模様ですが、物理的にぶっ壊れたそうです。
アーカイブ等はバックアップしているのでネットの彼方に消えたわけでは無いですが、
アーカイブを展開するところまで「振り出しに戻る」という状況です。
363 名前:Ace ★[] 投稿日:2024/09/27(金) 16:39:08.02 ID:CAP_USER
>>362
バックアップはアーカイブ状態なので展開しないと見れません
「状況どう?」って聞いたその日にこの書き込みがあったから、まさか「今日ぶっ壊れた」って事は無いだろう。
「アーカイブを展開するところからやり直している」とは一言も書いてないのが気になるんだよなあ…
"アーカイブの展開"は手間がかかってまだ着手してない。つまり本当にアーカイブの中にデータが揃っているかも現状不明で
下手するとアーカイブ出来てませんでした も全然あるよなあ…
■5ちゃんねる■過去ログ・過去ログ倉庫■運用情報・不具合報告■
https://agree.5ch.net/test/read.cgi/operate/1697962402/357
357 名前:Ace ★[] 投稿日:2024/09/27(金) 14:50:10.24 ID:CAP_USER
残念なお知らせです。
過去ログ鯖は着々と作業をしていた模様ですが、物理的にぶっ壊れたそうです。
アーカイブ等はバックアップしているのでネットの彼方に消えたわけでは無いですが、
アーカイブを展開するところまで「振り出しに戻る」という状況です。
363 名前:Ace ★[] 投稿日:2024/09/27(金) 16:39:08.02 ID:CAP_USER
>>362
バックアップはアーカイブ状態なので展開しないと見れません
2024/09/28(土) 07:06:26.44
ここの運営の言う事なんかまともに信用できないんだから全部ぶっ壊れてる前提でいなきゃだめ
2024/09/28(土) 14:22:54.82
mimizum(みみずん)のログを archive.org へ保全するほうが先決じゃないの?
あすこも何時まで鯖の維持出来るか分からぬだろうし( 既にログ速も Unker も亡くなった… )
あすこも何時まで鯖の維持出来るか分からぬだろうし( 既にログ速も Unker も亡くなった… )
2024/09/28(土) 15:22:11.90
自分だけかもしれないけどアキバ総研のアーカイブした記事を見ようとするとトップに飛ばされる
(魚拓とtodayのは普通に見れる)
(魚拓とtodayのは普通に見れる)
2024/09/28(土) 15:28:22.03
2024/09/28(土) 15:29:25.95
>>664
みみずんって
・datの取得はできなくなっている
・htmlは取得出来る
・ただし、htmlの一覧が無いから総当りするしかない?
と思ってるんだけどどうよ
特にページの一覧が無いとどうしようもない
みみずんって
・datの取得はできなくなっている
・htmlは取得出来る
・ただし、htmlの一覧が無いから総当りするしかない?
と思ってるんだけどどうよ
特にページの一覧が無いとどうしようもない
2024/09/28(土) 15:32:07.82
強制リダイレクトを無効化するブラウザ無かった?
記事文だけならテキストブラウザなり読む方法は色々あるが
記事文だけならテキストブラウザなり読む方法は色々あるが
2024/09/28(土) 15:40:04.04
>>667
かころぐjp の検索結果か、Archive.org 内の各板・過去鯖スレッド一覧アーカイブから末尾キー拾わせてくしかないかもしれない…。
〈 かころぐ kakolog.jp
http://mevius.5ch.net/test/read.cgi/esite/1725790523/ 〉
かころぐjp の検索結果か、Archive.org 内の各板・過去鯖スレッド一覧アーカイブから末尾キー拾わせてくしかないかもしれない…。
〈 かころぐ kakolog.jp
http://mevius.5ch.net/test/read.cgi/esite/1725790523/ 〉
2024/09/28(土) 15:41:45.03
>>668
アキバ総研はjsを無効化してもページ内容読めるから、devtoolから無効化すればchromeでも見れる。
それ以外だと、インターネットアーカイブのリンクをクリックするだけで見れる!とはならないけど
iframeのsandbox属性でjavascript無効にすると見れる。
アキバ総研はjsを無効化してもページ内容読めるから、devtoolから無効化すればchromeでも見れる。
それ以外だと、インターネットアーカイブのリンクをクリックするだけで見れる!とはならないけど
iframeのsandbox属性でjavascript無効にすると見れる。
2024/09/28(土) 15:43:07.34
>>669
とにかくまずはスレッドの一覧を作る所が一番大切だよな…
個人的にはbbspinkも救出したいんだけど、
とにかくサーバー名・板ID(esite)・スレッドキー(1690465133) の3属性があれば特定は出来るか
とにかくまずはスレッドの一覧を作る所が一番大切だよな…
個人的にはbbspinkも救出したいんだけど、
とにかくサーバー名・板ID(esite)・スレッドキー(1690465133) の3属性があれば特定は出来るか
672名無しさん@お腹いっぱい。
2024/09/28(土) 16:33:30.28 URL貼ってもアーカイブが出てこないで直接今のURLが開かれるだけになっているのだが?
2024/09/28(土) 21:49:59.89
アキバ総研もうアカンわ…
どこか引き取れやー!
どこか引き取れやー!
674名無しさん@お腹いっぱい。
2024/09/29(日) 09:27:10.05 >>610
みみずんはhttpsだと開けないからhttpを指定しないといけなくて面倒
みみずんはhttpsだと開けないからhttpを指定しないといけなくて面倒
675名無しさん@お腹いっぱい。
2024/09/29(日) 09:32:54.82676名無しさん@お腹いっぱい。
2024/09/29(日) 09:41:01.97 こういうサービスの終了を見るたびにXanaduが実現していればと思う
ハイパーリンク同士を参照し合う原理上リンク切れが起こらないからアーカイブももっと楽になるはず
ハイパーリンク同士を参照し合う原理上リンク切れが起こらないからアーカイブももっと楽になるはず
2024/09/29(日) 11:41:07.72
>>673
記事が全部InternetArchiveに記録されてるから、一覧表示サイトを作ったで。twitterで検索よろしく
記事が全部InternetArchiveに記録されてるから、一覧表示サイトを作ったで。twitterで検索よろしく
2024/09/29(日) 16:01:41.40
すげえぇeeeーー!
あなたが神か
あなたが神か
2024/09/30(月) 01:15:43.18
アキバ総研は今日の15時に閉鎖
各々思い残しがないように
各々思い残しがないように
2024/09/30(月) 10:55:59.71
インターネット上に放たれた情報は
2度と制御できない不滅って認識だったが
・検索できなくなって埋もれる
・サービス終了して消される
・作者が消す
ほとんどの情報はこの3つのどれかに行き着くのかもしれないな
2度と制御できない不滅って認識だったが
・検索できなくなって埋もれる
・サービス終了して消される
・作者が消す
ほとんどの情報はこの3つのどれかに行き着くのかもしれないな
2024/09/30(月) 15:11:20.27
アキバ総研オワタ「\(^o^)/」
2024/10/01(火) 20:25:24.28
TVerプラスの保全お願いに来たかったんだけど
間に合わなかった…😭
間に合わなかった…😭
2024/10/02(水) 09:53:22.70
zakzakが閉鎖するらしい
ああいうニュースサイトって過去の記事けしまくってるから積極的なアーカイブする必然性は薄いと思ってるんだけどどう?
全記事一覧ページって無いよね?
ああいうニュースサイトって過去の記事けしまくってるから積極的なアーカイブする必然性は薄いと思ってるんだけどどう?
全記事一覧ページって無いよね?
2024/10/07(月) 18:42:17.86
hxh.rakuwiki.com にあるコンテンツ(特に画像)を保存したいと考えています
例 http://hxh.rakuwiki.com/card/2436/
スクショ(青矢印) https://i.ibb.co/QXzjV4g/Screenshot.png
書き込みがエラーでうまくいかないので、内容のスクショとテキストをpastebinに記載しました
内容のスクショ https://img.imageride.net/images/2024/10/07/image.png
pastebin https://paste.gg/p/anonymous/263a8a6e1ddd41c1b43815887822235b/files/e0cf8a0acaca40db990260d2a507e002/raw
なにかよい方法が有りましたらぜひ教えて下さい
例 http://hxh.rakuwiki.com/card/2436/
スクショ(青矢印) https://i.ibb.co/QXzjV4g/Screenshot.png
書き込みがエラーでうまくいかないので、内容のスクショとテキストをpastebinに記載しました
内容のスクショ https://img.imageride.net/images/2024/10/07/image.png
pastebin https://paste.gg/p/anonymous/263a8a6e1ddd41c1b43815887822235b/files/e0cf8a0acaca40db990260d2a507e002/raw
なにかよい方法が有りましたらぜひ教えて下さい
2024/10/07(月) 19:24:54.46
2024/10/07(月) 19:31:20.82
・・・と思ったら、無しでも行けることがあるな。
404 を返す条件がよく解らん。
404 を返す条件がよく解らん。
2024/10/08(火) 01:48:36.49
>>680
AI使ってるせいなのか検索結果がばらばらで本当に困る
AI使ってるせいなのか検索結果がばらばらで本当に困る
2024/10/08(火) 22:45:16.52
20時くらいからずっと↓の画像みたいな感じ
https://archive.is/uddYw/8db426acab07bc6238b207583d8bca29ecc49c16.webp
https://archive.is/uddYw/8db426acab07bc6238b207583d8bca29ecc49c16.webp
2024/10/10(木) 06:56:10.18
690名無しさん@お腹いっぱい。
2024/10/10(木) 07:46:07.35 サイト改竄?により情報漏洩を示唆する謎メッセージが出現
https://i.imgur.com/EdA0dPj.jpeg
↓
セキュリティ大手情報サイト Bleeping Computer によると
3,100万人分のユーザデータの流出していて、本物であることも確認済みとのこと
流出したデータ
・メアド
・表示名
・パスワード変更時間
・Bcryptでハッシュ化されたパスワード など
Internet Archive hacked, data breach impacts 31 million users
https://www.bleepingcomputer.com/news/security/internet-archive-hacked-data-breach-impacts-31-million-users/
https://i.imgur.com/EdA0dPj.jpeg
↓
セキュリティ大手情報サイト Bleeping Computer によると
3,100万人分のユーザデータの流出していて、本物であることも確認済みとのこと
流出したデータ
・メアド
・表示名
・パスワード変更時間
・Bcryptでハッシュ化されたパスワード など
Internet Archive hacked, data breach impacts 31 million users
https://www.bleepingcomputer.com/news/security/internet-archive-hacked-data-breach-impacts-31-million-users/
691名無しさん@お腹いっぱい。
2024/10/10(木) 07:48:20.47 情報漏洩との関連性は不明だが、BlackMetaを名乗るハカーがDDoS攻撃仕掛けてるらしい
692名無しさん@お腹いっぱい。
2024/10/10(木) 08:16:30.69 【時系列】
9日前:
何者かが流出データを情報流出確認サイト"Have I Been Pwned"の管理人に共有
3日前:
管理人は内容を精査しInternet Archiveに通知するも音沙汰なし
今朝:
サイト改竄 & 報道でお祭り騒ぎ
IT系ニュースサイトも続々と報道し始めてる
大変なことになったな
https://www.theverge.com/2024/10/9/24266419/internet-archive-ddos-attack-pop-up-message
https://www.pcmag.com/news/hacker-defaces-internet-archive-claims-it-suffered-a-breach
9日前:
何者かが流出データを情報流出確認サイト"Have I Been Pwned"の管理人に共有
3日前:
管理人は内容を精査しInternet Archiveに通知するも音沙汰なし
今朝:
サイト改竄 & 報道でお祭り騒ぎ
IT系ニュースサイトも続々と報道し始めてる
大変なことになったな
https://www.theverge.com/2024/10/9/24266419/internet-archive-ddos-attack-pop-up-message
https://www.pcmag.com/news/hacker-defaces-internet-archive-claims-it-suffered-a-breach
693名無しさん@お腹いっぱい。
2024/10/10(木) 11:34:54.15 「Wayback Machine」のInternet Archiveから3100万人のユーザーデータ漏えい
694名無しさん@お腹いっぱい。
2024/10/10(木) 12:22:15.66 つまらん
過去全データとバックアップ削除して復旧不可能にならんと祭りじゃないよ
過去全データとバックアップ削除して復旧不可能にならんと祭りじゃないよ
695名無しさん@お腹いっぱい。
2024/10/10(木) 12:35:35.47 IA設立者Brewster Kahle氏、情報流出・サプリチェーン攻撃によるサイト改竄・DDoS攻撃があったと発表
https://twitter.com/brewster_kahle/status/1844183111514603812
https://twitter.com/thejimwatkins
https://twitter.com/brewster_kahle/status/1844183111514603812
https://twitter.com/thejimwatkins
2024/10/10(木) 18:51:47.73
酷い連中だわ
2024/10/10(木) 19:04:34.53
ライブラリの方は元々メタデータからメールアドレスが取り出せる仕組みだったし、
パスワードだけでなくメアドも他所のアカウントとは分離したりとか
対策できる人はやってたでしょ
パスワードだけでなくメアドも他所のアカウントとは分離したりとか
対策できる人はやってたでしょ
2024/10/10(木) 20:37:26.16
今繋がらないのは落とされてるのか・・・
2024/10/10(木) 21:03:26.71
昼間は普通に繋がったんだけどね
700名無しさん@お腹いっぱい。
2024/10/10(木) 21:52:21.02 何か繋がらないなと思ったら、ハッキングされてたのか・・・
2024/10/10(木) 22:14:34.77
今日つながらないなぁと思ってここに来たらハックの情報を知って
慌ててIAのログインに使ってたメアドのパスを変えてきた
慌ててIAのログインに使ってたメアドのパスを変えてきた
2024/10/10(木) 23:53:48.70
>>699
2・3日前からつながったりつながらなかったり
2・3日前からつながったりつながらなかったり
2024/10/11(金) 03:12:43.70
知識不足でよくわからないんだが、Wayback Machineのユーザー情報漏洩って、
Wayback Machineにユーザー情報とかあったの?
URL貼って日付け選んで、削除前のHPに行くくらいしか使ったことないんだが・・・
削除前のHPでログインした情報とかが漏洩したって事?
Wayback Machineにユーザー情報とかあったの?
URL貼って日付け選んで、削除前のHPに行くくらいしか使ったことないんだが・・・
削除前のHPでログインした情報とかが漏洩したって事?
2024/10/11(金) 03:32:56.45
ハッキングされたって事はウイルス仕込まれた可能性もあるのか・・・?
2024/10/11(金) 03:37:09.23
ちょくちょく利用してたけど、ここがなくなったら困るんだが、復活するかな?
706名無しさん@お腹いっぱい。
2024/10/11(金) 04:19:13.11 誰がどんなサイトを保存したのか、バレるのか
707名無しさん@お腹いっぱい。
2024/10/11(金) 08:20:01.87708名無しさん@お腹いっぱい。
2024/10/11(金) 08:23:17.672024/10/11(金) 08:48:55.53
2024/10/11(金) 13:08:29.13
503 エラーページに Bluesky と Mastodon へのリンクを追加。


2024/10/11(金) 13:25:27.26
2024/10/11(金) 20:45:02.49
DDoS攻撃してる奴が飽きるか対策するかだけど改竄までされてるからもう無理かなあ・・・
2024/10/11(金) 21:22:57.85
アーカイブのデータは壊されていないとのこと
https://x.com/brewster_kahle/status/1844485102312751421
サイトを改竄してお漏らしさせる事案って本当に多いんだよね
一週間前のタリーズオンラインストアもそれでしょう
それともアーカイブ自体の破壊が目的だったのか
https://x.com/brewster_kahle/status/1844485102312751421
サイトを改竄してお漏らしさせる事案って本当に多いんだよね
一週間前のタリーズオンラインストアもそれでしょう
それともアーカイブ自体の破壊が目的だったのか
2024/10/11(金) 21:47:04.10
壊されたらハッカーも困りそう
2024/10/11(金) 22:00:12.22
ミソがついた形だが、アーカイブが改ざんされていないかどうかの信用評価はこれから
2024/10/11(金) 23:51:36.34
Internet Archive の場合、今までは非SSL端末や非SSLブラウザでも自由にPageアーカイブ保存したり開いたり出来たのが利点だったけど、今回の鯖ダウンを契機としてセキュリティ引き上げを口実に非SSLの締め出し強行されたら嫌だなぁ…。
《 【悲報】新浪人のUPLIFT、httpsがTLS1.0→TLS1.2になった為に一部の専ブラでログインできない事が判明 [487816701]
http://hayabusa9.5ch.net/test/read.cgi/news/1693635036/?v=pc 》
717名無しさん@お腹いっぱい。
2024/10/12(土) 12:43:56.83 archiveの代替サイトまとめて
2024/10/12(土) 13:05:54.64
なんだこの改行野郎
頭悪そう
頭悪そう
719440
2024/10/12(土) 17:46:40.53 >https://x.com/brewster_kahle/status/1844790609573277792
>Estimated Timeline: days, not weeks.
マダァ?(・∀・)っ/🍵⌒✨
復帰してくれないとarchive.orgを使う次のレスが打てん
5chでリンク張ると横に文字数が長くなるキライがあるけど、
こういう時にリンクにアドレス名が入ってると
元のアドレスが何か判るのは良い(archive.todayだと何のリンクか判らなくなる)
ユーザー登録ログイン機能って必要性あったのかな?
それと、
Twitter(𝕏), Instagram, Facebookなど(5chのレスも鯖によって執れない処があった記憶)
執れないと判明してるサイトを無駄に執らせる仕様も改良してほしい
archive.todayの方では執れたりするから
技術的に🉑能と想われるのでなんとかしてほしい
>Estimated Timeline: days, not weeks.
マダァ?(・∀・)っ/🍵⌒✨
復帰してくれないとarchive.orgを使う次のレスが打てん
5chでリンク張ると横に文字数が長くなるキライがあるけど、
こういう時にリンクにアドレス名が入ってると
元のアドレスが何か判るのは良い(archive.todayだと何のリンクか判らなくなる)
ユーザー登録ログイン機能って必要性あったのかな?
それと、
Twitter(𝕏), Instagram, Facebookなど(5chのレスも鯖によって執れない処があった記憶)
執れないと判明してるサイトを無駄に執らせる仕様も改良してほしい
archive.todayの方では執れたりするから
技術的に🉑能と想われるのでなんとかしてほしい
2024/10/12(土) 20:19:08.42
2024/10/12(土) 20:19:09.63
2024/10/12(土) 21:30:06.09
webページのキャプチャだけならログインは不要かもしれんけど
ファイルのアップロード機能もあるからな
まあweb割れの総本山のイメージしか無いけど。
ファイルのアップロード機能もあるからな
まあweb割れの総本山のイメージしか無いけど。
2024/10/12(土) 21:44:27.67
archive.todayのアーカイヴされたページの「シェア」を押すと長いリンクを見られる
https://archive.today/2024.10.12-122059/https://www.isitdownrightnow.com/web.archive.org.html
日時は下記のようにもできる
https://archive.today/20241012122059/https://www.isitdownrightnow.com/web.archive.org.html
https://archive.today/2024.10.12-122059/https://www.isitdownrightnow.com/web.archive.org.html
日時は下記のようにもできる
https://archive.today/20241012122059/https://www.isitdownrightnow.com/web.archive.org.html
2024/10/12(土) 22:28:32.21
専ブラでは問題無かったりするけど
URL の真ん中にスキーム名が残るのは避けたいことがあるのよね
まぁ : を %3a に置換すれば良いのだけど

URL の真ん中にスキーム名が残るのは避けたいことがあるのよね
まぁ : を %3a に置換すれば良いのだけど

2024/10/12(土) 22:58:38.09
have i been pwnedで調べたら見事にメルアドとパスワード抜かれてたわ
普段使ってるメルアドじゃなかったからまだマシかも
普段使ってるメルアドじゃなかったからまだマシかも
2024/10/12(土) 23:25:23.43
個々のスクリプト毎にランダム生成の捨てアドでアカウントを作ってたけど
取り敢えずパスワードは変えるかぁ・・・

取り敢えずパスワードは変えるかぁ・・・

2024/10/13(日) 00:09:51.53
流出したパスワードは平文じゃなくてハッシュだけどな
まぁ不安なら変えといた方がいい
まぁ不安なら変えといた方がいい
2024/10/13(日) 00:17:40.71
ようずんにこすたことはないね
2024/10/13(日) 02:09:18.44
しかしまぁいつ頃復旧すんだろうね?
どっかの国産動画サイトよろしく2ヶ月弱とか勘弁願いたいが
どっかの国産動画サイトよろしく2ヶ月弱とか勘弁願いたいが
2024/10/13(日) 02:51:36.76
これで閉鎖したらアキバ総研の呪いという事にする
2024/10/13(日) 04:56:01.20
732名無しさん@お腹いっぱい。
2024/10/13(日) 21:21:29.69 目的がわからん
大企業狙えよ
大企業狙えよ
733名無しさん@お腹いっぱい。
2024/10/13(日) 21:38:02.33 新興宗教も
2024/10/13(日) 22:52:09.85
これアーカイブするか→IA開く→そういや落ちてたわ・・・
ってのを繰り返してる
ってのを繰り返してる
2024/10/14(月) 13:06:39.78
とりあえずは閲覧限定だが仮復旧したか
全面復旧はいつになるのやら
全面復旧はいつになるのやら
2024/10/14(月) 18:08:14.91
見られるようになったね
とりあえずデータは破壊されていなかったようで一安心
とりあえずデータは破壊されていなかったようで一安心
2024/10/14(月) 21:28:28.88
アキバ総研アーカイブも無事動いてよかった。
セキュリテイ強化と言い出して仕様変わったら見れなくなってた
セキュリテイ強化と言い出して仕様変わったら見れなくなってた
2024/10/14(月) 21:49:23.21
まだ新規に取れるわけではないのか
2024/10/14(月) 22:04:12.53
サイト見ちゃって大丈夫かな?
なんか変なスクリプト埋め込まれてたら嫌なんだが
まあみるだけなら大丈夫か
なんか変なスクリプト埋め込まれてたら嫌なんだが
まあみるだけなら大丈夫か
2024/10/14(月) 22:50:21.89
>>738
取得のページに一応アクセスはできるが、残念ながら・・・
取得のページに一応アクセスはできるが、残念ながら・・・
2024/10/14(月) 23:28:55.23
ウェブアーカイブは仮復旧、こちらは何時になるかな
https://archive.org/details/software
https://archive.org/details/software
2024/10/15(火) 01:49:18.57
正直こっちのほうがKADOKAWAへの攻撃よりも個人的には衝撃を受けたわ
2024/10/15(火) 01:58:50.02
同じく
744名無しさん@お腹いっぱい。
2024/10/15(火) 02:25:44.94 テスト
745名無しさん@お腹いっぱい。
2024/10/15(火) 02:28:10.02 6/8にニコニコがハッキングされてさ
8/8ぐらいに復旧したんだけど
Switchで観るかスマホで観るしかなかった
それで最近になってWebCast使ってここの動画をまぁ…いろいろ観て楽しんでたわけよ
それで一通りそれらを見て落ち着いたあたりでこれだ
PS5も値上がりしてモンハン買う気起きなくなったし厄年すぎる
8/8ぐらいに復旧したんだけど
Switchで観るかスマホで観るしかなかった
それで最近になってWebCast使ってここの動画をまぁ…いろいろ観て楽しんでたわけよ
それで一通りそれらを見て落ち着いたあたりでこれだ
PS5も値上がりしてモンハン買う気起きなくなったし厄年すぎる
746名無しさん@お腹いっぱい。
2024/10/15(火) 02:29:55.41 WebCastでChromecastのキャスト伝ってiPhoneに変なもん送れるならやってみろって感じ
Google様とApple様に手を出すのが怖いチキン共だから
脆弱そうな角川やらここを狙うしかねえんだろ?
Google様とApple様に手を出すのが怖いチキン共だから
脆弱そうな角川やらここを狙うしかねえんだろ?
2024/10/15(火) 02:31:51.68
そういやニコニコは復旧後コメントの過去ログが取れなくなった。
復旧予定項目にも無いし、無かったことになりそう
それか過去ログはデータが本当に消えちゃったか。
復旧予定項目にも無いし、無かったことになりそう
それか過去ログはデータが本当に消えちゃったか。
748名無しさん@お腹いっぱい。
2024/10/15(火) 02:47:47.24 ニコる履歴で俺のコメントだって紐付けされてたぞ
2024/10/15(火) 04:30:02.59
無関係すぎて知らんがな・・・
2024/10/15(火) 21:24:44.10
過去の英語の記事をたくさん見るから困ってます。代替え手段はありますか?
2024/10/15(火) 22:31:47.67
これも時代の流れなのか


2024/10/16(水) 00:53:05.19
504 Gateway Time-out
こればっか
こればっか
2024/10/16(水) 16:38:37.34
まだSPNは復旧してないか
2024/10/16(水) 16:53:15.81
10日位にダウンしたからもう一週間位のアーカイブ全部吹っ飛んだか・・・悲しい
2024/10/16(水) 17:52:41.01
毎日なんかアーカイブしてるの…?
2024/10/16(水) 20:15:26.07
>>755
個人的には半日位でスレ落ちして原則ログが残らない某画像掲示板とかいつ消えるかもわからんSNSの元画像とかそんな所か
魚拓やarchive.isでいいじゃんって言われそうだが一件一件チマチマ登録すんのが面倒でタイパ悪いしwebarchiveに比べて色々制限があんのが…
個人的には半日位でスレ落ちして原則ログが残らない某画像掲示板とかいつ消えるかもわからんSNSの元画像とかそんな所か
魚拓やarchive.isでいいじゃんって言われそうだが一件一件チマチマ登録すんのが面倒でタイパ悪いしwebarchiveに比べて色々制限があんのが…
2024/10/16(水) 21:17:44.59
試しにCNNとか有名どころのurlで探してみると毎日アーカイブ取得されてるのが分かるな
古いアーカイブは探せるようにはなってるから
古いアーカイブは探せるようにはなってるから
2024/10/16(水) 22:09:13.71
2024/10/16(水) 22:20:35.28
2024/10/16(水) 22:38:06.08
waybackmachine閲覧できるようになったらしいけどアクセスして大丈夫かな?ハッカーになんか仕掛けられてたら怖いんだが
一応そこも確認したのかな?
誰か教えて
一応そこも確認したのかな?
誰か教えて
2024/10/17(木) 00:14:32.00
2024/10/17(木) 02:02:56.51
真面目な話期待したんだけど
2024/10/17(木) 05:02:11.07
三角木馬ならちょっとは笑えたのに
2024/10/17(木) 05:52:01.46
IAが潰された事によって他のアーカイブサイトにIA勢が湧いてきて糞重くなってんの怠い
2024/10/17(木) 05:58:45.99
パスを変えたいがログインのページどこ?
2024/10/17(木) 07:14:39.88
アーカイブサイトって
・IA
・archive today
・web魚拓
ここら辺しか知らないんだが
他のサイトってあるか?
情報一覧とか載ってるサイトとかあるのかな?
・IA
・archive today
・web魚拓
ここら辺しか知らないんだが
他のサイトってあるか?
情報一覧とか載ってるサイトとかあるのかな?
2024/10/17(木) 10:36:35.50
んで、結局今アクセスするのは安全なん?
2024/10/17(木) 11:01:39.09
https://x.com/waybackmachine/status/1846656653799895283
The Wayback Machine @waybackmachine
午前5:57 ・ 2024年10月17日
Wanted to share an update from Team @waybackmachine
The archives are safe & the Wayback Machine is up in read-only mode.
We hope to turn on more web crawling within a day to make sure our web collections remain whole.
Next up: Save Page Now.
Thank you for the support!
チーム@waybackmachineからの最新情報をお伝えします。
アーカイブは無事でWayback Machineは読み取り専用モードで稼動しています。
1日以内にさらにウェブのクロールを開始し、ウェブ・コレクションが
完全な状態で維持されるようにしたいと考えています。
次は、Save Page Now です。
応援ありがとうございました!
The Wayback Machine @waybackmachine
午前5:57 ・ 2024年10月17日
Wanted to share an update from Team @waybackmachine
The archives are safe & the Wayback Machine is up in read-only mode.
We hope to turn on more web crawling within a day to make sure our web collections remain whole.
Next up: Save Page Now.
Thank you for the support!
チーム@waybackmachineからの最新情報をお伝えします。
アーカイブは無事でWayback Machineは読み取り専用モードで稼動しています。
1日以内にさらにウェブのクロールを開始し、ウェブ・コレクションが
完全な状態で維持されるようにしたいと考えています。
次は、Save Page Now です。
応援ありがとうございました!
2024/10/17(木) 11:54:52.70
>>765
ログイン周りは全く動いてないね
パスワードどころか、メールアドレスごと早く替えたい
こういうサイトの捨てアドで作ったアカウントがあるから
アドレスさえ判っていれば誰でも乗っ取れちゃうw
https://www.txen.de/
ログイン周りは全く動いてないね
パスワードどころか、メールアドレスごと早く替えたい
こういうサイトの捨てアドで作ったアカウントがあるから
アドレスさえ判っていれば誰でも乗っ取れちゃうw
https://www.txen.de/
2024/10/17(木) 14:22:34.07
2024/10/17(木) 15:11:04.91
772名無しさん@お腹いっぱい。
2024/10/17(木) 16:16:23.922024/10/17(木) 16:54:36.40
IA以上に信頼できるアーカイブサイトって無いからなぁ
web魚拓は営利企業だから収益が悪化すれば消える可能性あるし
todayに至っては運営者がよく分からん
web魚拓は営利企業だから収益が悪化すれば消える可能性あるし
todayに至っては運営者がよく分からん
2024/10/17(木) 17:08:30.30
SAVEがしたいです…安西先生…
2024/10/17(木) 17:48:04.12
個人的に保存したいだけならossのアーカイブツールが最強だけど
不特定多数に公開、もしくはアーカイブを証明として使うなら選択肢は片手で数えられるくらいしか無いよな
不特定多数に公開、もしくはアーカイブを証明として使うなら選択肢は片手で数えられるくらいしか無いよな
776名無しさん@お腹いっぱい。
2024/10/17(木) 18:10:04.35 保存はスクショでとも思うが
博物館がないと厳しい
博物館がないと厳しい
777名無しさん@お腹いっぱい。
2024/10/17(木) 23:24:19.49778名無しさん@お腹いっぱい。
2024/10/18(金) 00:08:53.76 IAってエロ動画保存は駄目なの?
2024/10/18(金) 01:43:00.69
成人エロでしょ、これまたどうして
ナチュリスト系のサイトはドメインごと排除されてたりするな
見る側は児○として見てるからねぇ
ナチュリスト系のサイトはドメインごと排除されてたりするな
見る側は児○として見てるからねぇ
2024/10/18(金) 04:20:09.17
アクセスしたけど、アクセスしない方が良かった?
サイトにウイルス仕込まれてたら、サイトにアクセスしただけでアウト?
サイトにウイルス仕込まれてたら、サイトにアクセスしただけでアウト?
2024/10/18(金) 04:29:58.03
そんなこといちいち気にするくらいなら使うなよ
2024/10/18(金) 08:59:34.28
流石に復旧する前にチェックしてるはず
だから大丈夫じゃない?
てか今どき見ただけでウイルスかかるってあるんか?
だから大丈夫じゃない?
てか今どき見ただけでウイルスかかるってあるんか?
783名無しさん@お腹いっぱい。
2024/10/18(金) 13:03:34.03 >>766
アーカイブサイトの一覧はこの辺が参考になりそう
・Wikipediaで使われているウェブアーカイブ一覧
https://en.wikipedia.org/wiki/Wikipedia:List_of_web_archives_on_Wikipedia
・ウェブアーカイブの取り組み一覧
https://en.wikipedia.org/wiki/List_of_Web_archiving_initiatives
アーカイブサイトの一覧はこの辺が参考になりそう
・Wikipediaで使われているウェブアーカイブ一覧
https://en.wikipedia.org/wiki/Wikipedia:List_of_web_archives_on_Wikipedia
・ウェブアーカイブの取り組み一覧
https://en.wikipedia.org/wiki/List_of_Web_archiving_initiatives
2024/10/18(金) 19:05:17.11
進展あった
2024/10/18(金) 19:16:12.83
Wayback Machine, Archive-It and blog.archive.org resumed.
アカウント周りはまだか
アカウント周りはまだか

786719, 450
2024/10/18(金) 19:29:03.57 >>723
なるほど、これならarchive.Todayもリンクを遣い別けられる
>>783
archive.Orgは真ん中の日付を省略して最後に執ったものを表示させることが出来るのは知ってたけど、
・/web/0/ =Oldest
・/web/2/ =Newest
は知らなかった!
⚠︎Newestの方は最後がミスキャプチャーになるとミスキャプチャーを返すので使えない
e.g. 🆖https://web.archive.org/web/2/https://twitter.com/internetarchive/
archive.Orgの画像の直リンを使う事が多いのだけど
その場合の/web/**************if_/や/web/**************im_/のアドレスにも
・/web/0if_/
・/web/0im_/
でOldestが効く模様
e.g. 🇬https://web.archive.org/web/0im_/http://www.google.com/google.jpg
>>724
それは5chのUIを構築してる無能の不手際
ミラーの2ch(sc)の方ではそういう文字列もちゃんとリンクとして表記される
引用で5chの書き込みを使う時はscの方のリンクを使う様にしてる
e.g. 🔗https://toro.2ch.s%EF%BD%83/test/read.cgi/win/1642086530/352n
※scは名前欄のレス番がsc増加レス分だけズレる
https://twitter.com/thejimwatkins
なるほど、これならarchive.Todayもリンクを遣い別けられる
>>783
archive.Orgは真ん中の日付を省略して最後に執ったものを表示させることが出来るのは知ってたけど、
・/web/0/ =Oldest
・/web/2/ =Newest
は知らなかった!
⚠︎Newestの方は最後がミスキャプチャーになるとミスキャプチャーを返すので使えない
e.g. 🆖https://web.archive.org/web/2/https://twitter.com/internetarchive/
archive.Orgの画像の直リンを使う事が多いのだけど
その場合の/web/**************if_/や/web/**************im_/のアドレスにも
・/web/0if_/
・/web/0im_/
でOldestが効く模様
e.g. 🇬https://web.archive.org/web/0im_/http://www.google.com/google.jpg
>>724
それは5chのUIを構築してる無能の不手際
ミラーの2ch(sc)の方ではそういう文字列もちゃんとリンクとして表記される
引用で5chの書き込みを使う時はscの方のリンクを使う様にしてる
e.g. 🔗https://toro.2ch.s%EF%BD%83/test/read.cgi/win/1642086530/352n
※scは名前欄のレス番がsc増加レス分だけズレる
https://twitter.com/thejimwatkins
787786
2024/10/18(金) 20:02:29.57 ・/web/1/ ≠Oldest
e.g. 🔂https://web.archive.org/web/1im_/http://www.google.com/google.jpg
微妙に指定アドレスとは違う最古のものが表示されるけど
何だろうね1のパラメータは
e.g. 🔂https://web.archive.org/web/1im_/http://www.google.com/google.jpg
微妙に指定アドレスとは違う最古のものが表示されるけど
何だろうね1のパラメータは
788名無しさん@お腹いっぱい。
2024/10/18(金) 20:39:19.71 Stanford Web Archive Portal
2024/10/18(金) 22:50:23.33
レトロPCのカタログとか雑誌切り抜きとかマニュアルを見ようと思ったら…全滅。そのうち復活するのかな
790名無しさん@お腹いっぱい。
2024/10/19(土) 01:31:21.61 ニコニコもハッキングされてたけど
海外のサイトはセキュリティ万全のイメージあるけど
日本と大して変わらないのか
海外のサイトはセキュリティ万全のイメージあるけど
日本と大して変わらないのか
2024/10/19(土) 13:32:33.09
海外のサイトって主語がデカすぎるな
そもそも基盤ネットワークまで侵入されたニコニコとは比べ物にならん
そもそも基盤ネットワークまで侵入されたニコニコとは比べ物にならん
2024/10/19(土) 14:46:56.83
今のOS豊富な機能のバグ潰しきれてなくて穴だらけだから、
そこ悪用するだけだし
パスクラ(懐)
そこ悪用するだけだし
パスクラ(懐)
2024/10/19(土) 20:58:14.80
URL 中の日時数字列、現在の取り扱いはおそらくこう:
1. 14 桁に満たない場合、後ろを 9 で埋めて 14 桁にする
2. 月、日、時など、それぞれ有効範囲外の値を正規化する
(99 月 → 12 月、99 日 → 31 日、99 時 → 23 時、など)
3. 出来上がった日時数字列に最も近いタイムスタンプのアーカイブを提示する
例: web.archive.org/web/20100/... を指定した場合
2010 年 09 月 99 日 99 時 99 分 99 秒 → 2010 年 09 月 30 日 23 時 59 分 59 秒
この時刻に最も近いアーカイブが出てくるはず。
https://web.archive.org/web/20100/www.google.com/
1 が最古、って言うのは archive.org 上のどこかのドキュメントに書いてあったんだよね。
でもそれも 20 年近く前の記憶。

1. 14 桁に満たない場合、後ろを 9 で埋めて 14 桁にする
2. 月、日、時など、それぞれ有効範囲外の値を正規化する
(99 月 → 12 月、99 日 → 31 日、99 時 → 23 時、など)
3. 出来上がった日時数字列に最も近いタイムスタンプのアーカイブを提示する
例: web.archive.org/web/20100/... を指定した場合
2010 年 09 月 99 日 99 時 99 分 99 秒 → 2010 年 09 月 30 日 23 時 59 分 59 秒
この時刻に最も近いアーカイブが出てくるはず。
https://web.archive.org/web/20100/www.google.com/
1 が最古、って言うのは archive.org 上のどこかのドキュメントに書いてあったんだよね。
でもそれも 20 年近く前の記憶。

2024/10/20(日) 01:02:16.77
SPNが出来なさ過ぎてそろそろ禁断症状が出そう
2024/10/20(日) 03:49:52.83
2024/10/20(日) 11:56:44.81
先週から休みを取らずに対処してるってスタッフが言ってるし、近いうちに直ると信じたい
あとこれを機に色んなシステムをアップデートしてるから時間がかかってるらしい
あとこれを機に色んなシステムをアップデートしてるから時間がかかってるらしい
2024/10/20(日) 18:50:38.90
vectorのHPってurlが連番かと思ったら大昔は?そうじゃないページもあったんだな
https://hp.vector.co.jp/authors/tfuruka1/
https://hp.vector.co.jp/authors/yohko/
こっちは連番だからこっちからスクレイピングすれば補足出来るか…
https://www.vector.co.jp/vpack/browse/person/an001687.html
https://hp.vector.co.jp/authors/tfuruka1/
https://hp.vector.co.jp/authors/yohko/
こっちは連番だからこっちからスクレイピングすれば補足出来るか…
https://www.vector.co.jp/vpack/browse/person/an001687.html
2024/10/21(月) 09:03:03.74
vectorみたいなフリーのHPスペースってどうやってアーカイブすればいいんだろう?
トップページのURL一覧は機械的に作成出来るだろうけど、その中のサブページ? は地道にhtmlをパースするしか無い?
配置されてるhtmlの一覧が見れれば嬉しいけど、そんなのあるわけ無いし
トップページのURL一覧は機械的に作成出来るだろうけど、その中のサブページ? は地道にhtmlをパースするしか無い?
配置されてるhtmlの一覧が見れれば嬉しいけど、そんなのあるわけ無いし
799名無しさん@お腹いっぱい。
2024/10/21(月) 09:17:00.54 Internet Archive、盗まれたアクセストークンを悪用され再び被害
サポートメールのシステムに侵入して、そこから攻撃者がメールを送信してきたらしい
削除リクエストを含む80万件以上の問い合わせ情報が流出か
Internet Archive breached again through stolen access tokens
https://www.bleepingcomputer.com/news/security/internet-archive-breached-again-through-stolen-access-tokens/
サポートメールのシステムに侵入して、そこから攻撃者がメールを送信してきたらしい
削除リクエストを含む80万件以上の問い合わせ情報が流出か
Internet Archive breached again through stolen access tokens
https://www.bleepingcomputer.com/news/security/internet-archive-breached-again-through-stolen-access-tokens/
2024/10/21(月) 09:36:01.55
マジで復旧後にwaybackmachine使ったらやばい?ページ改ざんされてる可能性ない?
2024/10/21(月) 11:46:01.93
>>799
もうこれ作り直さなきゃダメなやつでは
もうこれ作り直さなきゃダメなやつでは
2024/10/21(月) 11:57:47.31
2024/10/21(月) 12:36:28.88
2024/10/21(月) 12:44:02.51
ゼロデイじゃなくても信頼出来るサイトのアーカイブが改竄されて怪しいサイトのリンクに書き換えられたりするのも充分にリスクだと思うけどね
サンドボックスを理解してる技術者ならともかく、一般人はサイトにアクセスするのと、
出て来るダイアログを何も考えずにok押して勝手にダウンロードされたexeを開く行為の区別なんか無いし
サンドボックスを理解してる技術者ならともかく、一般人はサイトにアクセスするのと、
出て来るダイアログを何も考えずにok押して勝手にダウンロードされたexeを開く行為の区別なんか無いし
2024/10/21(月) 14:09:55.42
アーカイブが改ざんされたって情報はどこにもないけどね
妄想を元に推論していくならアクセスするなとしか言えない、それが一番安全
ゼロクリックでPCを壊すマルウェアを仕込むのも「技術的には可能」なので
妄想を元に推論していくならアクセスするなとしか言えない、それが一番安全
ゼロクリックでPCを壊すマルウェアを仕込むのも「技術的には可能」なので
2024/10/21(月) 14:49:51.48
アクセスするなというか復旧後にすでに使ってるんだけどね。
もうちょい待てば良かったか
てかよく見たら新しくやられたというより9日にハッキングされた時にとられた奴を利用された感じみたいね
流石に復旧する時にサイトは念入りにチェックしてると思いたいが
もうちょい待てば良かったか
てかよく見たら新しくやられたというより9日にハッキングされた時にとられた奴を利用された感じみたいね
流石に復旧する時にサイトは念入りにチェックしてると思いたいが
2024/10/22(火) 03:42:51.84
808名無しさん@お腹いっぱい。
2024/10/22(火) 13:31:08.55 祝復活?ためらいがちに使ってみるか
2024/10/22(火) 16:04:42.23
ためらいがちとか生ぬるいこと言わず、
金輪際使うのをやめるって方法もあるんだぜw
金輪際使うのをやめるって方法もあるんだぜw
2024/10/22(火) 16:27:54.31
多少怖いよね。ハッキングされました→復旧しました。→昨日のニュースみたいなことが起きましただからね
おれはもう使っちゃたけど閲覧目的なら一旦様子見もありかもな
おれはもう使っちゃたけど閲覧目的なら一旦様子見もありかもな
2024/10/22(火) 17:34:16.64
多少怖いって何だよ
ちょっと怖かったり絶大に怖かったり変化するのかよ
ちょっと怖かったり絶大に怖かったり変化するのかよ
2024/10/22(火) 21:25:43.85
取る方がメインで見る方は元サイト消えた時だから今のIAに用無いわ
2024/10/23(水) 01:45:01.09
アレ?また見れなくなった?
これ書き込んでる現在、こっちの環境だとこのサイトにアクセスできませんって出るのだが…
これ書き込んでる現在、こっちの環境だとこのサイトにアクセスできませんって出るのだが…
2024/10/23(水) 02:00:50.64
こっちもアクセスできない
また何かあったのか、それとも完全復活の兆しか・・・
また何かあったのか、それとも完全復活の兆しか・・・
2024/10/23(水) 02:33:31.77
落ちたはりますなぁ
2024/10/23(水) 02:40:25.85
またハッキングされたんかな?
だとしたらもう復旧後に使ってるから勘弁なんだが
Xみても情報ない
だとしたらもう復旧後に使ってるから勘弁なんだが
Xみても情報ない
2024/10/23(水) 05:24:59.73
無反応だった archive.org は 503 ページを出すようになった
Wayback Machine の記述は削除、実際 web.archive.org は反応無し
22 日のイベントが終わったのか当該記述も削除

Wayback Machine の記述は削除、実際 web.archive.org は反応無し
22 日のイベントが終わったのか当該記述も削除

818名無しさん@お腹いっぱい。
2024/10/23(水) 09:15:33.64 IAハッキングしたのってニコニコと同じやつ?
819名無しさん@お腹いっぱい。
2024/10/23(水) 09:52:57.05 いいえ
2024/10/23(水) 11:34:18.89
なんたるちあ
2024/10/23(水) 12:28:30.64
waybackmachine復旧しても使わないほうがよさげ?
こうなるのわかってたら復旧後にアクセスしなかったよ。
検索閲覧程度なら大丈夫かな?
こうなるのわかってたら復旧後にアクセスしなかったよ。
検索閲覧程度なら大丈夫かな?
2024/10/23(水) 12:36:36.43
2024/10/23(水) 13:03:41.06
てかあれから進展あったの?
お知らせらしきもの探しても見つからんしハッキングされたときみたいにニュースになってない
お知らせらしきもの探しても見つからんしハッキングされたときみたいにニュースになってない
2024/10/23(水) 14:06:34.85
公式Twitterに書いてあるでしょ
2024/10/23(水) 19:06:47.70

2024/10/23(水) 21:46:53.57
一覧にアクセスしようとすると
Wayback Machine failed to return archive information.
Wayback Machine failed to return archive information.
827787
2024/10/23(水) 22:08:08.04828名無しさん@お腹いっぱい。
2024/10/23(水) 22:54:03.62 感染したんだろ
あーあ
あーあ
830名無しさん@お腹いっぱい。
2024/10/23(水) 23:39:01.00 あーこわいこわいw
2024/10/23(水) 23:41:35.83
早くSPNを摂取させてくれ、体が震えてきた
2024/10/24(木) 09:54:19.06
2024はサイバー犯罪元年だな
全世界で両手指を切り落とす刑罰の制定が必要だわ
全世界で両手指を切り落とす刑罰の制定が必要だわ
2024/10/24(木) 09:59:17.90
元年ではねぇだろwターニングポイントかすら怪しい
834名無しさん@お腹いっぱい。
2024/10/24(木) 10:19:46.01 archive.orgが生き返った模様
2024/10/24(木) 11:04:56.13
だとしても様子見するわ。
836名無しさん@お腹いっぱい。
2024/10/24(木) 16:51:48.76 保存系のサイトまとめろよ
2024/10/24(木) 19:57:10.68
503が出たので飛んできました
ハッキングの余波が収まらないのか
ハッキングの余波が収まらないのか
2024/10/24(木) 23:16:33.43
ネットわかんないけどWayback Machine使ってるそこの君
常日頃IA使ってるだろうここへの書き込みがズレてるから知識をつけて半年ROMるといいぞ
まずはURIやHTMLやJavaScriptとDNSやGETリクエストの仕組みを入門とか初心者で調べて
スマホでもJavaScript(Kiwiの開発者モード)やPython(Termux)動かせるから手探りで色々やってみるんだ
https://chatgpt.com にバンバン疑問を投げかけるのも心がけろ
ばかにしたり煽る人もいるけど専門性が高いコミュニティは少なからずこれが当たり前だから気に病まず頑張れ
常日頃IA使ってるだろうここへの書き込みがズレてるから知識をつけて半年ROMるといいぞ
まずはURIやHTMLやJavaScriptとDNSやGETリクエストの仕組みを入門とか初心者で調べて
スマホでもJavaScript(Kiwiの開発者モード)やPython(Termux)動かせるから手探りで色々やってみるんだ
https://chatgpt.com にバンバン疑問を投げかけるのも心がけろ
ばかにしたり煽る人もいるけど専門性が高いコミュニティは少なからずこれが当たり前だから気に病まず頑張れ
2024/10/25(金) 00:35:26.24
復旧まだ?
2024/10/25(金) 02:42:00.90
ずっと「Temporarily Offline」で取得不能
2024/10/25(金) 16:27:16.90
使えるようになったら使いたいんだけど有名人のXじゃなくて一般人のXの削除ポストって見れる?
自分の1年前のポストなんだけどXのアーカイブだと消えてて。
自分の1年前のポストなんだけどXのアーカイブだと消えてて。
2024/10/25(金) 16:39:34.89
IAでアーカイブされていれば見れる
2024/10/25(金) 16:58:47.12
それって事前に自分でやってなきゃだめってことです?
2024/10/25(金) 17:08:00.65
2024/10/25(金) 17:13:29.08
2024/10/25(金) 18:41:18.55
アメリカの図書館がTwitterの公開ツイートをクロールしてるって話があったけど
イーロン体制になっても維持されてるのか、
そのアーカイブはwebで公開されているのか
は知らん
イーロン体制になっても維持されてるのか、
そのアーカイブはwebで公開されているのか
は知らん
2024/10/25(金) 19:01:30.35
復旧マダァ?(・∀・ )っ/凵⌒☆チンチン
2024/10/25(金) 21:37:24.32
どっちみちイーロンになってからはまともにIAでは取れなくなってるし
2024/10/25(金) 22:22:03.75
恒久的なアーカイブ方法って何があるんだろうな
電子の海にデータを放出すれば消えないはずだったのに
電子の海にデータを放出すれば消えないはずだったのに
2024/10/25(金) 23:59:56.39
ネット上の情報のほうが恒久的に消滅する可能性が非常に高い
だなんて15~20年くらい前には思いもしなかったよな
だなんて15~20年くらい前には思いもしなかったよな
2024/10/26(土) 00:20:26.02
アーカイブ冗長的に整備・一般化>
レアデータの争奪>
生成偽書が大量に出現>
収拾不能に
レアデータの争奪>
生成偽書が大量に出現>
収拾不能に
2024/10/26(土) 00:36:36.01
2024/10/26(土) 09:23:53.66
15年前でも大好きだった個人サイトの小説やニコニコの動画やコメントがある日突然跡形もなく一瞬で消えてもう二度と見れなくて泣いた事何度もあったからネットの儚さは気づいてた
それ以来少しでも気に入ったものはすぐにローカル保存できればアーカイブもするようになった
ネット情報は10年以上残ってるのですらほとんど無いってだいぶ前の調査記事で見たし
ある事件について調べようとしてもどんなに探しても不気味なほどネットには何も残ってなくて分からないのだと
この時代の情報は実は後の時代から見たらほとんど残ってなくて空白の時代になるんじゃないかとも危惧されてたり
自分の昔ブックマークしてたサイトもほぼ全滅
昔の情報あさっても2ちゃんの過去ログしかない事ばかり
デジタル情報ほど残らない諸行無常を感じるものもない
それ以来少しでも気に入ったものはすぐにローカル保存できればアーカイブもするようになった
ネット情報は10年以上残ってるのですらほとんど無いってだいぶ前の調査記事で見たし
ある事件について調べようとしてもどんなに探しても不気味なほどネットには何も残ってなくて分からないのだと
この時代の情報は実は後の時代から見たらほとんど残ってなくて空白の時代になるんじゃないかとも危惧されてたり
自分の昔ブックマークしてたサイトもほぼ全滅
昔の情報あさっても2ちゃんの過去ログしかない事ばかり
デジタル情報ほど残らない諸行無常を感じるものもない
2024/10/26(土) 13:58:34.39
繋がらないよ
855安倍晋三
2024/10/26(土) 20:17:09.69 お漏らし告知メール届いた
2024/10/26(土) 21:00:04.15
登録してたん?
2024/10/26(土) 21:13:24.41
捨てアドでしか登録してないから知る由もなし
858名無しさん@お腹いっぱい。
2024/10/26(土) 21:45:21.88 IAって無料でメアド登録したら
ファイルアップ出来るようになるの?
ファイルアップ出来るようになるの?
2024/10/26(土) 21:50:58.45
こらぁいよいよ以てニコニココースかねぇ…
全面復旧すんのとこのスレが埋まんのはどっちが早いんだか…
全面復旧すんのとこのスレが埋まんのはどっちが早いんだか…
2024/10/26(土) 22:42:56.44
貴重な記録だよね
そのうちアメリカ政府が管理してくれたりしないだろうか…
そのうちアメリカ政府が管理してくれたりしないだろうか…
2024/10/26(土) 23:22:45.99
ケチな黄猿は黙ってろとか言われるぞ
2024/10/27(日) 04:44:46.53
ファイルを圧縮してまとめてダウンロードする機能が死んでてイライラするんだけど、いつ復旧するとか情報ある?
代わりにtorrentで落とそうとしてみたけど、なんかバグってるみたいでダウンロードはしてるんだけどずっと0%のままみたいな感じになるし……。これ、なんかトレント側の設定で回避できたりする?
代わりにtorrentで落とそうとしてみたけど、なんかバグってるみたいでダウンロードはしてるんだけどずっと0%のままみたいな感じになるし……。これ、なんかトレント側の設定で回避できたりする?
2024/10/27(日) 08:43:21.48
いくつか μTorrent で試してみたけど、トラッカーも配信サーバもどちらも動いてる模様。
あれって .torrent の形はしてるけど、中身は P2P ではなく
GetRight というダウンローダによる BitTorrent プロトコル拡張、
トラッカーがダウンロードを指示する先は IA のサーバの HTTP 80 番ポート。
そのまま GetRight を使うか、BitComet や μTorrent のような
同じ実装を取り込んだ torrent クライアントでなければ落ちてこないだろうね。
https://web.archive.org/web/2/help.archive.org/help/archive-bittorrents/
あれって .torrent の形はしてるけど、中身は P2P ではなく
GetRight というダウンローダによる BitTorrent プロトコル拡張、
トラッカーがダウンロードを指示する先は IA のサーバの HTTP 80 番ポート。
そのまま GetRight を使うか、BitComet や μTorrent のような
同じ実装を取り込んだ torrent クライアントでなければ落ちてこないだろうね。
https://web.archive.org/web/2/help.archive.org/help/archive-bittorrents/
2024/10/27(日) 12:18:09.49
2024/10/27(日) 14:15:19.74
>>863
ありがとう。Bittorrent使ってました! μTorrent使ったら問題なく落ちてきました。失礼しました。
ありがとう。Bittorrent使ってました! μTorrent使ったら問題なく落ちてきました。失礼しました。
2024/10/27(日) 22:19:59.92
選挙速報とかもアーカイブしたら
時間軸でどう変化したか見れるのかな
時間軸でどう変化したか見れるのかな
2024/10/27(日) 22:59:20.52
時間軸で見られたところで、あれって
(本来あってはいけないはずの) 個々の選挙区内の有権者数の差と、
開票作業に手当てできる人員の差でああいう流れが生じてるだけなんだよなー
(本来あってはいけないはずの) 個々の選挙区内の有権者数の差と、
開票作業に手当てできる人員の差でああいう流れが生じてるだけなんだよなー
2024/10/28(月) 15:14:39.99
選挙で思い出したけどアメリカ大統領選って来月の5日だよね
それまでにはSPNも復旧してるといいが
それまでにはSPNも復旧してるといいが
2024/10/28(月) 20:43:10.83
破産状態にあった取引先のIA魚拓がごっそり消されてた
グレーなうわさも聞いたが管財人が消す動機も無いし隠滅工作かなあ?
グレーなうわさも聞いたが管財人が消す動機も無いし隠滅工作かなあ?
2024/10/28(月) 23:08:20.17
"Wayback Machine failed to return archive information."
アーカイブをURLで検索しても、このメッセージがずっと出てくる
アーカイブをURLで検索しても、このメッセージがずっと出てくる
2024/10/28(月) 23:09:20.59
書き込んでから気づいたが>>826で既出だね、すまん
2024/10/28(月) 23:20:41.62
>>870-871
まだ直っていないという報告乙
まだ直っていないという報告乙
873名無しさん@お腹いっぱい。
2024/10/29(火) 02:29:22.83 Firefoxだとアーカイブされてるページに飛べないのだが
Chromiumのブラウザだと飛べるが
Firefoxだと404 Not Foundが出てくる
Chromiumのブラウザだと飛べるが
Firefoxだと404 Not Foundが出てくる
874名無しさん@お腹いっぱい。
2024/10/29(火) 05:49:39.90 >>850
「ネットなら残る」「紙なら残る」というのが間違い
ネットだろうが紙だろうが、残す努力をしたものは残るし、
逆に誰も残そうとしなかったものは残らないってだけのこと
(稀に偶然残ることもあるが)
「ネットなら残る」「紙なら残る」というのが間違い
ネットだろうが紙だろうが、残す努力をしたものは残るし、
逆に誰も残そうとしなかったものは残らないってだけのこと
(稀に偶然残ることもあるが)
875名無しさん@お腹いっぱい。
2024/10/29(火) 06:19:16.18 >>853
ここだって昔の全然見られなくなってるからな
専ブラ使う人多いからウェブアーカイブには残されにくいし
運営のゴタゴタと荒らしと利用人口減で存続が怪しくなってきてる5chの未来考えるとすごく不安
ここだって昔の全然見られなくなってるからな
専ブラ使う人多いからウェブアーカイブには残されにくいし
運営のゴタゴタと荒らしと利用人口減で存続が怪しくなってきてる5chの未来考えるとすごく不安
2024/10/29(火) 08:04:15.70
5ちゃん閉鎖するとなったら
5ちゃんのアーカイブごと消えたりして
削除申請出されてね…
5ちゃんのアーカイブごと消えたりして
削除申請出されてね…
877名無しさん@お腹いっぱい。
2024/10/29(火) 10:11:40.00 HTMLを気軽にDAT化する方法ってないの、逆じゃなくて
以前はあったと思うんだけど
以前はあったと思うんだけど
878名無しさん@お腹いっぱい。
2024/10/29(火) 10:53:39.10 dat化ってなんの意味があんの?
2024/10/29(火) 14:20:52.08
>>877
html2datみたいなツールがあるけど、半角スペースが連続した場合とかhtmlの段階で情報が抜け落ちてる場合があるから完全な変換は出来ない。
html2datみたいなツールがあるけど、半角スペースが連続した場合とかhtmlの段階で情報が抜け落ちてる場合があるから完全な変換は出来ない。
2024/10/30(水) 01:08:55.04
2024/10/30(水) 08:30:42.77
KADOKAWAグループサイト、4か月半ぶりに復旧
www.itmedia.co .jp/news/articles/2410/29/news186.html
ここの本格復旧(取得機能の復旧)は果たして・・・
ちなみに>>870の件は、数時間前は直ってなかったが、今見られた
www.itmedia.co .jp/news/articles/2410/29/news186.html
ここの本格復旧(取得機能の復旧)は果たして・・・
ちなみに>>870の件は、数時間前は直ってなかったが、今見られた
882827
2024/10/30(水) 23:11:52.50 此閒のDoodleの🌗http://archive.Today/2024.10.23-222516/https://www.google.co.jp/
Orgでコレクトされてればアーカイブからプレイ出来たのかな?
▶https://doodles.google/doodle/rise-of-the-half-moon/
からプレイできるのはEnglish ver.
今日の🫧http://archive.Today/2024.10.30-023911/https://www.google.co.jp/
も日本語版で後でもプレイしたかった
⬆
↕https://web.archive.Org/web/20190809075335/https://web.archive.org/
例のイースターエッグは2019/08/09から仕込まれていた模様
他のページにも在るのか??w
⬅https://web.archive.Org/web/20170421230602/https://web.archive.org/
2017/04/21からのはスライドの最後が置いてけぼりになる仕様
➡www.nhk.or.jp/ohayou/digest/2018/10/1018.html
のアドレスに置いてけぼりの画が在った記憶
だがアーカイブし忘れて又かくの如し。
Orgでコレクトされてればアーカイブからプレイ出来たのかな?
▶https://doodles.google/doodle/rise-of-the-half-moon/
からプレイできるのはEnglish ver.
今日の🫧http://archive.Today/2024.10.30-023911/https://www.google.co.jp/
も日本語版で後でもプレイしたかった
⬆
↕https://web.archive.Org/web/20190809075335/https://web.archive.org/
例のイースターエッグは2019/08/09から仕込まれていた模様
他のページにも在るのか??w
⬅https://web.archive.Org/web/20170421230602/https://web.archive.org/
2017/04/21からのはスライドの最後が置いてけぼりになる仕様
➡www.nhk.or.jp/ohayou/digest/2018/10/1018.html
のアドレスに置いてけぼりの画が在った記憶
だがアーカイブし忘れて又かくの如し。
2024/10/31(木) 00:00:31.06
2024/10/31(木) 14:43:27.67
セキュリティチェックのため機能は一時停止する事もあると前から説明されているのだが
誰も公式発表を見ていないのである
誰も公式発表を見ていないのである
2024/11/01(金) 18:42:48.07
2024/11/02(土) 05:31:41.39
アカウントでログインできるようになったけど
Account settings のページは白紙のまま
Account settings のページは白紙のまま
887名無しさん@お腹いっぱい。
2024/11/02(土) 23:08:26.13 なんかsaveだけ出来ないがサイバー攻撃でも受けてるんか?
2024/11/02(土) 23:21:13.96
/save/ 以外にも色々と出来てない
先月初旬のサイバー攻撃からの復旧作業中
先月初旬のサイバー攻撃からの復旧作業中
889名無しさん@お腹いっぱい。
2024/11/02(土) 23:22:15.69 ハードディスク不足
2024/11/04(月) 13:41:27.18
>>885
近日には動きがあるようなことがいわれてるが、果たして・・・
>-Save Page Now coming soon
blog.archive .org/2024/10/28/internet-archive-services-update/
近日には動きがあるようなことがいわれてるが、果たして・・・
>-Save Page Now coming soon
blog.archive .org/2024/10/28/internet-archive-services-update/
2024/11/04(月) 13:47:33.40
大統領選までにSPN普及は厳しいか・・・
892882
2024/11/04(月) 13:50:35.04 >>890
煩わしいからリンクは直リンにして
🔜https://x.com/internetarchive/status/1851021456928305647
優先するのはログイン機能の方なのか?
流出って騒がれる割に、フィッシングメールが来る以外に実害に遭ってる奴いるのかな?
登錄者で何か被害に遭ったらこのスレにレポ4649
>>884
💳カードのセキュリティコードって
保存してるサイトばかりだヨネ
>>889
📊https://web.archive.org/web/*/https://web.archive.org/
同一のスナップが毎日毎日何百回も執られてるけど
完全同一の重複分をリダイレクト処理してなかったら容量が幾ら有っても足らん詰みゲー
>>882↕を査べる時も差分が判らなくて手閒だった
🆙
読み出し速度が遅いので速度の向上も期待したい
のと
archive.Todayには在るショートリンク機能をオプションでほしい
Orgのアドレスでは5chのメアド欄にリンクを仕込めんw
𝕏
archive.Todayは現在、Twitter(𝕏)は執れてるみたいだけど
画像直リンのpbs.twimg.com/media/*
が⥁Loadingから進まずに執れなくなってる
※Twitter(𝕏)の画像直リンアドレスは🔒 ⇄ 🔓でアドレスが変わる
煩わしいからリンクは直リンにして
🔜https://x.com/internetarchive/status/1851021456928305647
優先するのはログイン機能の方なのか?
流出って騒がれる割に、フィッシングメールが来る以外に実害に遭ってる奴いるのかな?
登錄者で何か被害に遭ったらこのスレにレポ4649
>>884
💳カードのセキュリティコードって
保存してるサイトばかりだヨネ
>>889
📊https://web.archive.org/web/*/https://web.archive.org/
同一のスナップが毎日毎日何百回も執られてるけど
完全同一の重複分をリダイレクト処理してなかったら容量が幾ら有っても足らん詰みゲー
>>882↕を査べる時も差分が判らなくて手閒だった
🆙
読み出し速度が遅いので速度の向上も期待したい
のと
archive.Todayには在るショートリンク機能をオプションでほしい
Orgのアドレスでは5chのメアド欄にリンクを仕込めんw
𝕏
archive.Todayは現在、Twitter(𝕏)は執れてるみたいだけど
画像直リンのpbs.twimg.com/media/*
が⥁Loadingから進まずに執れなくなってる
※Twitter(𝕏)の画像直リンアドレスは🔒 ⇄ 🔓でアドレスが変わる
2024/11/04(月) 14:06:02.68
済まない、気持ちはわからないではないが、ちと前に直リンだか先頭だけ省略で書いたら規制に引っかかってさ(100%断定できるわけではないが)・・・
894892
2024/11/04(月) 14:25:09.22 >>893
あーなるほど。
今規制は敷かれてない模様
ディープリンク張りまくってる私がソースw
ドメインの . の閒にスペース入れてるでしょ
それだと
・半角スペースだと入ってる場所がフォントによってはパッと見判り難いのと
・右クリックから検索に掛けた時に該当アドレス(記事)が引っ掛からなくて
🖲から手を離して空白を消す作業が入って二度手閒になる
あーなるほど。
今規制は敷かれてない模様
ディープリンク張りまくってる私がソースw
ドメインの . の閒にスペース入れてるでしょ
それだと
・半角スペースだと入ってる場所がフォントによってはパッと見判り難いのと
・右クリックから検索に掛けた時に該当アドレス(記事)が引っ掛からなくて
🖲から手を離して空白を消す作業が入って二度手閒になる
895894
2024/11/04(月) 14:27:07.56 Save Page Now!
896895
2024/11/04(月) 17:21:31.34 [ Save Page ]ボタンは押せる様になったけど
503 Service Unavailable
で執れないな
⛓💥
🌗https://web.archive.org/web/20241104034557/https://doodles.google/doodle/rise-of-the-half-moon/
❔https://web.archive.org/web/20220524034952/https://image.itmedia.co.jp/l/im/news/articles/2107/30/l_koya_ibmfont5.jpg
以前からこの様に、サイトの一部の画像が表示されないパターンがあるのだけど、
・読み出しエラーで時間を置いて後からアクセスすると画像が表示されるパターン
・取得ミスで画像が撮られてなくて表示される事は無いパターン
2パターンがあって紛らわしい
503 Service Unavailable
で執れないな
⛓💥
🌗https://web.archive.org/web/20241104034557/https://doodles.google/doodle/rise-of-the-half-moon/
❔https://web.archive.org/web/20220524034952/https://image.itmedia.co.jp/l/im/news/articles/2107/30/l_koya_ibmfont5.jpg
以前からこの様に、サイトの一部の画像が表示されないパターンがあるのだけど、
・読み出しエラーで時間を置いて後からアクセスすると画像が表示されるパターン
・取得ミスで画像が撮られてなくて表示される事は無いパターン
2パターンがあって紛らわしい
2024/11/04(月) 20:15:15.77
ログインしてクッキー喰ってあると登録ユーザ向けオプションは提示されるけど、
いざリクエストを発行してもクッキーが無視されてるな。
Outlinks は拾えと言っても拾ってくれてないし、
一分間のリクエスト数上限 3 件とかいう縛りプレイ、話にならん。

いざリクエストを発行してもクッキーが無視されてるな。
Outlinks は拾えと言っても拾ってくれてないし、
一分間のリクエスト数上限 3 件とかいう縛りプレイ、話にならん。

2024/11/05(火) 02:21:49.40
動作は遅いし不安定だけどSPN動いてるっぽいな
2024/11/05(火) 06:23:22.25
ログインしてるのにこれは無いよ


2024/11/05(火) 06:57:11.65
割れダウンロードしすぎなんだよ
2024/11/05(火) 07:24:36.99
2024/11/05(火) 08:32:52.76
Save Page Now による保存が心なしか速くなっているような気がするのは気のせい?
2024/11/05(火) 09:07:37.93
恐らくリクエストの総数が減ってるからじゃないかなぁ。
クッキーも S3 API Key もユーザ認証は機能してないらしく、
https://web.archive.org/save/ で URL を入力する分には非ログインとして動作するけど
JSON を使う方は 401 Unauthorized となって何もできない状態。
クッキーも S3 API Key もユーザ認証は機能してないらしく、
https://web.archive.org/save/ で URL を入力する分には非ログインとして動作するけど
JSON を使う方は 401 Unauthorized となって何もできない状態。
2024/11/05(火) 10:05:57.64
>>903
認証に失敗するので「再開にあたって今までの key を無効に
したのかな?」と思って Get Your S3-Like API Keys ページに
行ってみると secret key が変更されていました。
書き換えて認証に成功しました。
認証に失敗するので「再開にあたって今までの key を無効に
したのかな?」と思って Get Your S3-Like API Keys ページに
行ってみると secret key が変更されていました。
書き換えて認証に成功しました。
2024/11/05(火) 16:42:54.21
>>897>>899
1分間に3件まで、1日に200件までは復旧まもないゆえの肩慣らしなのか、それともまさか今後はそれがデフォルトなのか・・・
「Job failed.」が頻繁に出るときは特にきつい
むろん使えないほぼ1か月間よりは増しだが・・・
1分間に3件まで、1日に200件までは復旧まもないゆえの肩慣らしなのか、それともまさか今後はそれがデフォルトなのか・・・
「Job failed.」が頻繁に出るときは特にきつい
むろん使えないほぼ1か月間よりは増しだが・・・
2024/11/05(火) 17:07:50.76
復帰してすぐに元通りになるわけないじゃろ
2024/11/05(火) 17:09:57.35
マンガ図書館閉鎖!
閉鎖ばっかりだ
閉鎖ばっかりだ
909名無しさん@お腹いっぱい。
2024/11/05(火) 18:04:49.52 IAみたいに規模のでかいミラーサイト他にないの?
910896
2024/11/05(火) 22:59:04.63 🔙https://x.com/internetarchive/status/1853545508121567287
(発表が)後手後手な広報w
>Web pages archived since October 9 will start being added to waybackmachine.
November 4じゃないのはどういう意味?
🗓https://web.archive.org/web/20240000000000*/https://www.google.com/
空白期間は 2024/10/10 ~ 11/4
だけど2日に執られてるの在るな
>>896の❔
画像が表示されてなかったんだけど
昨日 /20241104065933/ が執られた後に表示される様になって、
2022年の /20220524034952/ に表示されてる画像は
2024年の📁https://web.archive.org/web/20241104091531im_/https://image.itmedia.co.jp/news/articles/2107/30/l_koya_ibmfont5.jpg
となってる。(※右クリックメニューの「画像を新しいタブで開く」から画像だけを表示できる)
これって
・取得ミスで画像が撮られてなくて表示される事は無いパターン
の過去スナップは、
同一アドレスの当時とは違う未来画像がオーパーツされてしまう仕様では?
𝕏/🖼
archive.TodayのTwitter(𝕏)画像直リンアーカイブ不可は、
画像直リンアドレス🔗「pbs.twimg.com/media/~」を𝕏内でポストして
そのリンクを右クリックから[リンクをコピー]したTwitter(𝕏)のショートリンクアドレス🔗「𝑡.𝑐𝑜/~」
で保存を懸けるとリダイレクトしてアーカイブする事がreached for the moon
📫
5chのメアド欄リンクは専ブラからしか見れない模様
2ch(sc)の方ではメアド欄リンクが再現されない仕様だった
(発表が)後手後手な広報w
>Web pages archived since October 9 will start being added to waybackmachine.
November 4じゃないのはどういう意味?
🗓https://web.archive.org/web/20240000000000*/https://www.google.com/
空白期間は 2024/10/10 ~ 11/4
だけど2日に執られてるの在るな
>>896の❔
画像が表示されてなかったんだけど
昨日 /20241104065933/ が執られた後に表示される様になって、
2022年の /20220524034952/ に表示されてる画像は
2024年の📁https://web.archive.org/web/20241104091531im_/https://image.itmedia.co.jp/news/articles/2107/30/l_koya_ibmfont5.jpg
となってる。(※右クリックメニューの「画像を新しいタブで開く」から画像だけを表示できる)
これって
・取得ミスで画像が撮られてなくて表示される事は無いパターン
の過去スナップは、
同一アドレスの当時とは違う未来画像がオーパーツされてしまう仕様では?
𝕏/🖼
archive.TodayのTwitter(𝕏)画像直リンアーカイブ不可は、
画像直リンアドレス🔗「pbs.twimg.com/media/~」を𝕏内でポストして
そのリンクを右クリックから[リンクをコピー]したTwitter(𝕏)のショートリンクアドレス🔗「𝑡.𝑐𝑜/~」
で保存を懸けるとリダイレクトしてアーカイブする事がreached for the moon
📫
5chのメアド欄リンクは専ブラからしか見れない模様
2ch(sc)の方ではメアド欄リンクが再現されない仕様だった
2024/11/06(水) 13:33:39.17
ログインできてアカ削除しようとしたら読み込みが終わらずメアドだけでも変更したら変更を受け付けなかったよ
2024/11/06(水) 19:26:28.47
2024/11/06(水) 19:39:19.37
>>909
ttps://warp.ndl.go.jp/contents/reccommend/world_wa/index.html
閲覧だけで良かったらいくつかあるようだが、取得までできるのはarchive.todayかウェブ魚拓ぐらいしかないかと
ただ、後者はIAより厳しい1日60件まで
前者が1日何件までなのかは特に見あたらないが、少なくとも後者よりはゆるいか(最近60件どころではないレベルを取得したことだし)
ttps://warp.ndl.go.jp/contents/reccommend/world_wa/index.html
閲覧だけで良かったらいくつかあるようだが、取得までできるのはarchive.todayかウェブ魚拓ぐらいしかないかと
ただ、後者はIAより厳しい1日60件まで
前者が1日何件までなのかは特に見あたらないが、少なくとも後者よりはゆるいか(最近60件どころではないレベルを取得したことだし)
2024/11/06(水) 21:37:27.46
・大規模アーカイブ
・閲覧・保存が可能
・運営元が明確
の3つを満たしてるのはIAくらいしか無いだろうね
・閲覧・保存が可能
・運営元が明確
の3つを満たしてるのはIAくらいしか無いだろうね
2024/11/06(水) 22:36:43.63
archive.todayは同じドメインのURLを17000以上アーカイブするとNginxに飛ばされる
2024/11/07(木) 00:11:47.84
SPN復旧の件の記事
ttps://www.itmedia.co.jp/news/articles/2411/06/news168.html
あとはログイン絡みの問題か
ttps://www.itmedia.co.jp/news/articles/2411/06/news168.html
あとはログイン絡みの問題か
2024/11/07(木) 04:19:17.26
ログインからアカウント設定に入りパスワードの変更はできるようになったけど
メールアドレス変更がまだできないね。
新アドレスを入力して、認証 URL の記載されたメールが届く所までは良いけど
その URL を開いてもエラーとなって機能していない。
アカウント削除と表示名変更は試してないので判らない。
(一度使用した表示名は「使用済み」となって、元の所有者ですら戻せないシステムだったはず・・・)
メールアドレス変更がまだできないね。
新アドレスを入力して、認証 URL の記載されたメールが届く所までは良いけど
その URL を開いてもエラーとなって機能していない。
アカウント削除と表示名変更は試してないので判らない。
(一度使用した表示名は「使用済み」となって、元の所有者ですら戻せないシステムだったはず・・・)
918910
2024/11/07(木) 08:39:20.97 4日の再開後に執れてたアーカイブ、
再アクセスすると
>𝐇𝐫𝐦.
>The Wayback Machine has not archived that URL.
>Click here to search for all archived pages under ~
となってて表示されなくなってるarchivedが存在する模様
今⛓https://mevius.5ch.net/test/read.cgi/win/1642086530/879n
の2番目の🔗がその状態 (⬆>>786の /web/0if_/ を活用)
🌌のno+eのは
>a snapshot was captured. visit page: 🌌https://web.archive.org/web/20241106035458/https://note.com/onopko/n/n37d8740b2f84
>there was a delay in registering this snapshot with the wayback machine.
>you may be redirected to a previous version right now.
>this snapshot will be available later.
からずっと𝐇𝐫𝐦.で一度も表示されない
>>896の❔は、
ウェブ開発ツールから視れる画像のURLが✅https://web.archive.org/web/20220524034952im_/https://image.itmedia.co.jp/news/articles/2107/30/l_koya_ibmfont5.jpg
となってるけど
存在してなくてリダイレクトで>>910📁になってる模様
復旧の調整でのthis snapshot will be available later.じゃなかったら
Orgはシステム的にTodayよりぁゃιぃ
🆜https://archive.Today/9VIeR/image
ロングリンクがほしいTodayの足元がおるすなスクリーンショット機能
>>917
Sign upで使ってたらどんなメリットが或ったのかkwsk
再アクセスすると
>𝐇𝐫𝐦.
>The Wayback Machine has not archived that URL.
>Click here to search for all archived pages under ~
となってて表示されなくなってるarchivedが存在する模様
今⛓https://mevius.5ch.net/test/read.cgi/win/1642086530/879n
の2番目の🔗がその状態 (⬆>>786の /web/0if_/ を活用)
🌌のno+eのは
>a snapshot was captured. visit page: 🌌https://web.archive.org/web/20241106035458/https://note.com/onopko/n/n37d8740b2f84
>there was a delay in registering this snapshot with the wayback machine.
>you may be redirected to a previous version right now.
>this snapshot will be available later.
からずっと𝐇𝐫𝐦.で一度も表示されない
>>896の❔は、
ウェブ開発ツールから視れる画像のURLが✅https://web.archive.org/web/20220524034952im_/https://image.itmedia.co.jp/news/articles/2107/30/l_koya_ibmfont5.jpg
となってるけど
存在してなくてリダイレクトで>>910📁になってる模様
復旧の調整でのthis snapshot will be available later.じゃなかったら
Orgはシステム的にTodayよりぁゃιぃ
🆜https://archive.Today/9VIeR/image
ロングリンクがほしいTodayの足元がおるすなスクリーンショット機能
>>917
Sign upで使ってたらどんなメリットが或ったのかkwsk
919名無しさん@お腹いっぱい。
2024/11/07(木) 09:28:23.84 糖質はスルー推奨
920名無しさん@お腹いっぱい。
2024/11/07(木) 10:41:27.70 IAでアカウント作るメリットって何?
2024/11/07(木) 19:59:38.48
1分・1日に取得できる件数が違う
ただ、今のところ>>897>>899のとおりだが
ただ、今のところ>>897>>899のとおりだが
922名無しさん@お腹いっぱい。
2024/11/07(木) 20:02:13.90 糖質はスルー推奨
923名無しさん@お腹いっぱい。
2024/11/07(木) 21:11:07.17 アーカイブチームが図書館zのプロジェクト開始してるっぽいな
というかveohも閉鎖するんだなアーカイブチームのwikiで気づいた
というかveohも閉鎖するんだなアーカイブチームのwikiで気づいた
924名無しさん@お腹いっぱい。
2024/11/07(木) 22:37:18.63 IAってマンガ図書館Zみたいな電子コミックサイトの画像ちゃんと保存されるのかね
925名無しさん@お腹いっぱい。
2024/11/07(木) 23:40:43.13926918
2024/11/08(金) 03:52:00.972024/11/08(金) 07:08:19.60
絵文字は読みづらい
情報は嬉しいんだが普通に書いてくれ…
情報は嬉しいんだが普通に書いてくれ…
928名無しさん@お腹いっぱい。
2024/11/08(金) 07:30:33.48 糖質はスルー推奨
2024/11/08(金) 08:59:12.05
HTML フォームからアーカイブを採る際の縛りプレイ状態、このままでは埒が明かないので
HTTP ヘッダを操作するブラウザアドオンで Authorization ヘッダを挿入することにした。
Outlinks もちゃんと拾ってくれる。
https://web.archive.org/save/status/user もエラー無く保存件数等が確認できる。
https://web.archive.org/save/ のページ自体はクッキーしか見ていないので、
この入力フォームを使う場合はクッキーも喰っておく必要あり。

HTTP ヘッダを操作するブラウザアドオンで Authorization ヘッダを挿入することにした。
Outlinks もちゃんと拾ってくれる。
https://web.archive.org/save/status/user もエラー無く保存件数等が確認できる。
https://web.archive.org/save/ のページ自体はクッキーしか見ていないので、
この入力フォームを使う場合はクッキーも喰っておく必要あり。

930926
2024/11/08(金) 10:08:42.66 >>926🔗🔵𝐇𝐫𝐦.の件は、
本日早朝に復旧された模様
こういう細かいトラブル情報もTwitter(𝕏)で発信してくれヨナ
無駄ァに二つスナップを執ってしまった
『https://web.archive.org/web/20241107192258/http://hobby-room-pearl.%73akura.ne.jp/jump/daiamon/74-07-jojo2-3.jpg』
>>910❔📁オーパーツ化問題はそのまま
画像部がミスキャプチャで読み出せない大過去のアーカイブは多い
>>927
普通=オールドタイプ
なので無理
絵文字は
・引用用のタグ
・リマインダー(リンク先に何が在ったかの要約)
で用いてる
使わなかったら更に説明文が入って無様ね
読んでもらう為にレスを書(置)いてるのではないので
無理に読まなくても大丈夫だ、問題ない
絵文字は元Twitter社員のtwemojiがエモいので
🔀https://github.com/13rac1/twemoji-color-font
で置き替えておいた方がベネかもね
本日早朝に復旧された模様
こういう細かいトラブル情報もTwitter(𝕏)で発信してくれヨナ
無駄ァに二つスナップを執ってしまった
『https://web.archive.org/web/20241107192258/http://hobby-room-pearl.%73akura.ne.jp/jump/daiamon/74-07-jojo2-3.jpg』
>>910❔📁オーパーツ化問題はそのまま
画像部がミスキャプチャで読み出せない大過去のアーカイブは多い
>>927
普通=オールドタイプ
なので無理
絵文字は
・引用用のタグ
・リマインダー(リンク先に何が在ったかの要約)
で用いてる
使わなかったら更に説明文が入って無様ね
読んでもらう為にレスを書(置)いてるのではないので
無理に読まなくても大丈夫だ、問題ない
絵文字は元Twitter社員のtwemojiがエモいので
🔀https://github.com/13rac1/twemoji-color-font
で置き替えておいた方がベネかもね
931名無しさん@お腹いっぱい。
2024/11/08(金) 10:27:50.08 糖質はスルー推奨
2024/11/08(金) 10:41:54.61
2024/11/08(金) 17:46:02.81
所でarchive.orgのコレクションの新規アップロードってまだ出来ない感じ?
特に上げるもん無いけど物の試しにアップロードページへ行ったらこんな画面になるんだが…
https://archive.is/kOZWG/f002d291c83ae0be7211a02f27dede9a81e685dd.webp
特に上げるもん無いけど物の試しにアップロードページへ行ったらこんな画面になるんだが…
https://archive.is/kOZWG/f002d291c83ae0be7211a02f27dede9a81e685dd.webp
2024/11/08(金) 18:17:11.19
2024/11/08(金) 19:45:07.07
>>933
https://archive.org/about/403.html ですね。
>>917 のメアド変更の認証 URL も同じリダイレクト、
まだ復旧していない機能を使おうとするとそこに飛ばされるのだと思います。
>>932
アーカイブリクエスト時のユーザ認証が完全に死んでるかと思っていたのですが、
>>904 さんに API key による認証が機能していることを教えていただいたので
(パスワードが変更され認証失敗していただけだった)
ブラウザからもそれを使うようにしてみた次第です。
ここで API key の送信に使っているのが Authorization ヘッダ、
Save Page Now 2 Public API Docs (>>3) の Capture request の項に説明があります。

https://archive.org/about/403.html ですね。
>>917 のメアド変更の認証 URL も同じリダイレクト、
まだ復旧していない機能を使おうとするとそこに飛ばされるのだと思います。
>>932
アーカイブリクエスト時のユーザ認証が完全に死んでるかと思っていたのですが、
>>904 さんに API key による認証が機能していることを教えていただいたので
(パスワードが変更され認証失敗していただけだった)
ブラウザからもそれを使うようにしてみた次第です。
ここで API key の送信に使っているのが Authorization ヘッダ、
Save Page Now 2 Public API Docs (>>3) の Capture request の項に説明があります。

2024/11/08(金) 20:48:09.43
米国インターネットアーカイブの目指すこと――その理念、著作権という現実、AIとの関係
https://internet.watch.impress.co.jp/docs/news/1491372.html
https://internet.watch.impress.co.jp/docs/news/1491372.html
2024/11/08(金) 21:28:04.88
へぇ
2024/11/09(土) 02:00:30.89
ニコニコ静画を取ろうとしたらhttps://www.nicovideo.jp/region_restrictionにリダイレクトされてしまった
エロ系以外でも地域制限かかるのかよ・・・
エロ系以外でも地域制限かかるのかよ・・・
939930
2024/11/09(土) 10:01:24.76 ☑https://web.archive.org/web/20240801142256/http://web.archive.org/screenshot/https://webapps.stackexchange.com/
☑Save screenshot機能ってのは☝らしい
現在、そのスクショのアーカイブアドレス: 🔲https://web.archive.org/web/20240801142248/https://webapps.stackexchange.com/
はアーカイブではない元のURLにリダイレクトされてしまう仕様になってる然様
こういう時の為に使うのか?
・スクリーンショット ⇄ アーカイブの切り替えがTodayの様に出来ないのと、
・Orgのスクリーンショットは足元は居留すけど画質がjpgで劣化しててリテラが低い
Todayは無劣化のpng(>>918🆜)
>>933に使われてるGoogleの新規格のWebPは
圧縮率がpngよりも高いけど、
可逆(VP8L)と不可逆(VP8)で拡張子を別けて定義できないGoogleは理念が低い
SEOにページ表示速度を入れてるが、
速さよりも質
速度は後から改良が見込めるけど質は上げ治さない限り不良(WebPには上限も在るらしい)
♊
2ch(sc)のアーカイブがOrg, Today共に執れなくなってる
2ch(sc)は1000落ち後のdat化をミスって
>[エラー]
>datが存在しません。
になるスレが在ったから、アーカイブを執れないと🜄物
この近頃多発な執れないドメイン問題、
正体不明のToday: 🪆https://gigazine.net/news/20240326-archive-today/
には、どんな手を遣ってでも執れる様に期待w
>>934🙈→>>829
🪬https://mevius.5ch.net/test/read.cgi/hard/1717147167/1000n
𝐇𝐔𝐌!→𝐇𝐫𝐦.でバイツァダストが关ってるとか本来は生涯を通して知らせる事は無い
☑Save screenshot機能ってのは☝らしい
現在、そのスクショのアーカイブアドレス: 🔲https://web.archive.org/web/20240801142248/https://webapps.stackexchange.com/
はアーカイブではない元のURLにリダイレクトされてしまう仕様になってる然様
こういう時の為に使うのか?
・スクリーンショット ⇄ アーカイブの切り替えがTodayの様に出来ないのと、
・Orgのスクリーンショットは足元は居留すけど画質がjpgで劣化しててリテラが低い
Todayは無劣化のpng(>>918🆜)
>>933に使われてるGoogleの新規格のWebPは
圧縮率がpngよりも高いけど、
可逆(VP8L)と不可逆(VP8)で拡張子を別けて定義できないGoogleは理念が低い
SEOにページ表示速度を入れてるが、
速さよりも質
速度は後から改良が見込めるけど質は上げ治さない限り不良(WebPには上限も在るらしい)
♊
2ch(sc)のアーカイブがOrg, Today共に執れなくなってる
2ch(sc)は1000落ち後のdat化をミスって
>[エラー]
>datが存在しません。
になるスレが在ったから、アーカイブを執れないと🜄物
この近頃多発な執れないドメイン問題、
正体不明のToday: 🪆https://gigazine.net/news/20240326-archive-today/
には、どんな手を遣ってでも執れる様に期待w
>>934🙈→>>829
🪬https://mevius.5ch.net/test/read.cgi/hard/1717147167/1000n
𝐇𝐔𝐌!→𝐇𝐫𝐦.でバイツァダストが关ってるとか本来は生涯を通して知らせる事は無い
940名無しさん@お腹いっぱい。
2024/11/09(土) 10:12:51.41 糖質はスルー推奨
941名無しさん@お腹いっぱい。
2024/11/10(日) 07:36:27.44 ちんこ!
2024/11/10(日) 16:22:10.69
http://thai.jinsei.link/jumborg-ace-toy-thailand/
↑を取得しようとすると、404なってしまう
ほかのサービスだとウェブ魚拓はNG、Archive.todayはOK
↑を取得しようとすると、404なってしまう
ほかのサービスだとウェブ魚拓はNG、Archive.todayはOK
2024/11/10(日) 16:50:33.24
>>942
HTTP HEAD が投げられると 404 を返すとか、そういうパターンか。
直接 GET で行けば採れるっぽい。
https://web.archive.org/web/20241110074334/thai.jinsei.link/jumborg-ace-toy-thailand/
HTTP HEAD が投げられると 404 を返すとか、そういうパターンか。
直接 GET で行けば採れるっぽい。
https://web.archive.org/web/20241110074334/thai.jinsei.link/jumborg-ace-toy-thailand/
2024/11/14(木) 15:21:11.41
このAPIはまだ使えないのか
https://archive.org/help/wayback_api.php
https://archive.org/help/wayback_api.php
2024/11/14(木) 15:44:57.62
ヘルプページが死んだままだからって API も死んだままとは限らんよね


2024/11/14(木) 21:00:37.15
新規にページ保存しても保存されてない扱いで返ってくるな…
またクラッカー共にやられてんのか?
またクラッカー共にやられてんのか?
947名無しさん@お腹いっぱい。
2024/11/16(土) 09:12:00.56 outlinks復活したな
2024/11/16(土) 11:13:46.48
2024/11/16(土) 15:16:50.38
絵文字糖質は今週末は休みかなw
メールアドレス変更を試して、認証 URL が機能せず失敗、を何回か繰り返すと制限が掛かるのね
本垢でやらなくて良かった
新規アカウント認証用の https://archive.org/account/verify.php は動いてるけど
メアド変更認証用の https://archive.org/account/verify-email.php はエラーのまま

メールアドレス変更を試して、認証 URL が機能せず失敗、を何回か繰り返すと制限が掛かるのね
本垢でやらなくて良かった
新規アカウント認証用の https://archive.org/account/verify.php は動いてるけど
メアド変更認証用の https://archive.org/account/verify-email.php はエラーのまま

950939
2024/11/16(土) 20:47:22.99 authorization: LOW = >>949のWAISのスコアがLOW
なシークレッドコードにも一生気付かなそう
@internetarchiveのポスト見ても絵文字がどーたら言ってんのかな
>>ssspは>>793で必要の無い99を調べてる処からもLOW
統合失調者の20年近く前の記憶など訊いてない
0 = 最古が事実
正直ssspのレスは登錄する必要がない輩 = HIGH(myaccesskey:⬆)には只のゴミレス
>>936
Todayの様な匿名サイトで再構築しないと
>>939の🔲な事態となるのがLaw
𝐇𝐫𝐦.化したアーカイブは
時限で治ってるリンクと治らないリンクがある様なので
再チェックが必要
なシークレッドコードにも一生気付かなそう
@internetarchiveのポスト見ても絵文字がどーたら言ってんのかな
>>ssspは>>793で必要の無い99を調べてる処からもLOW
統合失調者の20年近く前の記憶など訊いてない
0 = 最古が事実
正直ssspのレスは登錄する必要がない輩 = HIGH(myaccesskey:⬆)には只のゴミレス
>>936
Todayの様な匿名サイトで再構築しないと
>>939の🔲な事態となるのがLaw
𝐇𝐫𝐦.化したアーカイブは
時限で治ってるリンクと治らないリンクがある様なので
再チェックが必要
2024/11/16(土) 23:17:45.36
>>950
もうちょっと根本的な反論をしてみろよ低能糖質
もうちょっと根本的な反論をしてみろよ低能糖質
953名無しさん@お腹いっぱい。
2024/11/17(日) 05:01:30.32 糖質はスルー推奨
954名無しさん@お腹いっぱい。
2024/11/19(火) 16:52:55.54 SSブログ(so-netブログ)がサービス終了だって
2024/11/19(火) 23:08:27.12
俺環だけかもしれないが、21時台から(それまではなんともなかった)
ttps://web.archive.org/saveまではつながるのに、取得しようとするとNot FoundだったりService Unavailableだったり
ttps://web.archive.org/saveまではつながるのに、取得しようとするとNot FoundだったりService Unavailableだったり
2024/11/19(火) 23:20:30.61
と思ってたらJob failed.とかSave Page Now could not capture this URL because it was unreachable.とかThe server didn't respond in time forとか出るもののつながった
2024/11/20(水) 15:36:51.32
>>582
2024/12/20 閉鎖 vectorの作者個人ページ >>505
2025/03/31 SSブログ終了 https://blog-wn.blog.ss-blog.jp/2024-11-15
やれやれ、
2024/12/20 閉鎖 vectorの作者個人ページ >>505
2025/03/31 SSブログ終了 https://blog-wn.blog.ss-blog.jp/2024-11-15
やれやれ、
2024/11/20(水) 21:30:21.15
SSブログはArchiveTeam辺りが取ってくれないかな
頼み方?が分からんけど
頼み方?が分からんけど
2024/11/20(水) 21:39:48.24
これホスティングしているブログのID一覧って取る手段ない感じ?
新着記事一覧とか見てもページングが20件くらいしかない
URLの形式はこうと。
https:// [*].blog.ss-blog.jp/
新着1000件はこれで見れるが…
https://blog.ss-blog.jp/index.xml
新着記事一覧とか見てもページングが20件くらいしかない
URLの形式はこうと。
https:// [*].blog.ss-blog.jp/
新着1000件はこれで見れるが…
https://blog.ss-blog.jp/index.xml
2024/11/20(水) 21:43:49.85
2024/09/30 閉鎖 アキバ総研 >>524-527
2024/12/20 閉鎖 vectorの作者個人ページ >>505
2025/03/31 閉鎖 魔法のiらんど >>653
2025/03/31 閉鎖 SSブログ https://blog-wn.blog.ss-blog.jp/2024-11-15
あれ、iらんどと同じ日なのか…
2024/12/20 閉鎖 vectorの作者個人ページ >>505
2025/03/31 閉鎖 魔法のiらんど >>653
2025/03/31 閉鎖 SSブログ https://blog-wn.blog.ss-blog.jp/2024-11-15
あれ、iらんどと同じ日なのか…
2024/11/20(水) 22:13:38.94

962961
2024/11/20(水) 22:15:53.34 そうか必要なのは blog.ss-blog.jp のサブドメイン一覧か
勘違いした申し訳ない
勘違いした申し訳ない
2024/11/20(水) 22:17:11.23
>>961
それだと既にアーカイブされているURLしか見つからない訳で、
既にアーカイブされてるなら、あれ もうする事なくねって思っちゃう…
まあ各ブログの個別の記事を改めて明示的にアーカイブするとかあるけどさ。
それだと既にアーカイブされているURLしか見つからない訳で、
既にアーカイブされてるなら、あれ もうする事なくねって思っちゃう…
まあ各ブログの個別の記事を改めて明示的にアーカイブするとかあるけどさ。
2024/11/21(木) 00:15:46.82

EchoAPIはAPIの管理とテストをシームレスに行うためのツールとなっていて、Web開発もずっと簡単で効率的にしてる!
2024/11/23(土) 23:53:23.83
>>920
IAと契約して魔法使いになってよ
通常英語になるアマゾンを日本語でアーカイブさせた例
一般人:https://archive.is/FVU6Z
買った商品の記録に「おま国」発動
This item cannot be shipped to your selected delivery location. Please choose a different delivery location.
魔法使:https://archive.is/wEGlh
一般人:https://archive.is/pNf8p
魔法使:https://archive.is/HPeoy
IAと契約して魔法使いになってよ
通常英語になるアマゾンを日本語でアーカイブさせた例
一般人:https://archive.is/FVU6Z
買った商品の記録に「おま国」発動
This item cannot be shipped to your selected delivery location. Please choose a different delivery location.
魔法使:https://archive.is/wEGlh
一般人:https://archive.is/pNf8p
魔法使:https://archive.is/HPeoy
2024/11/24(日) 02:14:59.06
2024/11/25(月) 04:37:31.60
5chの古いスレの過去ログが復活したから見れるうちにアーカイブ
復活した過去ログは
https://itest.5ch.net/kako/test/read.cgi/板名/1690495133
https://kako.5ch.net/test/read.cgi/板名/1690495133
この2パターンあるけどまあどっちでもよさそう。個人的には前者の方が見やすい。
復活した過去ログは
https://itest.5ch.net/kako/test/read.cgi/板名/1690495133
https://kako.5ch.net/test/read.cgi/板名/1690495133
この2パターンあるけどまあどっちでもよさそう。個人的には前者の方が見やすい。
2024/11/25(月) 09:40:02.39
しまった、マンガ図書館Zも明日閉鎖か!
マンガ本体はともかく作品一覧だけでも作っておこうと思ったんだが…もう遅い
2024/09/30 閉鎖 アキバ総研 >>524-527
2024/12/20 閉鎖 vectorの作者個人ページ >>505
2024/11/26 12時 閉鎖 マンガ図書館Z https://closing.mangaz.com/info/2114/index.html
2025/03/31 閉鎖 魔法のiらんど >>653
2025/03/31 閉鎖 SSブログ https://blog-wn.blog.ss-blog.jp/2024-11-15
マンガ本体はともかく作品一覧だけでも作っておこうと思ったんだが…もう遅い
2024/09/30 閉鎖 アキバ総研 >>524-527
2024/12/20 閉鎖 vectorの作者個人ページ >>505
2024/11/26 12時 閉鎖 マンガ図書館Z https://closing.mangaz.com/info/2114/index.html
2025/03/31 閉鎖 魔法のiらんど >>653
2025/03/31 閉鎖 SSブログ https://blog-wn.blog.ss-blog.jp/2024-11-15
2024/11/25(月) 21:20:21.46
今年はサービス終了地獄だったな
来年とか更にどうなってしまうのか
来年とか更にどうなってしまうのか
2024/11/25(月) 22:43:13.28
>>969
復活したけど .dat が無いんよね・・・
復活したけど .dat が無いんよね・・・
2024/11/25(月) 23:07:12.40
2024/11/26(火) 08:55:37.37
このままいくと2000年代のネット情報は殆ど何も残らなくなりそうだな
ガラケー関係は既に死滅状態だし
ガラケー関係は既に死滅状態だし
2024/11/26(火) 20:15:48.50
10年以上前の個人サイトのエロ小説とかこう残ってたらなあと期待するがそううまくいかんな
2024/11/26(火) 21:49:12.41
エヴァのオリキャラ上等時代のSSとかどこにあるかな
当時のGAINAXは許可サイトのURL一覧ページ作っていたからそこから辿れば見れるかな
当時のGAINAXは許可サイトのURL一覧ページ作っていたからそこから辿れば見れるかな
978950
2024/11/28(木) 12:28:18.20 >>954
ソラ、Soよ
>>967-968
なのラ!
≫953🙉はSikiのデフォルト設定にすらDerezzedされてる事も死ぬまでシラなソう
>>955-956
アーカイブしたページがランダムに𝐇𝐫𝐦.化して未採取になるバグの残存リンクも19日に復旧された
4日に執って検証用に再アーカイブを賭けなかったリンクは19日迄ずっと𝐇𝐫𝐦.状態だった
>>939🔲のStack Exchangeも現在はリダイレクトされずにアーカイブが表示される
が、
currently facing some limitationsな𝕏(Twitter)ら辺は、訴えてやられたら全アーカイブボッシュート鴨葱(ビッグデータ至上主義)
そもそも🏛Internet Archiveは、
IA/イエーイ “われ”がダウソたら、🛂https://www.aozora.gr.jp/cards/000879/files/127_15260.html。
Wayback MachineにLog in機能は要らん
⌫24時間以内同一IPからならミスキャプチャアーカイブを削除できる機能
がOrgにもTodayにもジェバンニにも要る
Orgはミスキャプチャが多過ぎ!
・note.comの不可文が
>Sorry.
>This URL has been excluded from the Wayback Machine.
ではない>>918🌌
・オーパーツ(>>910❔📁: 無納アドレスを納近アドレスに代替してしまう>>793的なバグ)
が繼続
>>>>>>882➡ ≒ ⬏https://web.archive.org/web/0if_/https://pbs.twimg.com/media/GdcL8DKaMAAA94R?format=png&name=orig
ソラ、Soよ
>>967-968
なのラ!
≫953🙉はSikiのデフォルト設定にすらDerezzedされてる事も死ぬまでシラなソう
>>955-956
アーカイブしたページがランダムに𝐇𝐫𝐦.化して未採取になるバグの残存リンクも19日に復旧された
4日に執って検証用に再アーカイブを賭けなかったリンクは19日迄ずっと𝐇𝐫𝐦.状態だった
>>939🔲のStack Exchangeも現在はリダイレクトされずにアーカイブが表示される
が、
currently facing some limitationsな𝕏(Twitter)ら辺は、訴えてやられたら全アーカイブボッシュート鴨葱(ビッグデータ至上主義)
そもそも🏛Internet Archiveは、
IA/イエーイ “われ”がダウソたら、🛂https://www.aozora.gr.jp/cards/000879/files/127_15260.html。
Wayback MachineにLog in機能は要らん
⌫24時間以内同一IPからならミスキャプチャアーカイブを削除できる機能
がOrgにもTodayにもジェバンニにも要る
Orgはミスキャプチャが多過ぎ!
・note.comの不可文が
>Sorry.
>This URL has been excluded from the Wayback Machine.
ではない>>918🌌
・オーパーツ(>>910❔📁: 無納アドレスを納近アドレスに代替してしまう>>793的なバグ)
が繼続
>>>>>>882➡ ≒ ⬏https://web.archive.org/web/0if_/https://pbs.twimg.com/media/GdcL8DKaMAAA94R?format=png&name=orig
979名無しさん@お腹いっぱい。
2024/11/28(木) 16:33:38.30 糖質はスルー推奨
980名無しさん@お腹いっぱい。
2024/11/28(木) 16:59:05.05 今回のトラブル中に残せなかったのがいくつもある
2024/11/29(金) 14:13:19.70
>>970
https://info.seesaa.net/article/505833903.html
閉鎖では(現状)ないが、Seesaaブログ運営会社がしたらばに変更
そういやしたらば(ライブドア)掲示板も過去との連続性どうなってんだろうな
大昔に作って放置されてる掲示板とかどうなってんだろ
https://info.seesaa.net/article/505833903.html
閉鎖では(現状)ないが、Seesaaブログ運営会社がしたらばに変更
そういやしたらば(ライブドア)掲示板も過去との連続性どうなってんだろうな
大昔に作って放置されてる掲示板とかどうなってんだろ
2024/11/29(金) 18:00:28.51
2024/12/01(日) 00:06:04.89
vectorの個人作者ホームページ終了まで残り20日
2024/12/01(日) 00:22:20.42
アーカイブって訳じゃないけど一覧は作って公開した。他に出来る事って無いよね
2024/12/01(日) 03:08:01.63
x.com でこんなのが出た。


2024/12/01(日) 07:44:18.59
987名無しさん@お腹いっぱい。
2024/12/01(日) 17:00:55.92 Vectorはもうarchivebot に投げられているっぽいな
https://archive.fart.website/archivebot/viewer/?q=hp.vector.co.jp
https://transfer.archivete.am/Upgah/hp.vector.co.jp-authors-VA-200.txt
https://archive.fart.website/archivebot/viewer/?q=hp.vector.co.jp
https://transfer.archivete.am/Upgah/hp.vector.co.jp-authors-VA-200.txt
2024/12/01(日) 22:00:56.00
>>987
こんなサイトあったのか知らなかった
こんなサイトあったのか知らなかった
989978
2024/12/02(月) 01:43:19.42 🔭https://web.archive.org/web/20210708121508/https://kemur.jp/retro-star-viewer-210607
Org恒例の画像が表示されないパターンのアーカイブだったけど、
ダウソ板で使う予定の一枚を11月28日にキャプチャしたら他画像も2024/11/30から未来トランクス
現在は、サムネが途中からひどくありふれたホワイトノイズだがTodayからは観らるる: 👍https://archive.Today/Gj67i
🏛https://archive.Today/vcfxp
>同時点で収集されたものとは限らず、1年以上の時間差があることも稀ではない。
🧳http://img1.gamersky.com/image2015/01/20150104wb_6/gamersky_29origin_57_2015141411DC2.jpg
実際に同一URL差し替え異画像をチェ───ンジ!!!!!しもうてたら//web.chimera.orz/
🖼画像の欠けたアーカイブは、クローラーやsave-page-now-outlinksの仕業じゃ! >>>134-143
このポンコツ仕様、中の誰一人としてコレジャナイと思わんのか?
>>918❔✅アドレスはoutlinksの無納 ∴ outlinksは(゚⊿゚)イラネ
複アカまで使ってキャプチャ数制限をリミットブレイクしちゃってるこのスレの██は
セーブしたアーカイブの🧬https://archive.Today/CCVEz/cfce8cba3a853373afee72836ac981885eb725b5.jpg
なんてまずcf.してないヨネ。██だから
>>910🗓
OCT 11~NOV 1が🈳だったのが現在は🔵
ご乱立botクローラが無駄ァに重合しまくってるナニコレ珍千景、
NOV 24の8450 snapshotsとか総アーカイブ数🜄増しの為にやってんの?w
🔵は、統合者ならクローラ採取や直前との差分発生を記号や色で標示するけどな(💠な区画型アイコンだと多彩標現可)
🇧🇷のURLを5chに記入出来なかった自称魔法使の>>967
>>978⬏のクッキーさんのツイートをダウソ板で遣う調和だから魔法でアーカイブ録っといて
それ、𝕏からログアウトしてると観測問題できない特殊アドレス
🂡
あべべのべを🚉https://archive.Today/vcfxp/imageしたのは
山上ではなく式神なのは🤫デスけ
⌦⛎https://livedoor.blogimg.jp/luciagame-cadotbkr/imgs/1/0/10a731d5.png
Org恒例の画像が表示されないパターンのアーカイブだったけど、
ダウソ板で使う予定の一枚を11月28日にキャプチャしたら他画像も2024/11/30から未来トランクス
現在は、サムネが途中からひどくありふれたホワイトノイズだがTodayからは観らるる: 👍https://archive.Today/Gj67i
🏛https://archive.Today/vcfxp
>同時点で収集されたものとは限らず、1年以上の時間差があることも稀ではない。
🧳http://img1.gamersky.com/image2015/01/20150104wb_6/gamersky_29origin_57_2015141411DC2.jpg
実際に同一URL差し替え異画像をチェ───ンジ!!!!!しもうてたら//web.chimera.orz/
🖼画像の欠けたアーカイブは、クローラーやsave-page-now-outlinksの仕業じゃ! >>>134-143
このポンコツ仕様、中の誰一人としてコレジャナイと思わんのか?
>>918❔✅アドレスはoutlinksの無納 ∴ outlinksは(゚⊿゚)イラネ
複アカまで使ってキャプチャ数制限をリミットブレイクしちゃってるこのスレの██は
セーブしたアーカイブの🧬https://archive.Today/CCVEz/cfce8cba3a853373afee72836ac981885eb725b5.jpg
なんてまずcf.してないヨネ。██だから
>>910🗓
OCT 11~NOV 1が🈳だったのが現在は🔵
ご乱立botクローラが無駄ァに重合しまくってるナニコレ珍千景、
NOV 24の8450 snapshotsとか総アーカイブ数🜄増しの為にやってんの?w
🔵は、統合者ならクローラ採取や直前との差分発生を記号や色で標示するけどな(💠な区画型アイコンだと多彩標現可)
🇧🇷のURLを5chに記入出来なかった自称魔法使の>>967
>>978⬏のクッキーさんのツイートをダウソ板で遣う調和だから魔法でアーカイブ録っといて
それ、𝕏からログアウトしてると観測問題できない特殊アドレス
🂡
あべべのべを🚉https://archive.Today/vcfxp/imageしたのは
山上ではなく式神なのは🤫デスけ
⌦⛎https://livedoor.blogimg.jp/luciagame-cadotbkr/imgs/1/0/10a731d5.png
990名無しさん@お腹いっぱい。
2024/12/02(月) 07:23:55.43 糖質はスルー推奨
991名無しさん@お腹いっぱい。
2024/12/02(月) 19:14:25.43 ぷららのホームページサービスが来年3月31日に終了するらしい
https://www.docomo.ne.jp/info/notice/page/240627_01.html
https://www.docomo.ne.jp/info/notice/page/240627_01.html
2024/12/03(火) 02:41:40.51
http://www{1~20}.plala.or.jp/名前
http://business{1~4}.plala.or.jp/名前
ちょっと見てみたら紅白歌合戦完全マニュアルってサイトはぷららホームページサ終と共に閉鎖するそうな
http://www1.plala.or.jp/nakaatsu/
こういうサイトが結構多いかもしれない
http://business{1~4}.plala.or.jp/名前
ちょっと見てみたら紅白歌合戦完全マニュアルってサイトはぷららホームページサ終と共に閉鎖するそうな
http://www1.plala.or.jp/nakaatsu/
こういうサイトが結構多いかもしれない
2024/12/04(水) 10:04:54.60
>>991
うおっこれは知らんかった。しかも発表済みだったのか
うおっこれは知らんかった。しかも発表済みだったのか
994名無しさん@お腹いっぱい。
2024/12/04(水) 11:50:00.86 ネッ糖フリチャックス
2024/12/04(水) 15:09:55.27
Internet Archive総合 (web.archive.org) #6
https://mevius.5ch.net/test/read.cgi/esite/1733289042/
https://mevius.5ch.net/test/read.cgi/esite/1733289042/
2024/12/04(水) 21:53:14.78
テンプレの>>8
次スレに貼ろうとしたら吸い込まれたんよね
次スレに貼ろうとしたら吸い込まれたんよね
2024/12/05(木) 01:28:59.57
2024/12/05(木) 07:28:59.96
2024/12/05(木) 12:58:52.94
>>995
乙アーカイブ
乙アーカイブ
1000名無しさん@お腹いっぱい。
2024/12/05(木) 13:05:39.45 1000
10011001
Over 1000Thread このスレッドは1000を超えました。
新しいスレッドを立ててください。
life time: 496日 6時間 6分 47秒
新しいスレッドを立ててください。
life time: 496日 6時間 6分 47秒
10021002
Over 1000Thread 5ちゃんねるの運営はUPLIFT会員の皆さまに支えられています。
運営にご協力お願いいたします。
───────────────────
《UPLIFT会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
4 USD/mon. から匿名でご購入いただけます。
▼ UPLIFT会員登録はこちら ▼
https://uplift.5ch.net/
▼ UPLIFTログインはこちら ▼
https://uplift.5ch.net/login
運営にご協力お願いいたします。
───────────────────
《UPLIFT会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
4 USD/mon. から匿名でご購入いただけます。
▼ UPLIFT会員登録はこちら ▼
https://uplift.5ch.net/
▼ UPLIFTログインはこちら ▼
https://uplift.5ch.net/login
レス数が1000を超えています。これ以上書き込みはできません。

ニュース
- 永野芽郁 打ち上げでスピーチ「週刊誌から声かけられたら知りませーん!って言ってくださいね」「ご迷惑をおかけしてすいませーん。ふふふ」 [Ailuropoda melanoleuca★]
- 【コメ】米価抑制 小泉農相「スピードが求められる。速やかに結果を出せるように全力で頑張りたい」 [少考さん★]
- 女性が「住みたい街」ランキング2025(首都圏版)。高円寺や荻窪を抑えた1位は“あの駅” [少考さん★]
- 【長野】米価抑制で5キロ2千円台も 小泉農相 [少考さん★]
- 小泉農相、備蓄米の入札中止 スーパーなどに直接売り渡す考えも ★4 [おっさん友の会★]
- 小泉農相、備蓄米の入札中止 スーパーなどに直接売り渡す考えも ★5 [おっさん友の会★]
- 【万博虫】飲食店が悲鳴「沢山の虫さんで悲惨な状況」 [455679766]
- 【速報】イスラエル大使館員2人が射殺され死亡 アメリカ [597533159]
- 「祖国を守るために戦争に行く」日本の若者はたった13%で世界最低。諸外国は70%-80%、大丈夫かよこの国.. [512028397]
- 万博関係者「まさか木製リングと人口池を作ったら虫が大量発生するとは……想定外だ」 [315836336]
- 江藤拓「お前のことなんか嫌いだ」小泉進次郎氏との面会で [399259198]
- 河野太郎「江藤農相は辞めなきゃいけないような失言なのか」 [817260143]