Internet Archive総合 (web.archive.org) #2 ©2ch.net
■ このスレッドは過去ログ倉庫に格納されています
>>317
何だろうねぇ。
http://web.archive.org/web/20181211002734/www26.atwiki.jp/gcmatome/pages/1017.html
念のため、この時に使った User-Agent 文字列を貼っておく。
Mozilla/6.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0 atwikiはFirefox 52にトラウマでもあるのか ふむふむ
http://web.archive.org/web/20181211102115/www26.atwiki.jp/gcmatome/pages/1017.html
Mozilla/6.0 (Macintosh; Intel Mac OS X 10.13; rv:60.0) Gecko/20100101 Firefox/60.0
>>320
/save/ を叩いた時なんだけど、もし点数方式で判定するなら
◎ IP は archive.org の取得用サーバ群の中の何れか一つが使われる。
米国の IP であること、また名前に www が入っていることは加点対象になる可能性あり。
同じ IP からの繰り返しアクセスも加点対象になる可能性あり。
◎ User-Agent を含め、リクエストヘッダはクライアントのものがそのまま転送される。
古いブラウザを使っていると加点対象になる可能性あり。
◎ さらに Via: HTTP/1.0 web.archive.org (Wayback Save Page) が追加される。
これは間違いなく加点対象。
この辺が総合的に判断されて弾かれているのだろう。
保存に成功することもあるので、Wayback Machine だからと言って一律に判断しているのでは無いと思う。 そもそも閲覧回数が多いのってスパムっていうのだろうか
いや本筋と関係ないな 先週くらいから、上のほうに寄付金募集のバナーが出るようになったな。
しかもIEだと、右上の「×」をクリックしても、どうしたわけかバナーが消えない。
この募集は本気だな。 将来見たくなった時のためにそれの魚拓も撮っといてくれ ウィキのコーヒー1杯みたいな洒落たジョークじゃないと金が集まらんぜ http://web.archive.org/web/20181223223511/https://www26.atwiki.jp/gcmatome/pages/2928.html
http://web.archive.org/web/20181223223509/https://www26.atwiki.jp/gcmatome/pages/686.html
またスパム扱いされてる 221 名前:名無しさん@お腹いっぱい。[] 投稿日:2018/12/22(土) 16:36:12.78
こういう海外サービスを発見した。
まだちょこっとしか試していないが。
Archive.st
https://archive.st
Time Travel
(ブラウザから「このサイトはやばいかもしれない」
という警告が出たが、おそるおそる行ってみると
特にまずいことはなかった)
http://timetravel.mementoweb.org Wayback Everywhereってアドオン使ってるけど他に便利なのないかな 以前のいつかと同じく、18年12月29日深夜から現在に至るまで取得したアーカイブの消失が起きている
注意されたし 名前上がらないけどWebrecorderとかInterPlanetary Waybackとか知ってる?
いいぞ〜これ Webrecorderは、Webページからwarcファイルを生成するWebアプリケーション
生成したwarcはコレクションに保存され、そのまま表示したり、
会員なら公開コレクションにすることでURLを貼って公開できる
+ New Sessionの隣の「…」から「Download Collection」でコレクション内のwarcファイルをダウンロードできる
warcファイルは魚拓の規格化された形式で、HTTPのステータスコードから画像や動画までそのページを表示するのに必要な情報を格納している
とりあえずwarcファイルさえあれば後からどうにでもなるから残したいサイトは今すぐcaptureしてこい
warcファイルを表示するには、「Webrecorder-player」というアプリが使える
またWebrecorderのコレクションにwarcファイルをアップロードして追加することも可能なので、そうやって表示や公開をしてもいい
InterPlanetary Waybackはもうちょっと高度な話で、IPFSと連携するためのものなんだけどこれは後でいい 19/01/13の分から取得したアーカイブが確認不可能になっている >>214 と同じ URL の 2018 年カレンダーを貼ってみます。
10 月に連続して欠けているのは、Internet Archive の仕様変更に対し
こちらの対応が遅れた (>>291) ことが原因です。
ttp://i.imgur.com/aYSmomB.png
ttp://i.imgur.com/35RP1No.png
ttp://i.imgur.com/fRsG33D.png
こちらは URL を公開しちゃってもいいや。
この人の騒動について個人的に興味が無くなってきていること、
また別途取得させている個別エントリのアーカイブで十分なことから、いずれ止めるかもしれません。
ttp://web.archive.org/web/*/blog.goo.ne.jp/chimaki-1014
昨年 3 月以降、一日 2 回の取得に対し計 4 回のスナップショットが記録されているのは、
HTTP から HTTPS へのリダイレクトと HTTPS で取得したブログコンテンツが
それぞれ計上されているためかと思われます。 先週辺りから
「502 Bad Gateway」が
表示されることが多くなった NHKニュース公式のスクショが
ちゃんと保存されないポンコツびりには
あきれた ×ポンコツびり
〇ポンコツぶり
あー本当に腹が立つ 近々でNHK NE○S W○Bのトップページを
InternetArchive経由で魚拓を取った人は
一度確かめてほしい
なぜか画面が「本日現在」の状態になっているから
ウェブ魚拓ではMETAタグが引っかかって駄目
ArchiveTodayも変な画像(白地に黒文字の注意書き?のみ)
を結果として返してくるので駄目
まさか頼みの綱のInternetArchiveで大失敗するとは思わなんだ
どうしてもN○K NEWS ○EBのトップページを残したければ
画面を直に撮影するしか方法は無いようだ htmlに本文が入ってなくて、ajax的に別のファイルから読み込むやつはいかんな。
wixも同じ理由で保存されてない。
本文ファイルのキャッシュが残ってたとしても、それを読み込みに行ってくれないのよね で、それはwebrecorderでも保存できないのかい? >>361
使い方が分かりにくいな
記録(魚拓)は取れても
その取り出し方がいまいち分かり辛い
後日に取り出してその当時の状態を
再現できなければ意味がないし >>360-361
何で「NHK NE○S W○B」のトップページの話を出したかといえば
先週日曜(1月27日)にあった某「国民的」グループの活動休止発表からだった
この時「N○K NEWS ○EB」のトップページでは
最上部の「速報」・そのすぐ下の「JUST IN」・本記事と
同時に3つの見出しで「○活動休止」の文字が並ぶという
何とも稀な状態になっていた
そこでInternetArchiveでページの魚拓を取り
同時にIrfanview経由でスクリーンショットを取った“はず”だったのだが
その画像を何らかの形で保存することをうっかり忘れてしまっていた
そして翌朝になってInternetArchiveを確認したら…
下のような状況になっていた
https://i.imgur.com/IBOpfrs.jpg
すなわち明けて1月28日になったが
前日27日に取ったものが表示されないという状態
一応は類似の画像を検索してみたがこんなのしか出なかった
https://pbs.twimg.com/media/Dx56MVSV4AEsqgB.jpg そんなわけで試しに1月27日以前に取られたものも表示してみたが
結局どの日でも表示されるのは“作業当日”の画面だった
つまりは二重三重で痛恨のミスをやらかしたことになり
本当に今週はそれを引きずった…
このままでは何か癪に障るので
おまけを罪滅ぼしに置いておく
(1月31日)
https://i.imgur.com/E96yEeA.jpg
https://i.imgur.com/bCjdPXO.jpg
https://i.imgur.com/EAUNldo.jpg
(昨2月1日)
https://i.imgur.com/hpvfmr9.jpg 時々出てくるこれ、具体的に何かやっているというより、
503 応答のエラーページがこのように書かれているだけとしか思えないんだけどなぁ。
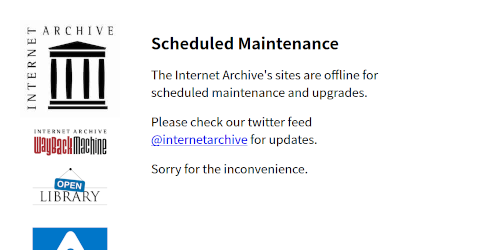 >>366
>>366
文字通りメンテナンス中と思わせるくらいに
数時間表示される場合もあれば…
この画面が出た後で再読み込みをしたら
すぐにトップ画面に戻る場合もある リンク先がなにもない真っさらなページだった時ってもう諦めたほうがいいですか? たしかに2/19にとったやつが消えてますね
前もこんなこと1週間くらい続いたけど戻ったときがあったので様子見ですかね アーカイブのサイトが何だかおかしいね
当サイトは昨日「Sorry,we are busy」なんていう
初めて見た表示が出た
ウェブ魚拓は今日の午前中重かった
Archive isは断続的にキレる
一体全体どうなってるのか yahoo!ブログまでサービス終了だ
どんどん老舗が消えていくなあ ネットのデータは儚い Yahoo!ブログ消えるのにYahoo!系はなぜかInternet Archiveで保存しても全部トップページに転送されちゃうから保存できないんだよな… 何だか重くなってるぞ
20分くらい前にはアクセス不能になっていたし 2日前くらいからarchive.orgの再生時画面が小さくなってしまって辛い
全画面だと作業が出来ないしなあ >>379
このトップページ転送本当どうにかならんのかな。 >>383
何なんだろうなこれ
自前でHeritrix回すとどんな感じになるんだろう
Yahooブログアーカイブ活動の本スレ
http://mevius.5ch.net/test/read.cgi/blog/1554380939/ 魚拓もInternet Archiveも引っ掛からないスレタイって >>388
サンクス。
adblockの詳細設定のマイフィルターリストに「*/yjsecure.js」を登録してadblock有効で転送されなくなった。 http://mevius.5ch.net/test/read.cgi/internet/1554553882/78-79
/save/ を知ってて /web/2/ を知らないとは。
あと保存の際に http:// や https:// を無条件に外すのも考え物。
HTTP から HTTPS へリダイレクトするサイトだと、そのリダイレクトも
保存回数に計上されてしまう。 >>392
そのブックマークレットを作った人間ではないけど、Wayback Machine初心者の自分に/web/2/が何なのか教えて下さい
あと保存回数の計上が増えると何か問題があるの? /save/知ってるのはgeocitiesのスレの方で多用されてたからじゃないかな >>395
これ
/web/2/は初めて聞いたけどその二つは言うほど特別な知識ではないと思うよ >>398
っぽいですね。
https://i.imgur.com/gZyzB5u.png
ただ、アーカイビングとインデクシングはそれぞれ独立しているみたいなので、
後者だけでデータの欠落が発生しているという可能性もあると思います。 全ページ内全文検索はまだ?
なんか問題でもあるのか? 昔やってたけどすぐ立ち消えたからきつかったんじゃね Scheduled Maintenance
先ほどからこの表示
長くなりそうか? >>406
機械翻訳使ったのかどうか知らんが、文章の意味を読み取れて無いだけやんか。 >>406
米国政府のサイトと米軍のサイト限定って書いてあるな
そこまで強調して書いてある訳ではないとは言えもうちょっと慎重に読もう
しかし、robots.txtが邪魔なら全サイトで無視しちゃば良いのにな
どうせ法的拘束力はないんだし 過去分リストが今日から(?)マイナーチェンジしている件 自動的に最新ログの年に飛ばない気がする。2019年。 数分前から「HTTP ERROR 400」と出て使えない 手動で1ページ1カテゴリーづつ保存するの面倒くさいんですけど、
自動巡回で指定のサイトやブログをhttps://web.archive.org/に保存出来る方法なんて無いですよね?
毎日毎日徹夜で保存して疲れた…保存しても保存してもキリがない… >>413
>毎日毎日徹夜で保存して疲れた…
>保存しても保存してもキリがない…
アーカイブサイト全般のユーザーの
最大の悩みでもあるな
一度やり始めたら強迫観念が出てきて
毎日やらねばならなくなる
しかも誰もがやっているわけじゃなさそうだから
自分が休んでも他の人が補完してくれる保証はないしね やろうと思えばプログラム組んで出来るよ、ネット探せば色々見つかる
さっきWebアーカイブ総合スレに投稿されたやつを転載
0175 py ◆o3kzHb/in8w0 2019/05/14 19:06:58
https://u1.getuploader.com/irvn/download/1657
web2IAWBM.dms ver0.000.007 WayBackMachineに保存 (web.archive.org) 2019/05/14
web2IAWBM.dmsはIrvineとDorothy2を使ってInternet Archive WayBack Machineに自動登録(保存)するためのスクリプトです。
自動で全てのリンクをたどって保存してくれるはずです。
web2IAWBM.dmsは素人が作った物なので至らない点も多々ありますが、
一応使える水準になったと思われるので公開します。
無料のウィルススキャンはしましたが、念のためもう一度スキャンされることをお勧めします。
同梱のDorothy2(の一部)は別の方が作った物です。
■ Irvine初回起動前に必ず jwordフォルダを削除してください。■
動作試験環境:windows10pro Irvine1.3.1 IAヘビーユーザーが多いであろうここの住人なら、
自動化手段を発見済みかスクリプト自作してる人がいるだろうと思ってたが、案外そういう訳でもないのかな >>414-416
ありがとうございます。
勇気出して聞いてよかった…頑張る ■ このスレッドは過去ログ倉庫に格納されています


