
探検
Internet Archive総合 (web.archive.org) #3
レス数が1000を超えています。これ以上書き込みはできません。
0511名無しさん@お腹いっぱい。
2020/10/03(土) 20:46:46.28ご回答ありがとうございました。
0512名無しさん@お腹いっぱい。
2020/10/03(土) 22:59:15.77どうして Internet Archive という「他人」に保存させようとするんだ?
リテラシーが崩壊してるわw
0513名無しさん@お腹いっぱい。
2020/10/04(日) 00:30:28.820514名無しさん@お腹いっぱい。
2020/10/04(日) 01:06:25.33例えば学術論文リポジトリはログインしないと閲覧出来ない場合も多くて問題になってたりする
0515名無しさん@お腹いっぱい。
2020/10/04(日) 01:17:45.63ディープウェブのWebアーカイブをどうやってやっていくべきかというのは割と難しい課題なのよ
ログインしないと入れないページは、ちゃんとした理由があるからこそ閲覧に制限がかかってる
でもそれと同時に、ちゃんとした理由があってログインしないと入れないページをアーカイブしたい場合というのも往々にしてあるわけ(上で挙げた学術論文リポジトリはその一例)
とは言え、いくらアーカイブする必然性があってもだからと言ってアクセス制限を無視して良いわけではないし、両者の兼ね合いは結構難しい
ともかくこういうのを単なるネットリテラシーの問題として済ますのは良くない
0516名無しさん@お腹いっぱい。
2020/10/04(日) 01:22:42.49それ以上は IA 側の知った話じゃないよ
0517名無しさん@お腹いっぱい。
2020/10/04(日) 03:15:02.69「関心を持って注視しているが現時点では対応していない」状況にぴったりな言葉じゃないと思う
0518名無しさん@お腹いっぱい。
2020/10/04(日) 15:45:40.69自分でローカルに保存すればいいじゃん
なんだかんだ言って天災・過失で自前バックアップ死ぬよりも、ネットの方が通報も含めて明らかに先に死ぬし
0519名無しさん@お腹いっぱい。
2020/10/04(日) 17:10:59.85言ってることがただの自己中だってことに気付けよ
0520名無しさん@お腹いっぱい。
2020/10/04(日) 17:23:57.000521名無しさん@お腹いっぱい。
2020/10/04(日) 21:38:12.330522名無しさん@お腹いっぱい。
2020/10/04(日) 22:44:09.00だよねー、普通は
0523名無しさん@お腹いっぱい。
2020/10/05(月) 01:02:47.64その兼ね合いが難しいって話よ
そもそもウェブアーカイブ自体著作権法スレスレのものだし、保存される側の都合を完璧に守るのは無理だと自分は割り切ってる
0524名無しさん@お腹いっぱい。
2020/10/05(月) 01:05:22.46保存する側とされる側の都合の兼ね合いは「自己中」で一蹴せず、ちゃんと考えていかなきゃいけないシリアスな問題だと思うよ
0525名無しさん@お腹いっぱい。
2020/10/05(月) 02:54:18.280526名無しさん@お腹いっぱい。
2020/10/05(月) 04:15:46.320527名無しさん@お腹いっぱい。
2020/10/05(月) 04:55:38.02何か恨みでもあるんかってくらい食い付いてるしな
感情論で殴ってるだけだから話自体に説得力ないし
0528名無しさん@お腹いっぱい。
2020/10/05(月) 10:48:51.05正義マンがポリコレ棒めっちゃぶんぶんしてるのに似てる
なんでルール守れないゴミ自己中のくせに被害者面してんの?
やべーわ
それで管理人がサイト更新意欲なくなっても
俺は悪くない!
とか宣うんだろw
0529名無しさん@お腹いっぱい。
2020/10/05(月) 17:14:59.29もっとやれ
0530名無しさん@お腹いっぱい。
2020/10/05(月) 19:42:44.10ここはTwitterのリプライかよ、くだらない
0531名無しさん@お腹いっぱい。
2020/10/06(火) 21:16:26.76考えていかなきゃいけない問題だとは思うが、ここで議論する意味は無い
0532名無しさん@お腹いっぱい。
2020/10/07(水) 18:39:57.750533名無しさん@お腹いっぱい。
2020/10/15(木) 08:59:33.08https://asahi.5ch.net/test/read.cgi/newsplus/1602676258/
0534名無しさん@お腹いっぱい。
2020/10/16(金) 05:28:12.15保存すらされてない
0535名無しさん@お腹いっぱい。
2020/10/16(金) 07:12:52.64Cannot start capture
0536名無しさん@お腹いっぱい。
2020/10/16(金) 07:24:27.85これ
0537名無しさん@お腹いっぱい。
2020/10/16(金) 12:16:07.53これ俺以外もなってたのか
おま環じゃなくてよかった
0538名無しさん@お腹いっぱい。
2020/10/16(金) 14:04:37.17Unknown Error
failed to archive the URL. specifics of failurte is unknown
0539名無しさん@お腹いっぱい。
2020/10/16(金) 14:10:34.97×failurte
○failure
手打ちしたら余計なものが混入してた
0540名無しさん@お腹いっぱい。
2020/10/16(金) 16:57:00.720541名無しさん@お腹いっぱい。
2020/10/16(金) 17:35:10.020542名無しさん@お腹いっぱい。
2020/10/16(金) 17:40:36.68>>535 >>538
これを直す為のメンテかな・・・?
0543名無しさん@お腹いっぱい。
2020/10/17(土) 05:55:06.62直ったかな
0544名無しさん@お腹いっぱい。
2020/10/17(土) 05:58:22.64俺の環境では確認できてないけど、
同じ日に10回以上保存されてるURLをさらに保存するとこんなエラーが出る場合があるらしい。
This URL has been already captured 10 times today. Please email us at "info@archive.org" if you would like to discuss this more.
まあ、ニュースサイトとかじゃない限り10回も保存はしないだろうけど。
0545名無しさん@お腹いっぱい。
2020/10/17(土) 09:10:23.030546名無しさん@お腹いっぱい。
2020/10/17(土) 15:39:48.960547名無しさん@お腹いっぱい。
2020/10/18(日) 13:05:45.08個々のニュースではなくサイトのトップとか一覧とかのアーカイブに固執してたから。
0548名無しさん@お腹いっぱい。
2020/10/18(日) 16:03:43.18isみたくトップからやり直さないと何年も前のアーカイブ開くだけで取り直すか聞かないのもウザイけどな
0549名無しさん@お腹いっぱい。
2020/10/19(月) 00:06:20.58あの人最近見かけないけど今どうしてるのかね
トップページや一覧ページの保存だけに血道を上げている様子は、正直言って病的というか空恐ろしいものがあった
他のスレ住人に何を言われてもほぼ反応なしで、何だか自分の世界に入り込んでるみたいだったね
彼は未だにスポーツ新聞のトップページを毎日手動で保存し続けているんだろうかね
0550名無しさん@お腹いっぱい。
2020/10/19(月) 04:33:54.40できるのとできないのがあるんだけど
違いはなんだろう
0551名無しさん@お腹いっぱい。
2020/10/19(月) 06:12:33.660552名無しさん@お腹いっぱい。
2020/10/20(火) 17:14:46.240553名無しさん@お腹いっぱい。
2020/10/20(火) 19:10:14.06Wayback Stats
https://archive.org/stats/
https://analytics0.archive.org/stats/wb.php
注目したいのはHTTP 200と503エラーのグラフと404エラーの割合グラフ
このスレでも報告があった10/15〜10/16は表示エラーが多くて、
10/17は一時半分近くエラー続きだったそうだ。
このURLはテンプレか>>1に入れといていいと思う。
0554名無しさん@お腹いっぱい。
2020/10/20(火) 21:53:07.53あとIEで見れなくなった
印刷プレビューはIEが一番使いやすかったのに…
0555名無しさん@お腹いっぱい。
2020/10/20(火) 22:53:30.54開発元のマイクロソフトもとっくにサポートやめて「代わりにEdge使ってね」ってしつこいくらい宣伝してたし...
0556名無しさん@お腹いっぱい。
2020/10/20(火) 23:00:54.10Internet Archiveに限らずIEでの閲覧を想定しないサイトは今後どんどん増えていくだろうし、
悪いこと言わないから他のブラウザに乗り換えた方が良いよ
というか、これはあくまで個人的な感想だからつもりはないけど、
IEの印刷プレビューって言うほど使いやすいかな?
Chromeに印刷プレビュー機能がなかった10年前じゃあるまいし
0557名無しさん@お腹いっぱい。
2020/10/20(火) 23:21:09.35Your browser may not be compatible〜ってのは出るけど。
0558名無しさん@お腹いっぱい。
2020/10/21(水) 00:30:53.60>10/17は一時半分近くエラー続きだったそうだ。
道理で保存されてないのがいくつかあるなと思ったら・・・
0559名無しさん@お腹いっぱい。
2020/10/21(水) 10:59:34.87UserAgentで弾いてる訳じゃなくて、ページの構成自体をIEが対応してない形式に変更したんじゃないの?
IE使ってないから確認できてないけど
0560名無しさん@お腹いっぱい。
2020/10/21(水) 18:00:01.04archive.is の拓が直接 archive.orgに取り込めない場合は少し前までなら anonymouse のWebプロキシのURL付けると取り込めたりしたが、
(例:http://anonymouse.org/cgi-bin/anon-www.cgi/http://e-words.jp/w/%E3%82%A2%E3%83%BC%E3%82%AB%E3%82%A4%E3%83%96.html で取り込む)
…今秋から archive.is へのアクセスが暗号通信( https://archive.is/XXXXX )強制にされてしまったんで不可になってしまった。
( anonymouse.は非暗号アクセス http:// のサイトにしか対応してない )
0561名無しさん@お腹いっぱい。
2020/10/21(水) 19:01:46.68きちんと保存されてたはずのものがされてないことに。
0562名無しさん@お腹いっぱい。
2020/10/21(水) 23:45:30.070563名無しさん@お腹いっぱい。
2020/10/22(木) 00:43:54.180564名無しさん@お腹いっぱい。
2020/10/22(木) 12:51:56.97まぁ話題が少ないからループするのはしょうがないけど
0565名無しさん@お腹いっぱい。
2020/10/22(木) 19:24:33.27ここのところあまりにもひどくてさ・・・
0566名無しさん@お腹いっぱい。
2020/10/23(金) 03:51:33.890567名無しさん@お腹いっぱい。
2020/10/23(金) 11:25:58.48もう定期イベントみたいなもの
0568名無しさん@お腹いっぱい。
2020/10/24(土) 22:48:06.960569名無しさん@お腹いっぱい。
2020/10/24(土) 23:09:23.020570名無しさん@お腹いっぱい。
2020/10/25(日) 01:01:50.220571名無しさん@お腹いっぱい。
2020/10/25(日) 01:34:37.40ってエラーメッセージが出ても、後で確認すると取れてることが多かったりする
0572名無しさん@お腹いっぱい。
2020/10/25(日) 12:49:20.360573名無しさん@お腹いっぱい。
2020/10/25(日) 13:16:13.93何を言ってるのか良く判らない、と良く言われるだろw
0574名無しさん@お腹いっぱい。
2020/10/25(日) 13:24:21.46メンテ中かな
0575名無しさん@お腹いっぱい。
2020/10/25(日) 13:29:27.09まさかのトップページで 500 エラーを返されたわw
0576名無しさん@お腹いっぱい。
2020/10/25(日) 14:45:08.36ちょっと前は20分、去年あたりは10分で良かったのに…
0577名無しさん@お腹いっぱい。
2020/10/25(日) 21:11:43.05Unknown Errorになった。
0578名無しさん@お腹いっぱい。
2020/10/25(日) 21:16:36.580579名無しさん@お腹いっぱい。
2020/10/25(日) 21:57:17.13Unknown Errorを繰り返すようになった
0580名無しさん@お腹いっぱい。
2020/10/26(月) 00:51:01.37Sorry
This URL is in our block list and cannot be captured. Please email us at "info@archive.org" if you would like to discuss this more.
会社のプレスリリースなどでcloudfront.net使ってるところは保存できなくなってるわ
0581名無しさん@お腹いっぱい。
2020/10/26(月) 17:19:48.9224日午後4時〜8時(日本時間25日午前8時〜12時頃)にサーバーダウンして4時間ほどページすら見れなかったらしい
0582名無しさん@お腹いっぱい。
2020/10/26(月) 19:05:44.020583名無しさん@お腹いっぱい。
2020/10/26(月) 21:03:32.400584名無しさん@お腹いっぱい。
2020/10/26(月) 23:46:49.93http://web.archive.org/web/20201024183048/https://pbs.twimg.com/card_img/1318252845452374016/A4POgMBd?format=jpg&name=600x314
上にも書いたけどアメブロの魚拓をとったんだよね
あとからチェックしたら魚拓自体はとれてたんだけどw謎杉
数日前から変なURLに飛ばされることがあるけど結果的に取れてるんだよ
0585名無しさん@お腹いっぱい。
2020/10/27(火) 00:07:16.71きもE
0586名無しさん@お腹いっぱい。
2020/10/27(火) 00:49:59.93よく分からん怪しいurlに飛ばされたりしてるな
0587名無しさん@お腹いっぱい。
2020/10/27(火) 01:26:19.05それここ何日か発生してるバグっぽい。
save nowで保存すると、そのページじゃなくて読み込まれるURLの1個が帰ってくる。
変なURLが帰ってくるとびっくりするけど一応保存はされてる模様。
0588名無しさん@お腹いっぱい。
2020/10/27(火) 01:28:05.490589名無しさん@お腹いっぱい。
2020/10/27(火) 02:13:12.17バグったり直ったりしていた
0590名無しさん@お腹いっぱい。
2020/10/27(火) 02:27:39.410591名無しさん@お腹いっぱい。
2020/10/27(火) 10:08:38.570592名無しさん@お腹いっぱい。
2020/10/29(木) 03:45:25.34またsave nowが混み始めたぞ
0593名無しさん@お腹いっぱい。
2020/10/29(木) 11:59:23.94https://security.srad.jp/story/20/10/25/1638251/
Noteに続き、今度はブクログのメルアド流出でbooklog.jpまるごとブロックか削除になったそう
0594名無しさん@お腹いっぱい。
2020/10/29(木) 16:27:01.750595名無しさん@お腹いっぱい。
2020/10/29(木) 17:39:46.40こんなしょうもない事でポンポン消されたらたまったもんじゃない
0596名無しさん@お腹いっぱい。
2020/10/29(木) 22:34:14.27URLが知りたいです。
0597名無しさん@お腹いっぱい。
2020/10/30(金) 02:14:44.13ざっと検索したらそれらしい情報は出てきたが、あなたの欲しい情報が入ってるかは分からん
IPLC Launches the Greater China Archival Resources Web Archive(Ivy Plus Libraries Confederation, 2020/9/9)
https://ivpluslibraries.org/2020/09/iplc-launches-the-greater-china-archival-resources-web-archive/
Greater China Archival Resources Web Archive(Archive-It)
https://archive-it.org/collections/14767
0598名無しさん@お腹いっぱい。
2020/10/30(金) 02:16:14.21まあ当然っちゃ当然かもしれないけど
0599名無しさん@お腹いっぱい。
2020/10/30(金) 09:30:17.93ありがとうございます!とても参考になりました。
0600名無しさん@お腹いっぱい。
2020/10/31(土) 21:34:11.67「インターネットアーカイブ」で検索しても1ページ目にすら出ないんだな
「internet archive」だとトップなのに
日本人はあんまり使ってないのかな・・・?
0601名無しさん@お腹いっぱい。
2020/10/31(土) 21:44:23.020602名無しさん@お腹いっぱい。
2020/11/01(日) 15:21:23.61グーグル使うの止めたら?
スマホファーストデザインやるようになったぐらいから、
そこらのアフィカスブログが可愛く見えるくらいアフィカス度激高になってるよグーグル
0603名無しさん@お腹いっぱい。
2020/11/05(木) 14:53:16.090604名無しさん@お腹いっぱい。
2020/11/05(木) 14:55:42.77アーカイブを消させるための手法として流用されるかも
下手すると第三者がこういった工作をする可能性も
0605名無しさん@お腹いっぱい。
2020/11/05(木) 16:20:41.640606名無しさん@お腹いっぱい。
2020/11/06(金) 13:29:44.23保存するなら今のうちだな
0607名無しさん@お腹いっぱい。
2020/11/06(金) 21:12:40.12diablo2ゲット
0608名無しさん@お腹いっぱい。
2020/11/07(土) 01:44:34.11こっそり楽しめ
0609名無しさん@お腹いっぱい。
2020/11/07(土) 10:41:21.23それで合っていると思う
試しにツールを使って、すでにその状態になっているものをここからダウンロードしようとしたら
「403 Forbidden」が出たから
だからまた見るにはインターネットアーカイブ側でアクセス許可にされるか
それともそれをかいくぐれるツールが出来るかのどっちかしか無いかも
0610名無しさん@お腹いっぱい。
2020/11/07(土) 14:46:43.61シリアルが画が画が
0611名無しさん@お腹いっぱい。
2020/11/10(火) 00:24:38.750612名無しさん@お腹いっぱい。
2020/11/11(水) 23:22:46.65日本時間で午後10時50分過ぎから鯖落ちしてる模様
0613名無しさん@お腹いっぱい。
2020/11/12(木) 02:34:24.000614名無しさん@お腹いっぱい。
2020/11/19(木) 10:57:43.270615名無しさん@お腹いっぱい。
2020/11/19(木) 13:48:19.340616名無しさん@お腹いっぱい。
2020/11/19(木) 16:14:02.210617名無しさん@お腹いっぱい。
2020/11/19(木) 23:46:06.930618名無しさん@お腹いっぱい。
2020/11/20(金) 04:16:43.66一昨日くらいにUnknown Error表示でまくりで放置してた分も依然そのままの状態で取れない
なんだかうまく取れたらクリアってゲームやってる気がしてきた・・・
0619名無しさん@お腹いっぱい。
2020/11/20(金) 08:15:01.590620名無しさん@お腹いっぱい。
2020/11/20(金) 08:19:32.56変なURLが帰ってくるのは>>582-589で出てるバグなら気にしなくて大丈夫だよ
https://web.archive.org/web/*/の後ろにURLつけて確認してみ
0621名無しさん@お腹いっぱい。
2020/11/20(金) 21:31:52.70おま環?
0622名無しさん@お腹いっぱい。
2020/11/21(土) 14:12:11.95Archiveteamにwiki専門のグループがあるからそのIRCで頼めば保存してもらえるかも
以前別件でコンタクト取ったときに向こうから保存したい日本のwikiはないかって尋ねてきたこともあるくらいだから積極的に動いてくれると思う
https://archiveteam.org/index.php?title=WikiTeam
0623名無しさん@お腹いっぱい。
2020/11/21(土) 20:01:45.32何年も前から取ってるページなのに2020年7月からしかないとか変だわ
0624名無しさん@お腹いっぱい。
2020/11/21(土) 23:16:26.36一時的に一部データが閲覧できない場合もあるからな
0625名無しさん@お腹いっぱい。
2020/11/22(日) 01:23:53.80https://asahi.5ch.net/test/read.cgi/newsplus/1605969388/l50
0626名無しさん@お腹いっぱい。
2020/11/23(月) 22:59:21.80メニューがFlashのサイトとかナビゲーションさえできなくなっちゃうからな
0627名無しさん@お腹いっぱい。
2020/11/26(木) 06:49:26.37ダメなら時間おくしかない
0628名無しさん@お腹いっぱい。
2020/11/29(日) 12:26:24.57ちょっと前までは出なかったのに
0629名無しさん@お腹いっぱい。
2020/11/29(日) 13:46:55.470630名無しさん@お腹いっぱい。
2020/11/29(日) 15:50:01.950631名無しさん@お腹いっぱい。
2020/11/29(日) 16:02:24.61残念ながらそのバグではない。
クッキー無いとリダイレクト失敗する仕様になっているぽい
0632名無しさん@お腹いっぱい。
2020/12/01(火) 10:52:52.7520秒ぐらいで保存が終わってタイムアウトも1割ぐらい
タイムアウトでもちゃんと保存されてるし、画像やスクリプト込みでこの時間だから、
以前より早いかも
(100個も画像やスクリプトあるページは無理だが)
0633名無しさん@お腹いっぱい。
2020/12/04(金) 23:38:28.47一ヶ月前のUnknown Error保存分をチェックしてみたら
日付だけ表示されたが中身は保存されてないようだ
0634名無しさん@お腹いっぱい。
2020/12/05(土) 16:22:36.310635名無しさん@お腹いっぱい。
2020/12/05(土) 17:14:55.42Job failed
0636名無しさん@お腹いっぱい。
2020/12/06(日) 13:21:09.09今日2回目の保存なのにこのエラーが出るとか、ふざけすぎでしょw
0637名無しさん@お腹いっぱい。
2020/12/06(日) 13:23:29.09active sessionsだからサイト全体のセッション数の制限を超えてるということかもしれないが
0638名無しさん@お腹いっぱい。
2020/12/06(日) 19:32:55.17host規制かそのサイトだけ取れないように規制されてるかじゃね知らんけど
0639名無しさん@お腹いっぱい。
2020/12/06(日) 23:36:07.44200ページほど/save/で保存した結果、平均3〜5回このエラー出るわ
保存されてないのでエラー出たURLだけやり直し
0640名無しさん@お腹いっぱい。
2020/12/07(月) 10:35:04.56ぶっちゃけ寄付してなきゃ規制されてても不思議じゃないよ、それ
無料に毒されすぎじゃない?
広告大量になったり、変なスクリプトで経費賄うようになったら嫌だなー
0641名無しさん@お腹いっぱい。
2020/12/07(月) 17:09:05.18寄付しろってのはそう
0642名無しさん@お腹いっぱい。
2020/12/07(月) 17:39:59.480643名無しさん@お腹いっぱい。
2020/12/07(月) 21:09:46.970644名無しさん@お腹いっぱい。
2020/12/07(月) 23:07:54.270645名無しさん@お腹いっぱい。
2020/12/08(火) 18:52:05.480646名無しさん@お腹いっぱい。
2020/12/08(火) 22:29:27.530647名無しさん@お腹いっぱい。
2020/12/09(水) 10:26:17.35大量にリクエストしたら通常よりも大きな負荷がかかるかもしれない、くらいのことは想像つかないのかよ
やるならせめて寄付くらいはしろ
0648名無しさん@お腹いっぱい。
2020/12/09(水) 10:29:24.14どのような形であれ大量アクセスはInternet Archiveにとって困るってことの証拠じゃないの
0649名無しさん@お腹いっぱい。
2020/12/09(水) 13:07:12.73自制が効かない・寄付もしないゴミに目を付けられたサービスが改悪しまくるのは分かりきってる
0650名無しさん@お腹いっぱい。
2020/12/09(水) 14:19:34.60間隔短すぎだから間隔を30秒にしろ。
0651名無しさん@お腹いっぱい。
2020/12/09(水) 15:04:53.490652名無しさん@お腹いっぱい。
2020/12/09(水) 15:26:57.330653名無しさん@お腹いっぱい。
2020/12/09(水) 15:52:40.470654名無しさん@お腹いっぱい。
2020/12/09(水) 17:22:41.08/save/にリクエスト送るだけ
0655名無しさん@お腹いっぱい。
2020/12/09(水) 17:52:48.98HTTP通信さえ出来るツール使えばcurlじゃなくて問答無用で自動化できる
でも下手に叩きすぎてサーバ圧迫して結果制限が厳しくなったら元も子もないから、俺はやった事ない
0656名無しさん@お腹いっぱい。
2020/12/09(水) 17:53:20.920657名無しさん@お腹いっぱい。
2020/12/09(水) 19:40:19.27これで合ってる?
0658名無しさん@お腹いっぱい。
2020/12/09(水) 21:53:36.06すまんけど何を聞こうとしてるのかよく分からん
その質問って結局「ひとつのサイト全体を自分で保存する機能は提供されてないよ」って事以外何も言ってないように見えるけど
0659名無しさん@お腹いっぱい。
2020/12/09(水) 21:56:26.36少なくとも静的サイトはこの方法で行けるね、wgetのmirrorオプションでURLリストを作るとは上手いこと考えたな
0660名無しさん@お腹いっぱい。
2020/12/09(水) 22:01:16.11この回答の方法ではあらゆる種類のサイトを保存することはできない
でもHTMLとCSSだけで頑張ってるような昔の個人サイトなら問題ない
0661名無しさん@お腹いっぱい。
2020/12/11(金) 02:53:02.336ページ目以上は保存処理が終わってないのが残ってると、タイムアウトになって保存されないよ。
自動化以前にウェブサーフィン(死語)中、手動でブラウザから/save/開いて保存したい時でも、状況は同じ。
今はこの制限内でやればいいだけ。
0662名無しさん@お腹いっぱい。
2020/12/12(土) 02:57:25.07> avoid trying to send many thousands URLs; there's Archivebot for that
https://archiveteam.org/index.php?title=Internet_Archive
archive bot
https://archiveteam.org/index.php?title=ArchiveBot
0663名無しさん@お腹いっぱい。
2020/12/15(火) 21:01:34.37ttps://i.imgur.com/7Jip0Y5.png
0664名無しさん@お腹いっぱい。
2020/12/15(火) 21:02:45.84This snapshot cannot be displayed due to an internal error.
さっき初めて出た、保存はされてるがエラーで表示できないという謎のエラー
0665664
2020/12/15(火) 21:04:28.300666名無しさん@お腹いっぱい。
2020/12/15(火) 23:57:41.060667名無しさん@お腹いっぱい。
2020/12/16(水) 06:37:15.41なんかバグってるんだよね
0668名無しさん@お腹いっぱい。
2020/12/16(水) 17:34:12.890669名無しさん@お腹いっぱい。
2020/12/16(水) 20:02:08.13https://chrome.google.com/webstore/detail/magic-viewer-for-chrome/npkhecbdgglnkjjaiojienebokcjbgmi?hl=ja
chromeの拡張機能を入れて、右クリックして、「すべての画像を見る」をクリックすると外部リンクの画像が自動でアーカイブされる。
サイトによっては、ブラウザのページを数回、再読み込みをする。
0670名無しさん@お腹いっぱい。
2020/12/17(木) 04:44:35.32最近はSave Page Nowコレクション扱いになってるな
10月ぐらいからファイルが増えてないし、Live Web Proxyって引退したのかもしれない
https://archive.org/details/liveweb?sort=-addeddate
このスレでも10月はエラー多かった書き込みあったしな、移行期間だったのだろう
0671名無しさん@お腹いっぱい。
2020/12/17(木) 10:47:26.64取れてる取れてないの繰り返しにはうんざり
どこが運営してるのかわからないのは限りなく不安だが
もうarchive.todayしかない
0672名無しさん@お腹いっぱい。
2020/12/17(木) 16:01:59.780673名無しさん@お腹いっぱい。
2020/12/17(木) 16:39:47.92システムいじくってる最中で保存されてないものもあるかもな
0674名無しさん@お腹いっぱい。
2020/12/17(木) 17:05:10.840675名無しさん@お腹いっぱい。
2020/12/17(木) 21:53:46.160676名無しさん@お腹いっぱい。
2020/12/17(木) 23:36:55.01スポーツ新聞アーカイブしてるとは一言も言ってないし同一人物とは限らんよ
毎日適当なページを実験用に保存し続けてInternet Archiveの挙動をテストしてる人もいたはずだし
0677名無しさん@お腹いっぱい。
2020/12/18(金) 00:36:49.290678名無しさん@お腹いっぱい。
2020/12/18(金) 01:28:46.930679名無しさん@お腹いっぱい。
2020/12/18(金) 01:47:52.99偏見すぎ
0680名無しさん@お腹いっぱい。
2020/12/19(土) 23:30:14.53ttpではなく、httpに修正して
saveではなく、エラー軽減のため西暦の数字で
連番の数字で自動保存される。
0681名無しさん@お腹いっぱい。
2020/12/20(日) 03:27:16.25これじゃしばらく試行しながら様子見するしかねえな
0682名無しさん@お腹いっぱい。
2020/12/24(木) 21:46:55.38ばっか表示される
0683名無しさん@お腹いっぱい。
2020/12/25(金) 04:04:48.90APIがぶっ壊れたのか。
0684名無しさん@お腹いっぱい。
2020/12/25(金) 22:32:48.69以後同一ページを保存してもずっとHrmになってしまう状況が11月から続いている
0685名無しさん@お腹いっぱい。
2020/12/26(土) 02:55:00.36専門家のブログのコピー記事だからブロックしてるのかな
Sorry
This URL is in our block list and cannot be captured. Please email us at "info@archive.org" if you would like to discuss this more.
0686名無しさん@お腹いっぱい。
2020/12/26(土) 07:23:35.18繰り返される悲劇はもうウンザリだ 「右直事故」防止に切り札はあるのか!?(佐川健太郎) - 個人 - Yahoo!ニュース
http://web.archive.org/web/20201219152606/https://news.yahoo.co.jp/byline/sagawakentaro/20201219-00213273/
0687名無しさん@お腹いっぱい。
2020/12/26(土) 11:36:52.53archive.org ? ウェブサイト全体をアーカイブする方法は?
http://web.archive.org/web/20201220090718/https://www.it-swarm-ja.tech/ja/archive.org/%E3%82%A6%E3%82%A7%E3%83%96%E3%82%B5%E3%82%A4%E3%83%88%E5%85%A8%E4%BD%93%E3%82%92%E3%82%A2%E3%83%BC%E3%82%AB%E3%82%A4%E3%83%96%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%E3%81%AF%EF%BC%9F/965342469/
0688名無しさん@お腹いっぱい。
2020/12/26(土) 17:10:27.56これArchive Teamが保存したものをWayback Machineに移管したやつだね
Save Page Nowでは取れないけど、外部の人間が取ったものを移管したから結果的に取れてるように見えてる
0689名無しさん@お腹いっぱい。
2020/12/30(水) 16:01:54.230690名無しさん@お腹いっぱい。
2020/12/30(水) 17:30:24.610691名無しさん@お腹いっぱい。
2021/01/02(土) 23:03:35.16放置しとくと日付だけ表示されるHrmのまま
0692名無しさん@お腹いっぱい。
2021/01/03(日) 14:23:02.240693名無しさん@お腹いっぱい。
2021/01/04(月) 09:24:29.97正確な発音はわからん
0694名無しさん@お腹いっぱい。
2021/01/04(月) 21:44:38.490695名無しさん@お腹いっぱい。
2021/01/07(木) 05:03:25.08Collectionsのところ見たけど、Focused CrawlsとTop DomainsはArchive Teamが収集してるものじゃないよ
ブロックされているURLも移管してるのはそういう仕組みだろうけど
ヤフージャパンはアクセス数多いドメインとはいえ、ニュース系のページは収集してくれないんだなぁ
0696名無しさん@お腹いっぱい。
2021/01/07(木) 13:28:13.11ただ一部の記事で何故かBlockListエラーが出る
理由は謎(メールすれば聞けるのかもしれないけど)
0697名無しさん@お腹いっぱい。
2021/01/07(木) 13:35:08.850698名無しさん@お腹いっぱい。
2021/01/07(木) 14:27:18.780699名無しさん@お腹いっぱい。
2021/01/07(木) 16:30:50.05今日はこればっかり
0700名無しさん@お腹いっぱい。
2021/01/08(金) 02:00:41.100701名無しさん@お腹いっぱい。
2021/01/08(金) 10:11:43.260702名無しさん@お腹いっぱい。
2021/01/09(土) 00:15:31.320703名無しさん@お腹いっぱい。
2021/01/09(土) 04:00:24.160704名無しさん@お腹いっぱい。
2021/01/09(土) 11:27:19.350705名無しさん@お腹いっぱい。
2021/01/09(土) 11:47:42.840706名無しさん@お腹いっぱい。
2021/01/09(土) 16:52:25.910707名無しさん@お腹いっぱい。
2021/01/09(土) 21:56:53.820708名無しさん@お腹いっぱい。
2021/01/11(月) 04:45:59.100709名無しさん@お腹いっぱい。
2021/01/11(月) 13:33:23.25その割にサーバーはザコだが
0710名無しさん@お腹いっぱい。
2021/01/12(火) 10:01:11.500711名無しさん@お腹いっぱい。
2021/01/14(木) 08:53:53.82This URL has been already captured 10 times today. Please email us at "info@archive.org" if you would like to discuss this more.
これは今日10回じゃなくて過去24時間に10回の文間違いじゃないの
内容が変わりまくるサイトを保存できなくなった
0712名無しさん@お腹いっぱい。
2021/01/14(木) 11:03:11.230713名無しさん@お腹いっぱい。
2021/01/14(木) 15:57:48.45サイト側にとって未定義のパラメーターなら大抵のサイトはパラメーターなしと同じものを返してくるだろう。
0714名無しさん@お腹いっぱい。
2021/01/14(木) 22:53:43.100715名無しさん@お腹いっぱい。
2021/01/15(金) 05:48:54.800716名無しさん@お腹いっぱい。
2021/01/15(金) 05:50:45.57随分遠回りなことしてるように見えても本人にとっては大事なんだろ、ほっとけ
0717名無しさん@お腹いっぱい。
2021/01/16(土) 00:22:05.68ってあるんだから
ここで愚痴言うくらいならメール送ったらいいんじゃない?
0718名無しさん@お腹いっぱい。
2021/01/16(土) 16:38:22.29アーカイブされたページを全文検索できるようになるまで、
あと何年くらいかかると思いますか?
0719名無しさん@お腹いっぱい。
2021/01/16(土) 20:12:08.580720名無しさん@お腹いっぱい。
2021/01/17(日) 00:21:40.840721名無しさん@お腹いっぱい。
2021/01/18(月) 13:51:31.62これって保存できてるの?
0722721
2021/01/18(月) 15:47:47.92マッピングが届いてないとかそんな感じっぽい。
0723名無しさん@お腹いっぱい。
2021/01/21(木) 23:18:29.78Live page is not available: chrome-error://chromewebdata/
0724名無しさん@お腹いっぱい。
2021/01/22(金) 15:38:58.53あんま使ってなかったからいいけどさ
0725名無しさん@お腹いっぱい。
2021/01/22(金) 16:01:35.20今見たら復活してた
タイミングが悪かっただけかな
0726名無しさん@お腹いっぱい。
2021/01/22(金) 16:51:49.89遅れてるだけなのかこれ
0727名無しさん@お腹いっぱい。
2021/01/22(金) 22:31:31.69Internet Archive サービス終了までに実現できると思う?
いくら遅くてもいいけど
0728名無しさん@お腹いっぱい。
2021/01/24(日) 01:33:05.610729名無しさん@お腹いっぱい。
2021/01/24(日) 04:31:27.21ここに載ってる、savepagenow@archive.orgに他人から来たメールをFwdで送ったら
URLを抽出して保存された後に保存済URLが返ってくるのって今も機能してるのか?
メールが返ってこないんだが
ブログ記事の数日後に書かれたコメント欄の時点でメール返ってこねぇって書いてる人いるけども
0730名無しさん@お腹いっぱい。
2021/01/24(日) 14:34:02.42英語での交渉が得意な人しか使えないじゃん
0731名無しさん@お腹いっぱい。
2021/01/24(日) 19:17:01.62今時DeepLあたりでも使えばそこまで英語で苦戦することは無いよ
というか英語圏のボランティア団体なんだからこちらが英語に合わせるのは当然のことじゃない?
0732名無しさん@お腹いっぱい。
2021/01/24(日) 19:18:46.98まあそうなったとしても誰かが英語で本部とやり取りしないといけない訳だからあんまり意味無いけど
0733名無しさん@お腹いっぱい。
2021/01/25(月) 09:13:54.98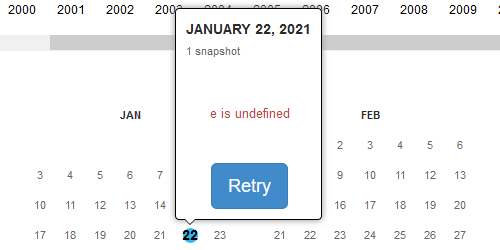
0734名無しさん@お腹いっぱい。
2021/01/25(月) 10:13:47.99>>721-722
反映を待ってればいい、ダメならもう一度撮り直すしかない
0735名無しさん@お腹いっぱい。
2021/01/25(月) 20:24:16.530736名無しさん@お腹いっぱい。
2021/01/26(火) 20:37:45.840737名無しさん@お腹いっぱい。
2021/02/07(日) 15:31:24.66そもそもエラーだったから取り直してるのはカウントすんなよ
0738名無しさん@お腹いっぱい。
2021/02/14(日) 16:09:56.27前にとってから10時間以上経つのに取れない
0739名無しさん@お腹いっぱい。
2021/02/15(月) 17:54:43.88やっぱり丸一日経たないと同じurlのアーカイブ取得出来なくなってるっぽい 全てのurlかどうかは不明
0740名無しさん@お腹いっぱい。
2021/02/15(月) 19:35:35.74>>739
毎日保存してるのに24時間以上たたないと保存できないのは困る
----------
> このサイトにアクセスできませんweb.archive.org で接続が拒否されました。
> ERR_CONNECTION_REFUSED
保存しすぎて個人的に Web.archive.org にアクセス拒否されたかと思ったw
Down for Everyone or Just Me
https://downforeveryoneorjustme.com/web.archive.org
> Web.archive.org Status
> Is web.archive.org down right now?
> It's not just you! web.archive.org is down.
0741名無しさん@お腹いっぱい。
2021/02/15(月) 19:36:14.630742名無しさん@お腹いっぱい。
2021/02/15(月) 19:40:02.46その表示初めて見るけどブラウザ何使ってる?
0743名無しさん@お腹いっぱい。
2021/02/15(月) 19:52:03.700744名無しさん@お腹いっぱい。
2021/02/15(月) 20:02:02.56Google Chrome
https://i.imgur.com/xmvdeg3.png
0745名無しさん@お腹いっぱい。
2021/02/15(月) 20:18:19.09鯖が死んでるわ。
0746名無しさん@お腹いっぱい。
2021/02/15(月) 21:30:42.260747名無しさん@お腹いっぱい。
2021/02/15(月) 22:21:55.650748名無しさん@お腹いっぱい。
2021/02/15(月) 22:24:25.210749名無しさん@お腹いっぱい。
2021/02/15(月) 23:18:16.36保存もできるよ
0750名無しさん@お腹いっぱい。
2021/02/15(月) 23:21:29.92まだ完全復活できてない模様
0751名無しさん@お腹いっぱい。
2021/02/16(火) 01:10:12.48てかIAは鯖落ちしようが何も言わない
サンフランシスコ時間で朝になったから、今日も@internetarchiveは更新を始めたようだが、
いつも通りだんまりだね。4時間近く止まってたんだから一言欲しいけど
0752名無しさん@お腹いっぱい。
2021/02/16(火) 02:53:38.24そこにメールしても返信すらないから意味ないよ
送っても誰もメール見てないんじゃね
0753名無しさん@お腹いっぱい。
2021/02/16(火) 10:22:33.21せめて落ちてるときは今落ちてるよ的なのを返して欲しい
0754名無しさん@お腹いっぱい。
2021/02/16(火) 22:20:35.70午前中に技術的な問題が発生
https://twitter.com/internetarchive/status/1361454580869947395
鯖落ちは一時的なバグが原因
https://twitter.com/5chan_nel (5ch newer account)
0755名無しさん@お腹いっぱい。
2021/02/17(水) 23:26:58.40ttps://current.ndl.go.jp/node/43304
0756名無しさん@お腹いっぱい。
2021/02/19(金) 13:11:41.550757名無しさん@お腹いっぱい。
2021/02/19(金) 18:11:43.08APIの反映も遅いし
0758名無しさん@お腹いっぱい。
2021/02/19(金) 22:14:59.500759名無しさん@お腹いっぱい。
2021/02/20(土) 20:16:11.82internal server errorは一応されてるみたいだけど
0760名無しさん@お腹いっぱい。
2021/02/21(日) 09:59:06.840761名無しさん@お腹いっぱい。
2021/02/21(日) 13:11:02.40ということは内部的には取れてるのか・・・?よく分からん
0762名無しさん@お腹いっぱい。
2021/02/22(月) 14:27:20.34なんやこれ
0763名無しさん@お腹いっぱい。
2021/02/24(水) 15:46:58.89上でも書いてる人いるけど、多分保存できてないと思う
最新から10個前の保存時間から24時間経たないとできない
0764名無しさん@お腹いっぱい。
2021/02/25(木) 00:31:49.910765名無しさん@お腹いっぱい。
2021/02/25(木) 14:27:18.940766名無しさん@お腹いっぱい。
2021/02/27(土) 10:54:16.04Our team has been notified.
これしか表示されなくなった
完全にぶっ壊れてる
0767名無しさん@お腹いっぱい。
2021/02/27(土) 21:12:05.690768名無しさん@お腹いっぱい。
2021/02/28(日) 11:46:27.82試しにcurlで/save/から保存するのと同時に、WebブラウザからVPN使って別のIPアドレスにした上でSPNで別のサイトを保存してみたら、
curlで保存中の画像やJavascriptのアドレスがWebブラウザの方に出てきてしまった。
普通に情報流出していてワロタ
このスレでも他人のアドレスが出てくる状態になった報告があるみたいだけど、直す気ないのかな。マジで直したほうがいいと思う。
>>568-570
>>584-589
0769名無しさん@お腹いっぱい。
2021/03/01(月) 20:37:48.02archive.todayで、
インスタグラムを保存できなくなってるの 俺だけ?
2週間くらい前までは、インスタグラム保存できてたのに。
他に インスタグラムを保存できる魚拓サイトありますか?
0770名無しさん@お腹いっぱい。
2021/03/01(月) 23:25:20.89それを介して保存するって方法がある
URLをしっかり記録しておかないと参照できなくなるってのが面倒だけど
0771名無しさん@お腹いっぱい。
2021/03/02(火) 14:01:49.74保存出来た時に表示されるリンクをクリック
→二月中旬に保存したものに飛ぶ
カレンダーを見ると3月2日に保存マークがある
→それをクリックすると二月中旬に保存したものに飛ぶ
これって3月2日に保存は出来たけど閲覧できない状態ということ?
0772名無しさん@お腹いっぱい。
2021/03/03(水) 13:37:44.10>インスタビューア的な外部サイトがいくつもあるから
>それを介して保存するって方法がある
回答 ありがとうございます。
「インスタビューア的な外部サイト」でググっていますが、見つかりませんorz。
ちなみにパソコン ユーザーです。
保存ができる、おすすめのインスタビューア的な外部サイトを教えていただければ幸いです。m(_ _)m
0773名無しさん@お腹いっぱい。
2021/03/03(水) 15:26:40.68ttps://archive.org/post/1105471/pages-refusing-to-save-this-is-asinine
Poster: Hitsmello Date: Nov 29, 2020 10:39am
Also, lately, I've noticed that the "Job failed" only seems to happen if I check the "Save outlinks" AND the "Please email me the results" boxes.
It WILL save properly if I just check "Save also in my web archive" and "Save outlinks". Gee, I wonder why...
ログインしてSave outlinksとPlease email me the resultsにチェックを入れるとjob failedが出ずに保存できるらしい
俺はアカウントから保存して、ファイルに名前が残るのはやだから、試してないけど
0774名無しさん@お腹いっぱい。
2021/03/03(水) 15:31:00.65反映待ち状態になってるから、数日後に見れるようになったか確認してみて
大抵は24時間、遅くても2日以内に見れるようになるはず
急いでるか保存失敗してそうなら、同じURLなら30分後以降にまた保存できるので再度保存するのもあり
0775名無しさん@お腹いっぱい。
2021/03/03(水) 18:22:54.32同じURLで連続10回保存失敗した場合でもこのエラーが出る。
失敗してるのにこれはないだろ。capturedできてねーぞ。
0776名無しさん@お腹いっぱい。
2021/03/03(水) 20:33:32.32instagram viewerとかでググって出てきたサイトに投稿を表示させて、その内容を保存するってこと
サイトによって表示される情報量がまちまちだから色々試して使いやすいのを探す必要がある
(例) プロフィール画面
https://web.archive.org/web/20210303101254/https://instastory.net/profile/cristiano
(例) 投稿画面
https://web.archive.org/web/20210303090845/https://instastory.net/post/CL7sxQPgvB6
可能な限りは公式サイトを保存したいところだけど
どうしても無理ならこうするしかないんじゃないかな
0777名無しさん@お腹いっぱい。
2021/03/04(木) 17:47:00.700778名無しさん@お腹いっぱい。
2021/03/05(金) 04:44:26.900779名無しさん@お腹いっぱい。
2021/03/05(金) 16:53:21.35ttps://webapps.stackexchange.com/a/151360
自動翻訳かけても読む価値あると思う
Save Page Now 2 Public API Docs Draft
https://docs.google.com/document/d/1Nsv52MvSjbLb2PCpHlat0gkzw0EvtSgpKHu4mk0MnrA/edit
https://docs.google.com/document/d/19RJsRncGUw2qHqGGg9lqYZYf7KKXMDL1Mro5o1Qw6QI/edit
Limitationsのところに制限について書いてあるのを拾ってみると
・同じIPアドレスから同時に6ページ以上SPNや/save/で保存すると自動でエラーになる
・10秒でレスポンス戻ってこなかったらタイムアウト
・50秒で保存先URLはタイムアウト
・spn@archive.org宛に保存したいURLのメールを送ると500個まで保存してくれる(俺の経験上結果がエラーだらけになる可能性大なので確実に保存したいなら手動で)
・ログインしてない同じIPアドレスから画像なども含めて1日2万ページ以上は保存リクエストだせない、ログインしてれば制限なし
・ログインしてAPIキーを取得すれば、プログラムから保存するのもできる
この制限に引っかからないようにすれば、大量保存してる人はうまくいくはず
サンプルコードにも失敗したら保存を繰り返すようなコードになってるから、保存エラーが多いのは認識してるんだろう
0780名無しさん@お腹いっぱい。
2021/03/05(金) 16:59:20.94IAにログインした上で、Googleスプレットシートに保存したいURLを並べて登録すると保存してくれるサービス
https://archive.org/services/wayback-gsheets
0781名無しさん@お腹いっぱい。
2021/03/05(金) 18:13:28.08ありがとうございます。上手くいきました
0782名無しさん@お腹いっぱい。
2021/03/05(金) 19:51:34.90スナップショット等への反応が即時でないが
0783名無しさん@お腹いっぱい。
2021/03/05(金) 20:16:22.56カレンダーで確かに今日の日付で保存されてるのにそこをクリックしても過去に保存されたページしか出ない
first archiveの場合は成功しましたのリンククリックしても保存されてないになっちゃう
0784名無しさん@お腹いっぱい。
2021/03/05(金) 21:10:51.470785名無しさん@お腹いっぱい。
2021/03/06(土) 02:15:27.01思ってたより全然神サービスだったわありがてー
0786名無しさん@お腹いっぱい。
2021/03/06(土) 17:13:17.16これが一番腹立つ
0787名無しさん@お腹いっぱい。
2021/03/07(日) 17:50:27.080788名無しさん@お腹いっぱい。
2021/03/09(火) 01:33:30.800789名無しさん@お腹いっぱい。
2021/03/09(火) 01:45:34.00気分屋だなあ
0790名無しさん@お腹いっぱい。
2021/03/09(火) 21:49:05.86今回はgoogle系ばかり
0791名無しさん@お腹いっぱい。
2021/03/10(水) 07:27:06.81https://scholar.archive.org/
Sci-Hubキラーになるかwww
0792名無しさん@お腹いっぱい。
2021/03/10(水) 21:05:30.750793名無しさん@お腹いっぱい。
2021/03/10(水) 21:12:27.070794名無しさん@お腹いっぱい。
2021/03/10(水) 21:25:03.54なるほど しばらく待てば直るものか?
0795名無しさん@お腹いっぱい。
2021/03/10(水) 22:53:02.34Save Page Now から保存を完了した後に表示される Visit page のリンク先が
保存したページそのもののアーカイブではなく、
その中の画像だったりスクリプトだったりのアーカイブになることがあるんだよね。
これも一連の異常と関係してるのかな。
0796名無しさん@お腹いっぱい。
2021/03/11(木) 00:11:38.240797名無しさん@お腹いっぱい。
2021/03/11(木) 13:41:23.280798名無しさん@お腹いっぱい。
2021/03/11(木) 15:47:38.66その通り…保存できてなくて困ってるよ
0799795
2021/03/11(木) 15:57:13.93確かに保存完了直後には見られないことがあっても、数時間〜数日後には表示できている。
保存完了画面のリンクが別のファイルを指しているので、実際に見てみるには
URL を入れ直さなきゃならないという点は何とかしてほしいと思う。
0800名無しさん@お腹いっぱい。
2021/03/11(木) 17:54:51.720801名無しさん@お腹いっぱい。
2021/03/11(木) 18:44:03.64教えてくれてありがとう
0802名無しさん@お腹いっぱい。
2021/03/12(金) 02:59:00.85例えばある人のfc2ブログの記事を保存したら帰ってきたのはそのページで読み込まれるcssやjsファイルだったし
0803名無しさん@お腹いっぱい。
2021/03/13(土) 18:56:41.680804名無しさん@お腹いっぱい。
2021/03/13(土) 22:35:06.61物事をきちんと説明できない池沼が騒いでいただけなのか?
0805名無しさん@お腹いっぱい。
2021/03/15(月) 00:54:48.12池沼呼ばわりとはどういう了見かな?
0806名無しさん@お腹いっぱい。
2021/03/15(月) 08:05:56.29行先の違うリンクを確認もせずにクリックして、勝手に飛んで行ったのであっても、
チョンにとっては「自分は常に正しい、悪いのは他人」ですから
飛ばされたことになっちゃうんですよ。
0807名無しさん@お腹いっぱい。
2021/03/15(月) 11:07:06.87ページが存在するのにLive page is not availableが出たりするし
0808名無しさん@お腹いっぱい。
2021/03/15(月) 15:13:50.78まあ今はあの現象は直ってるようだがな
0809名無しさん@お腹いっぱい。
2021/03/18(木) 01:41:28.070810名無しさん@お腹いっぱい。
2021/03/18(木) 09:04:58.590811名無しさん@お腹いっぱい。
2021/03/20(土) 19:27:34.980812イモー虫
2021/03/22(月) 04:29:32.07ガラケーからだけエラーが頻発かと思えば違うんだね
0813名無しさん@お腹いっぱい。
2021/03/24(水) 20:24:38.950814名無しさん@お腹いっぱい。
2021/03/27(土) 19:47:08.190815名無しさん@お腹いっぱい。
2021/04/01(木) 09:36:27.490816名無しさん@お腹いっぱい。
2021/04/02(金) 14:14:32.260817名無しさん@お腹いっぱい。
2021/04/04(日) 15:52:25.36攻略サイト保存したらちゃんと階層や画像も一括でまとめてzipでDL出来んの?
0818名無しさん@お腹いっぱい。
2021/04/05(月) 16:29:25.73このサイト使うとtwitterの動画保存できる
0819名無しさん@お腹いっぱい。
2021/04/07(水) 05:09:08.66いきなりロードされて保存済みページが表示されたりがあるな
0820名無しさん@お腹いっぱい。
2021/04/16(金) 00:59:24.77ブロックリストに入れるような記事かこれ?
This URL is in our block list and cannot be captured.
Please email us at "info@archive.org" if you would like to discuss this more.
0821名無しさん@お腹いっぱい。
2021/04/16(金) 05:40:19.79主にコロナ関連で
0822名無しさん@お腹いっぱい。
2021/04/16(金) 07:10:27.48yahooなら大抵二次なので一次ソースをたどってそっちを保存
0823名無しさん@お腹いっぱい。
2021/04/16(金) 10:12:44.290824名無しさん@お腹いっぱい。
2021/04/16(金) 17:12:55.380825名無しさん@お腹いっぱい。
2021/04/17(土) 09:24:30.320826名無しさん@お腹いっぱい。
2021/04/17(土) 11:41:17.370827名無しさん@お腹いっぱい。
2021/04/19(月) 11:42:38.280828名無しさん@お腹いっぱい。
2021/04/20(火) 01:48:29.850829名無しさん@お腹いっぱい。
2021/04/20(火) 16:17:10.58うちウェブ魚拓いくら待ってもロボット拒否でbanされたわw
0830名無しさん@お腹いっぱい。
2021/04/20(火) 21:36:13.880831名無しさん@お腹いっぱい。
2021/04/21(水) 21:20:44.52Web魚拓はReCaptchaのマークが右下に表示されてから12秒くらい待ってボタン押すと保存できるはず。
長く待ちすぎるとロボット拒否される
0832名無しさん@お腹いっぱい。
2021/04/21(水) 23:45:37.520833名無しさん@お腹いっぱい。
2021/04/22(木) 21:24:08.86このスレ見てる誰かがスクリプトでも走らせてるのか
0834名無しさん@お腹いっぱい。
2021/04/23(金) 17:18:11.690835名無しさん@お腹いっぱい。
2021/04/25(日) 18:05:22.970836名無しさん@お腹いっぱい。
2021/04/30(金) 13:23:56.96二ヶ月前はこんなこと無かったのに
0837名無しさん@お腹いっぱい。
2021/04/30(金) 13:34:48.94Gravatarを参照しなくなった
画像のタイムスタンプからして先月初旬の変更か
https://archive.org/images/person2.png
Last-Modified: Sun, 07 Mar 2021 00:42:48 GMT
0838名無しさん@お腹いっぱい。
2021/04/30(金) 18:23:16.44ちょっと違うけど20年近く続いてる個人サイトとか、あとベテラン作家のブログが保存されてたのにサイトの方は自分が作業するまでアーカイブに無かったってことはあったな
(後者は今のサイトが出来てから2年ぐらいしか経ってなかったのもあるんだろうけど)
0839名無しさん@お腹いっぱい。
2021/04/30(金) 21:42:19.54ユーザーページは取られてないけど個別のツイートは殆ど取られてるはず
0840名無しさん@お腹いっぱい。
2021/05/03(月) 02:26:37.760841名無しさん@お腹いっぱい。
2021/05/04(火) 08:19:29.48https://www.jtm.gr.jp/technote/chrome/check-my-links/
0842名無しさん@お腹いっぱい。
2021/05/04(火) 22:21:00.51Stay up to date with what’s happening at the Internet Archive by signing up for our free newsletters.
□ Best of the Archive: Useful resources, unique stories, and fun finds from our collections
□ Monthly Updates: A snapshot of the main news stories about the archive each month
□ Event Notices: Invitations to and news about our events
□ Donor Communications: Messages for and about our generous supporters
どれも要らないけどw
0843名無しさん@お腹いっぱい。
2021/05/05(水) 11:05:32.130844名無しさん@お腹いっぱい。
2021/05/05(水) 21:50:33.16インスタはちょっと前から出来なくなった
個別の画像URLを抽出して保存は出来る
0845名無しさん@お腹いっぱい。
2021/05/06(木) 13:16:03.430846名無しさん@お腹いっぱい。
2021/05/07(金) 09:48:31.47後から取られてるんだろうか?
0847イモー虫
2021/05/07(金) 16:22:46.45https●:●//www.●instagram.●com/p/11桁のインスタ画像個別の英数/media/?size=l
0848名無しさん@お腹いっぱい。
2021/05/07(金) 18:40:26.38裏で取れてたりするんかね
0849名無しさん@お腹いっぱい。
2021/05/08(土) 03:19:50.670850名無しさん@お腹いっぱい。
2021/05/08(土) 05:54:04.89結局自分たちの目で見て確認するしかないという現状。
0851名無しさん@お腹いっぱい。
2021/05/08(土) 16:28:03.01保存されてるURLでもスナップショット無しだと返ってくる
壊れてるなこれw
0852名無しさん@お腹いっぱい。
2021/05/08(土) 17:02:12.53https://web.archive.org/saveにhttps://www.youtube.com/watch?v=動画のID と入力し保存。すぐには保存されないけど、数週間待って見てみると保存できてる
0853名無しさん@お腹いっぱい。
2021/05/08(土) 19:57:36.184K画質のとかでも保存されるの?
0854名無しさん@お腹いっぱい。
2021/05/08(土) 23:10:05.55おお、ありがとうございます
保存までに時間が掛かるんですね
0855名無しさん@お腹いっぱい。
2021/05/09(日) 02:38:40.84画像のアドレスの仕様にもよるがしおりをつけておかないと後で検索のしようがなくなりがちなやつ
imgurの画像とかも保存自体は出来るがどこの何の画像なのかはどこかに記載されてないとカオスに
0856名無しさん@お腹いっぱい。
2021/05/09(日) 03:59:33.78それ動画ページが見れるだけで動画自体は保存されないんじゃないの?
0857名無しさん@お腹いっぱい。
2021/05/09(日) 04:04:52.08YouTubeのビデオは、訴えられる危険を犯した専用の解読スクリプトを書かないと
ビデオを保存できないので無理。
imgurのようなビデオに静的なリンクを張っている所とは違う。
https://web.archive.org/web/20210508173359/https://imgur.com/z55iZcq
<video draggable="false" playsinline="" autoplay="" … >
<source type="video/mp4" src=
"https://web.archive.org/web/20210508173359oe_/https://i.imgur.com/z55iZcq.mp4"
></video>
0858名無しさん@お腹いっぱい。
2021/05/09(日) 04:48:52.27適当にURL貼るとこれとか
http://web.archive.org/web/20150815193649/https://www.youtube.com/watch?v=WJzSBLCaKc8
0859名無しさん@お腹いっぱい。
2021/05/09(日) 21:18:48.23消されてない動画の場合、見るたびにそっちを取りに行ってる可能性がある
まぁ自分も詳しくないので詳しい人いたら教えてほしい
0860名無しさん@お腹いっぱい。
2021/05/10(月) 02:03:24.91保存された動画を再生してるみたい
動画のソース
http://web.archive.org/web/20170214133548oe_/https://r4---sn-n4v7sne7.googlevideo.com/videoplayback?ipbits=0&mm=31&mn=sn-n4v7sne7&ratebypass=yes&expire=1487100946&signature=CA5A22657FBABB6AE773DB9B798B5BA86AE9B362.763F505CD7B9A750710077F92F766E70F1A57187&requiressl=yes&sparams=dur%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Clmt%2Cmime%2Cmm%2Cmn%2Cms%2Cmv%2Cpl%2Cratebypass%2Crequiressl%2Csource%2Cupn%2Cexpire&ms=au&mt=1487079325&upn=NGplNw4c3TQ&mv=m&dur=291.108&pl=20&itag=22&key=yt6&ip=207.241.229.47&lmt=1472445730364669&mime=video%2Fmp4&id=o-ADUZW6CaxfO1uC---vHzDaHvx1GQWxmO717IBgPDVTS0&source=youtube&initcwndbps=2738750&signature=
0861名無しさん@お腹いっぱい。
2021/05/10(月) 02:10:49.840862名無しさん@お腹いっぱい。
2021/05/10(月) 02:13:29.44だから昔のページだと動画が保存されてるのもあるけど今はされてない
0863名無しさん@お腹いっぱい。
2021/05/10(月) 05:21:32.71自分もよく分かってないけど今も保存されてるっぽいよ
昨日の動画が保存されてたから
http://web.archive.org/web/20210509030617/https://www.youtube.com/watch?v=ZxjaW7zGTbA
0864名無しさん@お腹いっぱい。
2021/05/10(月) 14:48:04.32archive.orgの方は接続出来るみたいだが…
0865名無しさん@お腹いっぱい。
2021/05/10(月) 16:09:21.18日本時間で14時20分すぎから鯖落ち中らしい
0866名無しさん@お腹いっぱい。
2021/05/10(月) 16:34:25.60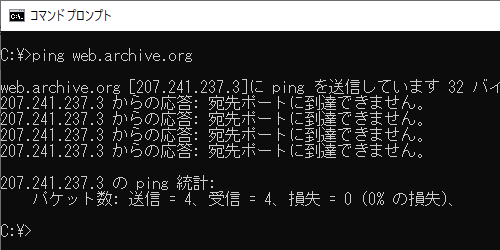
0867名無しさん@お腹いっぱい。
2021/05/10(月) 17:37:18.380868名無しさん@お腹いっぱい。
2021/05/11(火) 13:44:37.60これまで表示されなかったスクショなんかもちゃんと取れてるし
0869名無しさん@お腹いっぱい。
2021/05/11(火) 15:27:21.280870名無しさん@お腹いっぱい。
2021/05/11(火) 19:00:41.67わからん…
0871名無しさん@お腹いっぱい。
2021/05/14(金) 18:54:25.520872名無しさん@お腹いっぱい。
2021/05/15(土) 00:01:24.670873名無しさん@お腹いっぱい。
2021/05/15(土) 00:54:51.91https://gigazine.net/amp/20090628_megalodon
0874名無しさん@お腹いっぱい。
2021/05/15(土) 02:45:03.160875名無しさん@お腹いっぱい。
2021/05/16(日) 07:35:08.10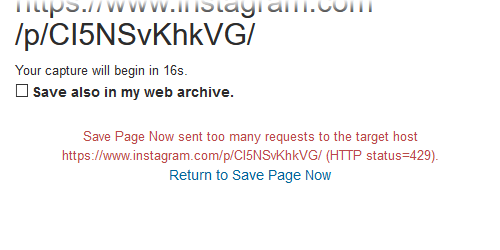
0876名無しさん@お腹いっぱい。
2021/05/17(月) 10:22:21.670877名無しさん@お腹いっぱい。
2021/05/18(火) 16:27:53.74これも記録してあればいいのに。
0878名無しさん@お腹いっぱい。
2021/05/18(火) 18:54:24.220879名無しさん@お腹いっぱい。
2021/05/19(水) 03:51:09.540880名無しさん@お腹いっぱい。
2021/05/19(水) 23:05:23.86二度Sorry出したら二度ともUAが表示されていたから保存されてはいるようだ
0881名無しさん@お腹いっぱい。
2021/05/20(木) 17:13:05.62今日はこのエラー連発で1時間後にやり直したらできたり不安定すぎる
保存できなかった理由も書いてない
0882名無しさん@お腹いっぱい。
2021/05/21(金) 18:08:48.24本人が申請したっぽいけど
0883名無しさん@お腹いっぱい。
2021/05/22(土) 13:44:06.50ビッグデータとして利用する客が考えればいいことか知らんが
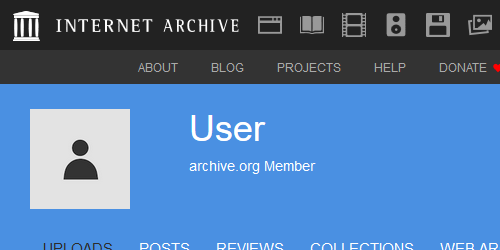
0884名無しさん@お腹いっぱい。
2021/05/23(日) 07:32:01.41現状のsaveだけでもサーバー不安定になるレベルで常にやってるし(それでも全然間に合ってなさそうなのが怖いが)
0885名無しさん@お腹いっぱい。
2021/05/23(日) 22:01:09.82混雑で検索エンジンが止まってるだけかな
The search engine encountered the following error: invalid or no response from Elasticsearch
0886名無しさん@お腹いっぱい。
2021/05/24(月) 07:19:04.300887名無しさん@お腹いっぱい。
2021/05/25(火) 04:48:03.82ページ全体は無理だが画像などバラのパーツは個別に保存が可能だったりすることもある
ザル運営のブラウザゲームなどはありがち
0888名無しさん@お腹いっぱい。
2021/05/25(火) 08:24:52.11ナニコレ
0889名無しさん@お腹いっぱい。
2021/05/25(火) 08:29:38.17> due to system overload
そういうことだろ
0890名無しさん@お腹いっぱい。
2021/05/25(火) 17:48:23.78https://translate.google.co.jp/?sl=auto&;tl=ja&text=Cannot%20fetch%20the%20target%20URL%20due%20to%20system%20overload.%20&op=translate&hl=ja
0891名無しさん@お腹いっぱい。
2021/05/25(火) 23:05:34.280892名無しさん@お腹いっぱい。
2021/05/26(水) 03:28:24.76Explore more than X billion web pages saved over time
のXが一瞬半分になったり変動がすごい
0893名無しさん@お腹いっぱい。
2021/05/26(水) 05:53:27.550894名無しさん@お腹いっぱい。
2021/05/26(水) 18:10:11.990895名無しさん@お腹いっぱい。
2021/05/26(水) 21:05:39.010896名無しさん@お腹いっぱい。
2021/05/27(木) 03:31:52.31一応確認してみるのおすすめ
0897名無しさん@お腹いっぱい。
2021/05/27(木) 22:10:47.880898名無しさん@お腹いっぱい。
2021/05/28(金) 02:03:32.640899名無しさん@お腹いっぱい。
2021/05/28(金) 09:59:53.85が
This URL has been excluded from the Wayback Machine.
になってるのはなんでだろう?ジオシティーズみたいな普通のホームページサービスだったみたいだけど
0900名無しさん@お腹いっぱい。
2021/05/28(金) 10:04:26.18> ジオシティーズみたいな普通のホームページサービスだったみたいだけど
ワロタ
0901名無しさん@お腹いっぱい。
2021/05/28(金) 15:24:41.100902名無しさん@お腹いっぱい。
2021/05/30(日) 04:42:48.430903名無しさん@お腹いっぱい。
2021/05/30(日) 17:45:08.980904名無しさん@お腹いっぱい。
2021/05/30(日) 19:21:56.740905名無しさん@お腹いっぱい。
2021/05/31(月) 01:22:39.810906名無しさん@お腹いっぱい。
2021/06/01(火) 03:49:59.92Cannot fetch the target URL due to system overload.がでる
todayのほうで試したらプロセスが空白で進行せず
megarodonは見かけ上はとれてるがソースからswfの現物アドレスを消して保存してるっぽい
ファイル固有の問題だろうか
デバッガでは開けるんだが
0907名無しさん@お腹いっぱい。
2021/06/01(火) 04:36:21.94どうしてそんなことが起こるのですか
0908名無しさん@お腹いっぱい。
2021/06/01(火) 11:28:13.180909名無しさん@お腹いっぱい。
2021/06/01(火) 13:18:27.550910名無しさん@お腹いっぱい。
2021/06/01(火) 13:20:35.24保存できても表示が更新されないので本当に保存されているか未確認だけど
0911名無しさん@お腹いっぱい。
2021/06/01(火) 17:10:58.680912名無しさん@お腹いっぱい。
2021/06/01(火) 19:40:12.280913名無しさん@お腹いっぱい。
2021/06/02(水) 01:04:22.300914名無しさん@お腹いっぱい。
2021/06/02(水) 01:50:07.20出すぎ
0915名無しさん@お腹いっぱい。
2021/06/02(水) 04:57:26.97個別のswfのアドレス投げ込んだら保存できたからひとまずはいいことにする
開くときは開けるアドレスを知ってないとあかんね
デバッガだと「swfを置いてるページ」では開けないんでarchiveのソースに書かれてる現物のアドレスを掘り出してデバッガに渡すまでしないと開かない
(開けるのは確認できた)
>>911
なんかアナウンスされてたよね archiveのswf全部を勝手にブラウザ上で再生してくれるようなものを期待しちゃうけど
そこまでするのは結構大変なはず
0916名無しさん@お腹いっぱい。
2021/06/02(水) 08:47:16.75ガラケー向けの時計フラッシュまちうけフラッシュは本体が壊れない限り確実に永遠に見れるけどペリーのピアノ講師ネタとか永遠に失われそう
0917名無しさん@お腹いっぱい。
2021/06/02(水) 14:33:51.58誰かが過去に保存したであろう複数ページの記事が途中歯抜けで保存されているのを見かけた。保存失敗か?
元の記事はもう見れないから補完してあげることもできなかった。
0918名無しさん@お腹いっぱい。
2021/06/02(水) 14:54:32.980919名無しさん@お腹いっぱい。
2021/06/09(水) 00:42:55.870920名無しさん@お腹いっぱい。
2021/06/09(水) 01:11:29.08You have already reached the limit of active sessions
↑
先週からエラー出まくり
0921名無しさん@お腹いっぱい。
2021/06/09(水) 06:03:50.69おまいさんのやり方が悪いだけ。先月の制限強化に引っ掛かってるんだろ。
https://docs.google.com/document/d/19RJsRncGUw2qHqGGg9lqYZYf7KKXMDL1Mro5o1Qw6QI/edit
> 2021-05-23
> Anonymous users have lower concurrent captures limit (limit=3) compared to authenticated users (limit=5).
制限値を超えないよう、保存開始のタイミングを調整するしか無い。
アカウントを作ってログインすれば従前の制限値に戻る上、空きセッション数を API で
得られるようになるので、自動的に空きを待ってから保存するようなシステムも
組めるようになる。
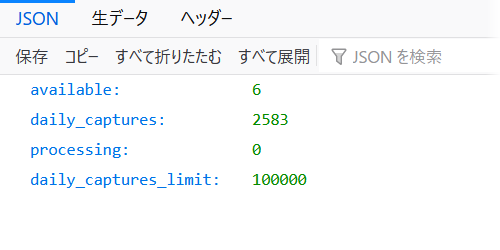
https://web.archive.org/save/status/user (ログインしていなければ 503 エラー)
Change Log に記載は無いが、ログイン済みユーザの制限値は 6 に緩和されている模様。
("available":6)
0922名無しさん@お腹いっぱい。
2021/06/09(水) 15:34:51.370923名無しさん@お腹いっぱい。
2021/06/09(水) 16:25:44.73そういう話じゃ無くて?
0924名無しさん@お腹いっぱい。
2021/06/09(水) 17:46:21.430925名無しさん@お腹いっぱい。
2021/06/09(水) 18:29:55.920926名無しさん@お腹いっぱい。
2021/06/10(木) 05:14:53.41https://kinro.ntv.co.jp/lineup/20210611
保存ができてるのかできてないのかがようわからん
/*/上の階層/*/ってファイルサイズは見れんよね
0927名無しさん@お腹いっぱい。
2021/06/10(木) 09:28:25.29http://web.archive.org/web/20210610001000/taruo.net/e/
ちなみに force_get を 0 (または省略) にしておかないと capture_cookie を指定しても無視される。
0928名無しさん@お腹いっぱい。
2021/06/10(木) 09:46:43.59つまり Set-Cookie でクッキーが返されていた場合、それも保存されているという事。
ログイン管理にクッキーを利用しているサイトで、アーカイブのデータを利用して
誰かに勝手にログインされるという事も起こりうる。
0929名無しさん@お腹いっぱい。
2021/06/10(木) 16:53:57.180930名無しさん@お腹いっぱい。
2021/06/12(土) 22:30:39.38保存しようとしても503やら404の画面になるんだけど…
0931名無しさん@お腹いっぱい。
2021/06/12(土) 22:36:49.230932名無しさん@お腹いっぱい。
2021/06/12(土) 22:49:26.530933名無しさん@お腹いっぱい。
2021/06/12(土) 23:14:58.67だいたいどれくらいで復帰するんだろうか?
1日2日はかかるかな?
0934名無しさん@お腹いっぱい。
2021/06/12(土) 23:18:19.160935名無しさん@お腹いっぱい。
2021/06/13(日) 00:44:05.860936名無しさん@お腹いっぱい。
2021/06/13(日) 08:29:59.22You may close your browser window and the page will still be saved.
0937名無しさん@お腹いっぱい。
2021/06/13(日) 17:29:48.960938名無しさん@お腹いっぱい。
2021/06/14(月) 11:43:37.620939名無しさん@お腹いっぱい。
2021/06/15(火) 07:00:28.90https://i.imgur.com/upjcBi3.png
https://www.jisakeisan.com/?y=2021&;m=6&d=15&hh=8&mm=30&t1=pdt&t2=jst
0940名無しさん@お腹いっぱい。
2021/06/15(火) 09:25:17.87Due to a planned power outage, our services will be reduced on Tuesday, June 15th, starting at 8:30am PDT until the work is complete. We apologize for the inconvenience.
この程度の英文すら機械翻訳使わなきゃ読めない低能
0941名無しさん@お腹いっぱい。
2021/06/15(火) 14:04:45.440942名無しさん@お腹いっぱい。
2021/06/15(火) 15:21:07.340943イモー虫
2021/06/18(金) 20:45:23.130944名無しさん@お腹いっぱい。
2021/06/19(土) 14:06:16.43うっかりログインし忘れるとこれだわw
0945名無しさん@お腹いっぱい。
2021/06/19(土) 18:36:08.030946名無しさん@お腹いっぱい。
2021/06/19(土) 19:35:06.80members.jcom.home.ne.jpも This URL has been excluded from the Wayback Machine.になるね
0947名無しさん@お腹いっぱい。
2021/06/19(土) 21:03:13.890948名無しさん@お腹いっぱい。
2021/06/19(土) 23:24:40.500949名無しさん@お腹いっぱい。
2021/06/20(日) 00:40:25.87アカウント作った意味ないわ
0950名無しさん@お腹いっぱい。
2021/06/20(日) 01:26:26.34同じURLの再保存を試みても待ち時間が延びるだけ。
0951名無しさん@お腹いっぱい。
2021/06/20(日) 03:44:33.220952名無しさん@お腹いっぱい。
2021/06/20(日) 12:42:15.800953名無しさん@お腹いっぱい。
2021/06/20(日) 12:58:58.94ご愁傷様w
0954名無しさん@お腹いっぱい。
2021/06/20(日) 15:59:50.29というか別に待ち時間があっても後で保存されるんだから良くね?
0955名無しさん@お腹いっぱい。
2021/06/21(月) 02:12:27.286月初めぐらいからThis URL has been excluded〜が出るようになってるんだけど、
非表示化か削除依頼出したみたいだねこれ。
0956名無しさん@お腹いっぱい。
2021/06/21(月) 10:45:02.620957名無しさん@お腹いっぱい。
2021/06/21(月) 14:15:21.050958名無しさん@お腹いっぱい。
2021/06/21(月) 14:49:55.100959名無しさん@お腹いっぱい。
2021/06/21(月) 19:46:33.380960名無しさん@お腹いっぱい。
2021/06/22(火) 06:37:35.240961名無しさん@お腹いっぱい。
2021/06/24(木) 00:03:38.03ログインしてても普通に待ち時間表示出るけど、時間帯によって変わったりするの?
0962名無しさん@お腹いっぱい。
2021/06/27(日) 13:37:52.83>>57
問題なのは関連付けされてる場合はログインしている時のメールアドレスやユーザ名、ログイン関係なくハッシュ化したIPアドレスやUserAgent部分がWARCファイルの名前フィールド部分に保存される可能性がある。
気になるなら保存するときだけUserAgentやIPアドレス変えたり保存するページごとに別ければいい。
0963名無しさん@お腹いっぱい。
2021/06/28(月) 11:48:52.210964名無しさん@お腹いっぱい。
2021/07/02(金) 11:56:14.720965名無しさん@お腹いっぱい。
2021/07/02(金) 15:17:24.600966名無しさん@お腹いっぱい。
2021/07/12(月) 07:09:59.53インターネットアーカイブでも履歴が残っていないことがある
忍者とかいうブログサイトを使っているのだが、
あそこって削除した画像とかの履歴を残さないようにする機能とかあるのだろうか
0967名無しさん@お腹いっぱい。
2021/07/12(月) 16:06:59.65他の魚拓サイトにも残ってないの?まあブログはアーカイブされてないことが多いからなぁ。
0968名無しさん@お腹いっぱい。
2021/07/12(月) 16:33:16.08って今時の人は知らんのか
で、もうそろそろ次スレテンプレの話題でも
0969名無しさん@お腹いっぱい。
2021/07/12(月) 23:07:03.45現行の関連スレ
https://refind2ch.org/search?q=archive.
0970名無しさん@お腹いっぱい。
2021/07/14(水) 01:47:06.23アーカイブ保存は
mobile.ツイッター.com
でなければならないが
回収web.archive.org/web/9999/はmobile.を外さなきゃならない
ってこれガラケーだけ?
0971名無しさん@お腹いっぱい。
2021/07/14(水) 04:14:39.670972名無しさん@お腹いっぱい。
2021/07/16(金) 04:27:32.78それは置いといて>>5とかの話は入れたほうが良さそう
0973名無しさん@お腹いっぱい。
2021/07/16(金) 13:46:21.980974名無しさん@お腹いっぱい。
2021/07/18(日) 03:03:30.60The Wayback Machine has not archived that URL.って出るサイトは
どうやってもみれないんですか?
0975名無しさん@お腹いっぱい。
2021/07/18(日) 18:09:30.90アーカイブしてないからそもそも保存されてない
0976名無しさん@お腹いっぱい。
2021/07/18(日) 19:27:16.87archiveteamが保存した一部のスナップショットを見ると、この「俺たちが保存したぜ」画像のURLを読み込むから、
誰がどのページを見たかarchiveteamのウィキサイトに情報が漏れるんだけど、ただのスパイじゃねーか。
Internet Archiveの人は誰も気付いてないのかなこれ。
0977名無しさん@お腹いっぱい。
2021/07/18(日) 20:43:46.800978名無しさん@お腹いっぱい。
2021/07/19(月) 02:22:16.98個人がアップロードしたWARCファイルは扱ってないじゃん
結局のところ制限引っかからないように/save/にURL投げるコードしか組めんよ
何も知らない無能はお前だ
0979名無しさん@お腹いっぱい。
2021/07/19(月) 05:43:32.79なぜArchiveTeamだけを気にしてるのかは知らんが
0980名無しさん@お腹いっぱい。
2021/07/19(月) 22:59:58.68ほんまや
About this captureの説明のところに埋め込んであった
でもブラウザの挙動はCSPで読み込みブロックってなってるから
インターネットアーカイブ側の対策でデータは送信されてない感じかね
0981名無しさん@お腹いっぱい。
2021/07/23(金) 00:21:19.80https://anniversary.archive.org/
0982名無しさん@お腹いっぱい。
2021/07/23(金) 16:15:09.58アレクサンドリア図書館からヨハネスグーテンベルクによる印刷機の発明まで。
情報への権利の第一修正の保証からワールドワイドウェブの作成まで、知識へのアクセスは常に建設者と夢想家のおかげでした。
さて、ブリュースター・ケールという若いコンピューター科学者がデジタル時代の「すべての図書館」を建設することを夢見ていた1996年にさかのぼります。
人類の出版されたすべての作品を含み、一般に無料で、時代を超えて非営利団体として構成されたライブラリ。彼はこのデジタルライブラリをインターネットアーカイブと名付けました。
その使命は、すべての人に「すべての知識への普遍的なアクセス」を提供することです。
この25年のマイルストーンに関するブリュースターの考察を読む
バーチャルセレブレーションに参加する
あなたが世界のどこにいても、私たちと一緒に祝いに来てください。
ウェイバックからウェイフォワードへ:25のインターネットアーカイブ
星を目指して到達したビルダーと夢想家との仮想の旅。
10月21日木曜日午後6時PT(午後9時ET)
0983名無しさん@お腹いっぱい。
2021/07/24(土) 02:54:26.16It may take a few days for YouTube videos to become available for playback.
動画もアーカイブされてるってことでいいのかな?
0984名無しさん@お腹いっぱい。
2021/07/24(土) 13:53:59.140985名無しさん@お腹いっぱい。
2021/07/31(土) 03:20:35.580986名無しさん@お腹いっぱい。
2021/07/31(土) 19:00:56.160987名無しさん@お腹いっぱい。
2021/07/31(土) 21:11:28.650988名無しさん@お腹いっぱい。
2021/08/01(日) 03:48:55.710989名無しさん@お腹いっぱい。
2021/08/01(日) 16:10:13.05これ使ってURL変換すると保存できるよ
https://lab.syncer.jp/Tool/Twitter-Video-URL-Converter/
0990名無しさん@お腹いっぱい。
2021/08/01(日) 18:08:12.290991名無しさん@お腹いっぱい。
2021/08/01(日) 18:27:20.020992名無しさん@お腹いっぱい。
2021/08/01(日) 19:07:49.480993名無しさん@お腹いっぱい。
2021/08/13(金) 03:38:50.58Internet Archive総合 (web.archive.org) #4
https://mevius.5ch.net/test/read.cgi/esite/1628793497/
0994名無しさん@お腹いっぱい。
2021/08/13(金) 07:19:48.01とか出てきたんやけど・・・
0995名無しさん@お腹いっぱい。
2021/08/13(金) 09:36:18.659時過ぎたので、一応リセットされて表示されなくなったが、
毎日これが出たら困るな、特に朝保存したい場合は
0996名無しさん@お腹いっぱい。
2021/08/13(金) 13:38:54.090997名無しさん@お腹いっぱい。
2021/08/13(金) 19:21:46.35おつでござんす
0998名無しさん@お腹いっぱい。
2021/08/13(金) 19:26:23.910999名無しさん@お腹いっぱい。
2021/08/13(金) 20:25:45.611000名無しさん@お腹いっぱい。
2021/08/13(金) 20:56:15.43おい、お前。そう、お前だよ。
「このスレおもろいから見てみ」「2ちゃんの歴史に残る名スレだぜ」とか言われてホイホイと
このhtml化されたスレを見にきた、お前のことだ。
どうだ?このスレおもしれーだろ。
でもな、お前はこのスレを読むだけで、参加することはできねーんだよ。
可愛そうにな、プププ。
俺は今、ライブでこのスレに参加してる。
すっげー貴重な経験したよ。この先いつまでも自慢できる。
まあ、お前みたいな出遅れ君は、html化されたこのスレを指くわえて眺めてろってこった。
10011001
Over 1000Thread新しいスレッドを立ててください。
life time: 498日 18時間 48分 6秒
10021002
Over 1000Thread運営にご協力お願いいたします。
───────────────────
《プレミアム会員の主な特典》
★ 5ちゃんねる専用ブラウザからの広告除去
★ 5ちゃんねるの過去ログを取得
★ 書き込み規制の緩和
───────────────────
会員登録には個人情報は一切必要ありません。
月300円から匿名でご購入いただけます。
▼ プレミアム会員登録はこちら ▼
https://premium.5ch.net/
▼ 浪人ログインはこちら ▼
https://login.5ch.net/login.php
レス数が1000を超えています。これ以上書き込みはできません。

ニュース
- 大谷翔平がドジャースと結んだ総額1015億円の超大型契約は大成功!? 4安打&2本塁打の大爆発に米記者確信 [夜のけいちゃん★]
- 息子のチー牛化を避けるには「中学生から美容院に行かせる」といい? その重要性に注目あつまる ★3 [Hitzeschleier★]
- 【高橋洋一氏】日本経済に円安の恩恵大きい 財務省はマスコミの「円安悪者論」に加担 円安の恩恵数十兆円“国民に還元”せよ [Hitzeschleier★]
- 【芸能】キンコン・梶原雄太 吉本興業にブチギレ投稿の理由を「もう全部話す」 問題を指摘し「辞めるかもしれへん。いつかは」 [冬月記者★]
- 霜月るな、松本人志への思いを記した曲をリリース「みんなずっと待ってるよ」 [Anonymous★]
- 飲食店で奇声を上げ料理投げる子ども、スマホ見て注意しない親…清掃に30分以上、店主の本音「出禁にしたい」 [少考さん★]
- 【実況】博衣こよりのえちえちコンボイの謎🧪 ★4
- 【🍐】IIDXランカースレ🏡【ドルちぇ?👶】
- 米紙「日本はめちゃくちゃ没落してるのに日本人は落ち着き払ってる。一体なぜなんだ…」 [819729701]
- 【悲報】東京の家賃、ガンガンズンズングイグイ上昇、賃貸民息してるか? [985879258]
- 🏡
- 【動画】チー牛、食べかけのラーメンを女性にぶっかけて逃走wwwwwwww [834922174]