Internet Archive総合 (web.archive.org) #4
レス数が1000を超えています。これ以上書き込みはできません。
なんだかんだでお世話になってるInternet Archiveについて語りましょう
Internet Archive
ttp://www.archive.org/index.php
インターネット・アーカイブ - Wikipedia
ttp://ja.wikipedia.org/wiki/InternetArchive
------------------
Q.Internet Explorerで日本語などの2byte言語のページのWeb Archiveキャッシュを見ようとしても
真っ白なページ&文字化けが起きる&極端に重いなどの症状が出てしまう
A.[表示]もしくは右クリック→[エンコード]→[日本語(自動選択)]やその言語の文字コードに則したものをクリック
Q.Web Archiveでダウンロードしたzipなどが開けない&CRCが違うと表示される
A.よくWeb Archiveは1byte欠けを起こすのでバイナリエディタなどで該当ファイルを開き、
16進数の最後の末尾に「00」を付加すると正常なファイルになることがあります。
前スレッド
Internet Archive総合 (web.archive.org) #3
https://mevius.5ch.net/test/read.cgi/esite/1585760889/ PDFファイルのURLを保存させたらその1ページ目しか保存されないのだけど仕様?
なわけないよなぁ >>900
閲覧環境によっては、1ページ目しか表示されない場合がある
(iOSとかだとダメっぽいな)
解決策は、閲覧したいページのURLを編集して数字の後ろにid_ をつけ加えると保存されたまんまの状態で表示されるから、これで全ページ閲覧できるようになるよ
↓こんな感じ
https://web.archive.org/web/数字id_/ページURL >>901
thx。たしかにiOSのSafariで見てた
保存ではなく閲覧環境の問題なのね >>903
WSL使うのが嫌だったので遠ざけていましたが使ってみます。
ありがとうございます。 「リンクと画像の抜き出しツール」のアーカイブから画像のURLを入れると画像が保存されているか確認できる。 「URLからタイトルゲット君」というサイトも保存確認できる。 >>904
そんなに量がないんだったら無料版Colabで走らせてもいいかもね >>892
3月までtodayでアーカイブしたGoogle検索結果をorgで重バックアップしたり出来たが(アクセス環境により検索ワード化けが生じるため)、4月からエラーで弾かれるようになってしまった。
ヤフオクの出品物もorgから取れなくなったし Something went wrong. Try reloading.
ツイッターのアーカイブ閲覧しようとするとこうなるけど、おま環? ふとIAの動画ブラウジングしてたんだけど字幕付きのアニメとか滅茶苦茶うpされて、無法地帯になっててワロタ
アメリカのフェアユースってそんな強いのか >>912
いや普通にアウトだし消されてるよ、いたちごっこだけど
IAの人も何が重要なデータか分からなくなるから止めろってツイートしてたりする
基本的にIAのアカウントがアップしたもの以外は信用しない方がいい アイテムの方にある動画、一定以上のサイズだとブラウザで再生出来ないっぽいな
自分が見たのは20GB超だけど読み込みがされなかった
curlでダウンロードしてローカルで再生は出来たので、ちゃんとアーカイブはされてるらしい それってエンコード時の設定に依ったりしない?
例えば mp4 なら moov atom をファイル先頭に持ってきていないとか。 トップページの保存数(Explore more than XXX billion)がたまに十億単位で減るの
何なんだろうか? 詳しいことよく知らなくてTorのブラウザでarchivetoday使おうとしたらTor使ってないときでもarchivetodayにアクセスできなくなった
クッキー消去したらまた使えるようになったけどブラックリスト的なものに載ってないか不安 >>918
まともにTor使ってるなら、生IPとの関連付けが出来ないんだからTor使ってないときにアクセス不可になるはずがない
それすら分からないならtorは使わない方が良いよ、絶対にどこかでやらかす なんでわざわざTorブラウザでarchivetoday使おうとしたの?普通のブラウザでも使えるよ >>920
10年以上前にTor使えばInstagramでも魚拓取れるって書き込みを見つけたので試したくなったんです
無知ですいませんでした IP紐づいてなくてもフィンガープリントで同一デバイスだと疑われてる可能性はある
とは言っても、torブラウザでtoday使うとCloudflareにブロックされて要JSの認証要求されるから回避も難しいんだよな
唯一の回避策は、使えそうなweb串探してtor→web串→todayでアクセスするくらいか
フィンガープリント追跡防止の拡張機能とかもあるからそういうのを普段使いしてみるのも対策の一つになるかもね 今更だけど3200ツイート保存のやつエラーで動かなくなってる
Twitterの仕様が変わった辺りからかな?確認してなかった >>867>>869
Twitterの鍵垢を保存したら犬のエラーが保存されたわ。原因はこれじゃない? >>927
いや普通の公開アカウントだった
なぜか木曜日だけどのツイートも犬のエラーになってた https://esica.shop/collections/weekly-ranking/products/eset-4660
↑みたいなサイトを保存すると保存直後は画像が表示されてるのに数か月後保存ページにアクセスすると、
一部画像が表示されないって事が多々あるんだけどおま環?
そのページの画像(大きい小さい表示されるの全て)を一括で保存する方法って無いのかな >>929
数か月後どころか、保存直後も大量の画像が欠落してるんだけど・・・
スクリプトで読み込ませてる画像の一括取得は現状では無理。
ブラウザでアーカイブを表示したときに初めて取得リクエストが発行されるが、
毎分 2 個か 3 個の画像を取得するだけで、あとは 429 Too Many Requests エラーが返ってしまう。
必要な画像を拾い終えるまで、同じアーカイブを数分おきにブラウザで繰り返し表示するしかない。
昨晩ここの画像を全部拾わせてみたので、数か月後にどうなってるか見てみよう。
https://web.archive.org/web/20230627123623/esica.shop/collections/weekly-ranking/products/eset-4160 今風のスクリプトマシマシ動的サイトはアーカイブするのが難しいからね
画像だけ欠落するならまだマシで、サイト自体が取れないことも珍しくない Twitterの投稿、wayback machineはアーカイブできるけどarchive todayはできなくなってない? >>932
Twitterの仕様変更でログイン状態じゃないとログインページにリダイレクトされるようになったっぽいな
Internet Archiveは何か特別な処理挟んでるのかね save-page-now-outlinksって今動いてないの?
リンク先の保存もやらなきゃいけないじゃんか >>933
ほんとだログインしたらアーカイブできた
どうやってログイン状態検出してるのかも謎だ Pixivのページを保存したいとき、英語ページのURL(en)へ転送されないようにするにはヘッダーに何を指定すればいい?
なんか方法ある? Pixiv から user_language=ja ってクッキーを食べたことにしておけば、
つまりそれを capture_cookie 引数に与えて Save Page Now すれば
転送はされなくなるけど・・・どこも真っ白だぁ waybackもtodayもtwitter保存できねえ Twitter自体が現在不調だからね直してもらわないと Twitterの仕様変更で
魚拓取れなくなるのかな…
アカウント必須になったら魚拓取れない… Twitterは仕様変更するわ、IAは保存しても読み込めるまで1日以上かかるわ、インターネットに波乱起きすぎ archive.org/details/save-page-now?sort=-addeddate
日本時間13時21分のファイル以降、SPNの新しいコレクションファイルが増えてないので止まってたっぽいが、今は復帰して保存できるっぽい。 Twitter、一応取れるようにはなったが単体ツイートしか取れなくなったな
前はリプライも全部保存出来たが不可能になった
あとプロフィールページも保存出来ない
IAの問題ではなく、Twitter側が非ログイン状態での表示を止めたせい 5chもぼちぼちアーカイブしていかないとヤバイ感じか? 5ちゃんのスレも個人的に保存はちょくちょくやってはいるんだけど、すぐ人大杉になって作業が止まるのが難点。
自分の住民やってるスレやその過去スレからでいいので、やっておいた方がいいよ。 これはヤバいな
過去ログごと消えたら洒落にならない 筑波大吉田光男准教授が公開してる5chスレタイのデータセット
http://open.ceek.jp IAのチームに過去ログ全部クロールして欲しいな。今はなんとか過去ログが見れるけど、明日急に全部見れなくなっても全く不思議じゃないからヒヤヒヤしてる
似たようなサイトでredditって過去ログ保管されてるんだろうか threadsってアーカイブ出来ないタイプのサイトかぁ・・・ threadsってアーカイブ出来ないタイプのサイトかぁ・・・ 「好き嫌い.com」は魚拓サイトで魚拓を取ってもコメント欄だけが保存されない
どうすればコメント欄も保存できるかな?
i.imgur.com/2uPwBGz.png archive.li/6nRmy 5chを保存しようとクロールしたらクロールが全く意味を成さないわね…なにかいい方法あるだろうか? これからAI時代になると、IAのデータってますます重要になりそうだな(AIとIAでややこしい) yahooニュースのコメント保存できるようになったな 過去ログ取ろうとしたけど膨大やな
自分の環境だと七時間で2500urlぐらい >>961
2chから5chにURL変わった影響もありそう
てかTwitterの会話取れなくなったの不便すぎるな ここ最近やる気を感じないな、アクティブチームは。
自動アーカイブも全然取れてないし。 アクティブチームって何だArchive-teamのこと? うーん、ボタンを押しても即座にこれが返ってくる
 俺もや、ついに規制くらったかと思ったけど
俺もや、ついに規制くらったかと思ったけど
サーバー側の問題か どこか特定のサイトを取得する場合の問題かと思ったら別のサイトで試しても>>969 放置してたらURL8万行分集めてて、もう飽きたからこれアーカイブしてdatアーカイブやめます
保存されるやつみたら文字化けしてるし意味あるのかなといった感じでもある
普通の過去ログやる方が有意義におもう スクリプト回してるのにim_とかid_とか知らないって嘘くせぇ Twitchもyoutubeみたいにアーカイブ保存出来るようにならんかなぁ
というかyoutubeと違って一定期間で消えるから、むしろこっちを優先して欲しいまである 動画ファイルバカでかいししゃーないでしょ
キリないもん、あとtubeupえばupはできると思う
だけどあれ待機時間がすげー長いんだよなぁ >>976
それなに? スクリプト使ってないから知らない >>975
どうやって8万行も集めたの?
詳しく聞かせてほしい
Googleの拡張機能でアーカイブ常に取る設定にしてたとか? >>980
ただずっと>903のスクリプト動かしてただけ
outlinkの取得先は全板の過去ログのurlを指定した スクリプト回してるのにim_とかid_とか知らないって嘘くせぇ 1週前ぐらいに取得した(ことになってる)はずなのに取得できてないのがいくつも・・・
The snapshot may not be available right now, please try again later.
最近が↑たまに出るが、
それとの関係だろうか・・・
せっかく時間かけて取得したはずができてないのは残念 archive.isはもう3日ほど繋がらないし
Wayback Machineは相変わらずツイッタープロフィールとリプがダメで
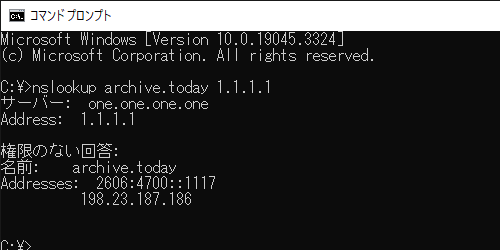
リプで繋がってるものも個々でしか取れないから面倒くさい archive.today は、まだ Cloudflare の DNS(1.1.1.1) を拒否しているのかな? >>991
おま環なのかわからないけどtodayは4日前までは普通に繋がってたけど
急に繋がらくなって今も繋がない
このサイトにアクセスできませんarchive.is により途中で接続が切断されましたって出る
chrome・edge・Fire Foxの全部で繋がらないから環境だとしたら何が原因なのかさっぱり
因みにCloudflare の DNS(1.1.1.1)ではないよ レス間違えましたすみません
>>994 は >>992 が正しいです >>993
とか言うだけで、実際に叩いてみたりしないんだ
所詮その程度w
 あれarchive.org落ちてる?spnエラー吐いてる >>997-998
あれarchive.org落ちてる?spnエラー吐いてる >>997-998
ここ数日 web.archive.org への接続自体がエラーとなるケースが増えてると思うよ。 レス数が1000を超えています。これ以上書き込みはできません。




{kind=link}