Internet Archive総合 (web.archive.org) #3
レス数が1000を超えています。これ以上書き込みはできません。
なんだかんだでお世話になってるInternet Archiveについて語りましょう
Internet Archive
ttp://www.archive.org/index.php
インターネット・アーカイブ - Wikipedia
ttp://ja.wikipedia.org/wiki/InternetArchive
------------------
Q.Internet Explorerで日本語などの2byte言語のページのWeb Archiveキャッシュを見ようとしても
真っ白なページ&文字化けが起きる&極端に重いなどの症状が出てしまう
A.[表示]もしくは右クリック→[エンコード]→[日本語(自動選択)]やその言語の文字コードに則したものをクリック
Q.Web Archiveでダウンロードしたzipなどが開けない&CRCが違うと表示される
A.よくWeb Archiveは1byte欠けを起こすのでバイナリエディタなどで該当ファイルを開き、
16進数の最後の末尾に「00」を付加すると正常なファイルになることがあります。
前スレッド
Internet Archive総合 (web.archive.org) #2
http://mevius.5ch.net/test/read.cgi/esite/1475246713/ >>899
> ジオシティーズみたいな普通のホームページサービスだったみたいだけど
ワロタ ジオシティーズやトクトクは普通だけどフリーティケットシアターは普通じゃない的な /*/はFail with status: 498 No Reason Phrase なるべく円高米ドル安の時に寄付したほうがいいんだろうな。 batchのページ開いてもトップに飛ばされてしまうようになった swfのあるページの取得厳しいんだっけ
Cannot fetch the target URL due to system overload.がでる
todayのほうで試したらプロセスが空白で進行せず
megarodonは見かけ上はとれてるがソースからswfの現物アドレスを消して保存してるっぽい
ファイル固有の問題だろうか
デバッガでは開けるんだが swfってただのファイルじゃないの
どうしてそんなことが起こるのですか We only allow new captures of the same URL every 45 minutes. 激遅の/save/で行けたりしない?>swf
保存できても表示が更新されないので本当に保存されているか未確認だけど ファイル1個だけなら画像の確認とかやらないから拡張子関係なく超高速で保存できるはずだけど Cannot fetch the target URL due to system overload.
出すぎ >>910
個別のswfのアドレス投げ込んだら保存できたからひとまずはいいことにする
開くときは開けるアドレスを知ってないとあかんね
デバッガだと「swfを置いてるページ」では開けないんでarchiveのソースに書かれてる現物のアドレスを掘り出してデバッガに渡すまでしないと開かない
(開けるのは確認できた)
>>911
なんかアナウンスされてたよね archiveのswf全部を勝手にブラウザ上で再生してくれるようなものを期待しちゃうけど
そこまでするのは結構大変なはず 3Gガラケーの本体自体にフラッシュの再生機能付いててアーカイブ含め見れるが画面が小さいのがあかんな
ガラケー向けの時計フラッシュまちうけフラッシュは本体が壊れない限り確実に永遠に見れるけどペリーのピアノ講師ネタとか永遠に失われそう SPNを保存されたかの確認に使うというわけ分からん状況になってる。
誰かが過去に保存したであろう複数ページの記事が途中歯抜けで保存されているのを見かけた。保存失敗か?
元の記事はもう見れないから補完してあげることもできなかった。 「Ruffle」というchrome拡張機能使えばFlash見れるよ Sorry
You have already reached the limit of active sessions
↑
先週からエラー出まくり >>920
おまいさんのやり方が悪いだけ。先月の制限強化に引っ掛かってるんだろ。
https://docs.google.com/document/d/19RJsRncGUw2qHqGGg9lqYZYf7KKXMDL1Mro5o1Qw6QI/edit
> 2021-05-23
> Anonymous users have lower concurrent captures limit (limit=3) compared to authenticated users (limit=5).
制限値を超えないよう、保存開始のタイミングを調整するしか無い。
アカウントを作ってログインすれば従前の制限値に戻る上、空きセッション数を API で
得られるようになるので、自動的に空きを待ってから保存するようなシステムも
組めるようになる。
https://web.archive.org/save/status/user (ログインしていなければ 503 エラー)
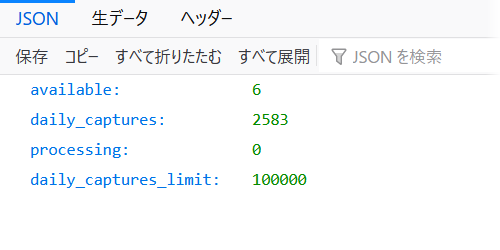
Change Log に記載は無いが、ログイン済みユーザの制限値は 6 に緩和されている模様。
("available":6)
 なんかリファラー変更ができなくなったっぽいんだけど俺環? ブラウザが (IA のヘッドレスブラウザも含めて) リファラを送らなくなったとか
なんかリファラー変更ができなくなったっぽいんだけど俺環? ブラウザが (IA のヘッドレスブラウザも含めて) リファラを送らなくなったとか
そういう話じゃ無くて? マジか。じゃ もうリファラ必要なサイトは保存できなくなったのか 金ローの画像はどういう仕組みなんだろう
https://kinro.ntv.co.jp/lineup/20210611
保存ができてるのかできてないのかがようわからん
/*/上の階層/*/ってファイルサイズは見れんよね API を使うとクッキーも送れるけど、ハイジャック耐性の無いユルいサイトしか使い道が無いな。
http://web.archive.org/web/20210610001000/taruo.net/e/
ちなみに force_get を 0 (または省略) にしておかないと capture_cookie を指定しても無視される。 そうそう、IA のアーカイブはサーバのレスポンスヘッダが丸ごと保存されていることに留意。
つまり Set-Cookie でクッキーが返されていた場合、それも保存されているという事。
ログイン管理にクッキーを利用しているサイトで、アーカイブのデータを利用して
誰かに勝手にログインされるという事も起こりうる。 また繋がらなくなった?
保存しようとしても503やら404の画面になるんだけど… 最近、頻繁に使うようになったけど、今繋がらないみたいだね。
だいたいどれくらいで復帰するんだろうか?
1日2日はかかるかな? 親切な表示が出るようになってる
You may close your browser window and the page will still be saved. 向こうで計画停電が起こるみたいだから、こっちの時刻で16日の0時30分からしばらくサービス停止するらしい。
https://i.imgur.com/upjcBi3.png
https://www.jisakeisan.com/?y=2021&;m=6&d=15&hh=8&mm=30&t1=pdt&t2=jst >>939
Due to a planned power outage, our services will be reduced on Tuesday, June 15th, starting at 8:30am PDT until the work is complete. We apologize for the inconvenience.
この程度の英文すら機械翻訳使わなきゃ読めない低能 人は上から目線で間違いを訂正するときに性行為より快感を感じるらしい The capture is estimated to start in 120 minutes. You may close your browser window and the page will still be saved.
うっかりログインし忘れるとこれだわw 523分待ちだったわ 撮ってくれるんならまあいいけど >>899
members.jcom.home.ne.jpも This URL has been excluded from the Wayback Machine.になるね 1085分、てかアカウントでログインして保存しようとしてもこの表示出るじゃん
アカウント作った意味ないわ 待ち時間が一度表示されてしまうと、その後ログインして
同じURLの再保存を試みても待ち時間が延びるだけ。 まだログインしないと待ち時間が出る状態なの?
ご愁傷様w 今は直ってるな
というか別に待ち時間があっても後で保存されるんだから良くね? 伊是名夏子のブログのアーカイブを見ようとすると
6月初めぐらいからThis URL has been excluded〜が出るようになってるんだけど、
非表示化か削除依頼出したみたいだねこれ。 archive.is 自体が消えてしまったりしないの? という話が。 Cannot get status of spn2-2afbf2c51be876410f7a78331b331ea74cd21c67-5a282757 >>953
ログインしてても普通に待ち時間表示出るけど、時間帯によって変わったりするの? >>952
>>57
問題なのは関連付けされてる場合はログインしている時のメールアドレスやユーザ名、ログイン関係なくハッシュ化したIPアドレスやUserAgent部分がWARCファイルの名前フィールド部分に保存される可能性がある。
気になるなら保存するときだけUserAgentやIPアドレス変えたり保存するページごとに別ければいい。 何度許可してもログインしなおしてもBatchのArchive URLsに入れない Batch入れないけど、騒いでるの俺だけっぽいから俺環なのか 皆さん自前でバッチ処理しているから使ってない、に一票 あるWEBサイトの一部が消えているのだけれど、
インターネットアーカイブでも履歴が残っていないことがある
忍者とかいうブログサイトを使っているのだが、
あそこって削除した画像とかの履歴を残さないようにする機能とかあるのだろうか >>966
他の魚拓サイトにも残ってないの?まあブログはアーカイブされてないことが多いからなぁ。 忍者って昔やたらボット除けに精を出してた所じゃないか
って今時の人は知らんのか
で、もうそろそろ次スレテンプレの話題でも ツイッターのアーカイブ保存、回収の法則テンプレに入れようぜ。
アーカイブ保存は
mobile.ツイッター.com
でなければならないが
回収web.archive.org/web/9999/はmobile.を外さなきゃならない
ってこれガラケーだけ? 普通にTwitterをアーカイブすればmobileは付かないと思うんだが・・・
それは置いといて>>5とかの話は入れたほうが良さそう Hrm.
The Wayback Machine has not archived that URL.って出るサイトは
どうやってもみれないんですか? >>974
アーカイブしてないからそもそも保存されてない ttps://wiki.archiveteam.org/images/e/e6/Archiveteam.jpg
archiveteamが保存した一部のスナップショットを見ると、この「俺たちが保存したぜ」画像のURLを読み込むから、
誰がどのページを見たかarchiveteamのウィキサイトに情報が漏れるんだけど、ただのスパイじゃねーか。
Internet Archiveの人は誰も気付いてないのかなこれ。 と、自分でスクリプトを組んでアーカイブできない無能が文句を垂れております。 >>977
個人がアップロードしたWARCファイルは扱ってないじゃん
結局のところ制限引っかからないように/save/にURL投げるコードしか組めんよ
何も知らない無能はお前だ そのレベルの情報を気にするなら個人でproxyなりVPNなり使えばいいのでは
なぜArchiveTeamだけを気にしてるのかは知らんが >>976
ほんまや
About this captureの説明のところに埋め込んであった
でもブラウザの挙動はCSPで読み込みブロックってなってるから
インターネットアーカイブ側の対策でデータは送信されてない感じかね インターネットアーカイブが25歳になったら、知識がすべての人にとってよりアクセスしやすくなった極めて重要な瞬間を経て、戻る方法から進む方法への旅にあなたを招待します。
アレクサンドリア図書館からヨハネスグーテンベルクによる印刷機の発明まで。
情報への権利の第一修正の保証からワールドワイドウェブの作成まで、知識へのアクセスは常に建設者と夢想家のおかげでした。
さて、ブリュースター・ケールという若いコンピューター科学者がデジタル時代の「すべての図書館」を建設することを夢見ていた1996年にさかのぼります。
人類の出版されたすべての作品を含み、一般に無料で、時代を超えて非営利団体として構成されたライブラリ。彼はこのデジタルライブラリをインターネットアーカイブと名付けました。
その使命は、すべての人に「すべての知識への普遍的なアクセス」を提供することです。
この25年のマイルストーンに関するブリュースターの考察を読む
バーチャルセレブレーションに参加する
あなたが世界のどこにいても、私たちと一緒に祝いに来てください。
ウェイバックからウェイフォワードへ:25のインターネットアーカイブ
星を目指して到達したビルダーと夢想家との仮想の旅。
10月21日木曜日午後6時PT(午後9時ET) YoutubeのURL取ったら下のメッセージが出た
It may take a few days for YouTube videos to become available for playback.
動画もアーカイブされてるってことでいいのかな? Youtubeを保存したいなら手動保存が望ましい。クローラーの保存だと再生できないケースあり。 <title>だけでも検索できるといいんだけどなあ Tor clients have already done 200,000 captures today. Please email us at "info@archive.org" if you would like to discuss this more.
とか出てきたんやけど・・・ Tor使ってないのに俺も今日初めてそのエラーが出てきた
9時過ぎたので、一応リセットされて表示されなくなったが、
毎日これが出たら困るな、特に朝保存したい場合は IAの中の人はTorがどういうものか分かってないらしいw 【 html化されたこのスレを読んでいるお前へ 】
おい、お前。そう、お前だよ。
「このスレおもろいから見てみ」「2ちゃんの歴史に残る名スレだぜ」とか言われてホイホイと
このhtml化されたスレを見にきた、お前のことだ。
どうだ?このスレおもしれーだろ。
でもな、お前はこのスレを読むだけで、参加することはできねーんだよ。
可愛そうにな、プププ。
俺は今、ライブでこのスレに参加してる。
すっげー貴重な経験したよ。この先いつまでも自慢できる。
まあ、お前みたいな出遅れ君は、html化されたこのスレを指くわえて眺めてろってこった。 レス数が1000を超えています。これ以上書き込みはできません。


