Internet Archive総合 (web.archive.org) #3
■ このスレッドは過去ログ倉庫に格納されています
なんだかんだでお世話になってるInternet Archiveについて語りましょう
Internet Archive
ttp://www.archive.org/index.php
インターネット・アーカイブ - Wikipedia
ttp://ja.wikipedia.org/wiki/InternetArchive
------------------
Q.Internet Explorerで日本語などの2byte言語のページのWeb Archiveキャッシュを見ようとしても
真っ白なページ&文字化けが起きる&極端に重いなどの症状が出てしまう
A.[表示]もしくは右クリック→[エンコード]→[日本語(自動選択)]やその言語の文字コードに則したものをクリック
Q.Web Archiveでダウンロードしたzipなどが開けない&CRCが違うと表示される
A.よくWeb Archiveは1byte欠けを起こすのでバイナリエディタなどで該当ファイルを開き、
16進数の最後の末尾に「00」を付加すると正常なファイルになることがあります。
前スレッド
Internet Archive総合 (web.archive.org) #2
http://mevius.5ch.net/test/read.cgi/esite/1475246713/ 検索がfailed to fetchになってしまって全然できない… save pageボタン押してもなかなか画面が変わらなくて
最後は502 Bad Gateway表示ばっかり SPNは復帰
/save/は502 Bad Gateway The capture is estimated to start in 600 minutes.
昨日ぐらいからSave Page Nowでこんな表示出てくるんだけど、あと10時間も待ってないといけないわけ?
いい加減にサーバー増強しろよ。。 Tweetsaveについて知らないニワカが落ちてると叩くのは
サービスを潰しかねない迷惑行為なのでやめてもらいたい 今Save Nowに突っ込んだら680分待ちでワロタ そもそもいつからTweetsaveがInternet Archiveの傘下に入ったんだ?
ウェブアーカイブ総合スレでやれ Internet Archiveも資金繰りが厳しいらしいからな
サーバの重さに文句言っていいのは寄付した人間だけだろ、自分は寄付してないから当然言えない IA目線になる必要はない
向こうにクレームつけてるワケでなし Internet archive取得できないな
Saving..のままだ The capture is estimated to start in 264 minutes. ここに書いてもしょうがないかしらんが
サイト撤去跡などでリダイレクトされるやつのリダイレクトが早すぎて
結局アドレスバーに直打ちしないと目当てのサイトを探せないのは何かなあ FirefoxなんでYahoo!BlogならRedirectorで/web/2/に飛ばしてるよ
多分クロームにも似たような拡張あるだろう >>378
自分もこれ…savingのまま一向に動かない
検索しても取れてない… /save/
520 Unknown Error
failed to archive the URL. specifics of failure is unknown 520エラーでも数日後に見ると保存されるケースとされてないケースがあってよくわからん 保存されるケースだけなら困らないが
されてないケースがあるから困る キャプチャまでの待ち時間がとんでもない事になってるけど
あれってタブ閉じるとダメなのかな?
内部的には処理待ち行列に入ってるとかならいいんだが The capture is estimated to start in 0 minutes.
今待ち時間0分になってる
save/でもすぐに保存されてるし、やっと緩和したかな
これが続けばありがたいんだが 保存待ち状態もAPIで判別可能ならもっといいんだけどな 平常通りと言いたいとこだけど、上部の棒グラフみたいな外観のリンクがバグってる 24h後に再度試してもスナップショットがThis page is available on the web!になるな お 保存成功
>396になった分はノーカンだから相当な足止めだな なんだこれ気持ちわりいw ほぼノータイムで保存されたw The same snapshot had been made 1 minutes and 3 seconds ago.
We only allow new captures of the same URL every 20 minutes. 同じURL保存の待ち時間が20分になったな
jsonになってしまう事も結構あるのにこれはつらい… IPアドレス変えたりsave nowとアドレスバーにsave直打ちとかで同じかどうかも判定変わるから
いろいろ試せば1分未満でも再保存できる場合もあるよ x-archive-wayback-runtime-error: WaybackException: java.lang.IllegalStateException: Payload size does not match content-length!
ここ数日このエラー多すぎ todayスマホからアクセスするとCAPTCHAの無限ループなんだけどこれって俺だけ? 俺もなるわ
どうやらユーザーエージェントでブロックしてるらしい
別のブラウザアプリ使えば回避できる 無限リキャプチャなんだこれ…って思ったら同じ人がいて安心した ワープ用の棒グラフをクリックするとこんなふざけたアドレスに飛ばされる。当然表示できない。
https://web.archive.org/web/20130821015518if_/http://*****.com/web/20191201000000/http://*****.com/ 保存されてたはずのページが今日確認したらされてなかったことに・・・
特に今年7月あたりがひどい。 以前はちゃんと保存されて見れてたのなら、サイト運営者からの削除申請があったとかでもない限りは一時的なトラブルだから待ってれば直る 保存直後は問題なく見れるが数日後は無くなってるのが多いね
保存失敗したならちゃんと失敗したとエラー表示出して欲しい >>418
見られなくなるのは一時的で数日後にはちゃんと見えるようになる
urlをブクマして確かめてみろ URLから日付を選ぶページで保存元(Reason:)がNo Collection Infoって表示が出てるのは時間かかってるっぽい
保存されたらlivewebかsave-nowになるはず >>418
単にインデクシング階層で情報の表示に失敗してるだけで、サーバ内部にはちゃんと保存されてる
待ってれば直る noteのIP漏洩事案だけど、Wayback MachineのアーカイブのソースにIP情報が残ってる記事が結構あるらしい
削除申請が出される可能性があるから、noteのアーカイブを取ったことのある人は改めて保存し直しておくことを推奨 IA側がIPアドレスは個人情報じゃないので削除却下と行ってきたらどうすんの?
個人的には今回の件どうでもいいと思ってるし、note運営がどうこういう話じゃないしな IPアドレスはEUの一般データ保護規則で個人情報とされてるからIA側が却下する可能性は微妙
もちろんnote運営を介さないと削除申請は出せないはずだけど、
某自主制作コミュニティで「note運営に働きかけて記事のアーカイブを削除してもらおう」
って動きがあったのを見かけたものだから念の為と思ってね 運営に言わずに自分や自社のブログを消したいなら自分で削除依頼出せばいいのにな
初めっからやる気なさそう 今気付いたんだけど、削除申請を受けてWayback Machineから恒久的に削除されたサイトでも
スクリーンショット機能を使えば普通に保存・閲覧出来るんだな
(つまりスクリーンショットはWayback Machine削除申請の影響を受けない?
単にスクリーンショット機能実装以前に削除されたからかもしれないけど)
既出ならすまない × スクリーンショット機能実装以前に削除されたから
○ スクリーンショット機能実装以前に削除されたページだったから >>425
Internet Archiveの削除申請は「自分がそのサイト本体の管理者であることが確実にわかる証拠」を提示しないといけない
だから多分自力じゃ厳しいと思う 削除申請してる時間あるならルーター再起動するなりすればいいだけじゃないんかね…
ipバレてビビるとか古のネット民じゃないんだから >>426
スクショ機能なんて使う場面ないだろと思ってたけどそういう使い道があったか 普通のサイト保存→
HTML/CSS/JSなどを実行した結果のデータやアクセス日時などの情報を、WARCファイルという専用フォーマットにまとめて保存する。WARCの表示には専用のビューワが必要
スクリーンショット→
ページのスクリーンショットを撮った画像ファイルを保存する。やってることはスマホやパソコンのスクリーンショットと違いはない
要は保存する方法が全く違う >>434
URLの先頭にarchive.orgのものが付く以外は普通のURLと変わらないので分かる 表示中のアーカイブサイトのどこを押せばサイト内容まとめたWARCファイルとやらをDL出来んの 別にわざわざWARC落とさなくても、ブラウザのWayback Machineで表示されてるのがWARCの内容だぞ
アーカイブされたサイトはWARCファイルとしてまとめられ、Internet Archiveのサーバに保存される
Wayback Machineは、サーバ内のWARCを呼び出してブラウザで見れるように適切に変換しているだけ /save/の保存制限ってここ数日は緩和されてる?
時間なかったのでダメ元で何ページか同時に/save/の後ろにURLつけてブラウザで開いてみたら
去年の後半以降からずっと出てた「制限に達したから5分待ってください」のエラーが全く出ずに保存できた 保存時に画像やスクリプトファイルで待たされるのは
去年の快適だったころとは比べてまだ元通りではないけど、ちょっとストレス減った ローカルhtmlにsave/httpのリンク複数貼って
それ一斉に開いたらちゃんと保存されてんの? 本当だ
しかもnoteの以前のドメイン(note.mu)の方は完全にブロックされてる
Twitterでは8月上旬までこのドメインの魚拓が共有されてるからIP流出事件後にブロックされたっぽい
https://i.imgur.com/BAAGgrQ.jpg >>442
されてると思う
まとめて大量にするとToo Many Requestsエラーで漏れがでる可能性はあるけど >>423みたいな懐疑的意見もあったけど、個人的には予想通りの措置って感じだな...
robots.txt見たらia_archiverとmegalodonをブロックしてた robots.txtでブロックしてようがIAのバグで保存しちゃう方法はあるので、
Noteがサービス終了してrobots.txtの規制解除まで見るのだけはお預けだね サービス終了しても解除されない場合があるからそんなに楽観的には見れないな...
そういうサイトはおそらくメールの申請で、Wayback Machineから恒久的に削除されてるんだと思われる excludedって削除じゃなくて除外処置じゃないっけ?確証は持てないけど
復活したアーカイブは見たことあるけどそのままの例は知らないので教えて欲しい 自分が知ってる例は、URLは忘れてしまったけど、
だいたい10年近く前に閉鎖された版権作品の二次創作小説投稿サイトだった
2, 3年前にそのサイトのアーカイブをWayback Machineで見ようとしたんだが、
"このサイトはWayback Machineから削除されました"というような内容のエラーメッセージが出て見れなかった >>448
IAに除外要請を出しておいて、サービス終了時に再度
「うち辞めるから、もう見せても良いですよ」とか通知する奴が居たらアホだなw
実際に削除してるのか、単に非表示フラグを立ててるだけなのかは知らんけど。 心配しなくとも炎上させたいネットストーカーされてるところは他で流出するがな
5chや通販サイト等のクレカ含めた個人情報しかり
ここに挙がらないアーカイブサイトで取った魚拓はまだ残ってるし
マイナー過ぎていつ消えるか分からないけど晒すと使えなくなるから輸出してるが証拠能力が下がるのが悩み >> web archiveは robots.txt での制御をしばらく前にやめている。
>> ドメインオーナーとしての個別連絡も同時期にやっていると思われる。
https://twitter.com/bulkneets/status/1300967926397194240
だそうな
IPアドレスはいわば「準・個人情報」にあたるものだし、
非表示の申請を出すこと自体は企業の対応として真っ当だし当然だとは思うけど、アーカイブできなくなるのは非常に困る
https://twitter.com/5chan_nel (5ch newer account) >> web archiveは robots.txt での制御をしばらく前にやめている。
>> ドメインオーナーとしての個別連絡も同時期にやっていると思われる。
https://twitter.com/bulkneets/status/1300967926397194240
だそうな
IPアドレスはいわば「準・個人情報」にあたるものだし、
非表示の申請を出すこと自体は企業の対応として真っ当だし当然だとは思うけど、アーカイブできなくなるのは非常に困る
https://twitter.com/5chan_nel (5ch newer account) 非表示にされたサイトでもスクリーンショットで保存できるテクニック、noteでも行けるわ
今試したら問題なく取れた
https://web.archive.org/web/20200903074132/http://web.archive.org/screenshot/https://note.com/ スクショはアーカイブデータとして見ると微妙なのがね・・・(単に見る分には良いけど)
全く取れないよりはましだけども アーカイブ見ようとすると時々出る。いつも出るわけではない。更新で解決するときとしないときがある。
> ページの自動転送設定が正しくありません
> web.archive.org への接続中にエラーが発生しました。
> Cookie を無効化したり拒否していることにより、この問題が発生している可能性もあります。 すみません、どなたかスクリーンショットでのアーカイブのやり方を教えていただけませんか?
ぐぐっても分からずじまいでしたので
よろしくお願いいたします Sorry.
This snapshot cannot be displayed due to an internal error. noteってアーカイブできない?
いくらやってもHrmになっちゃう >>460
https://blog.archive.org/wp-content/uploads/2019/10/SPN-1.png
続きです
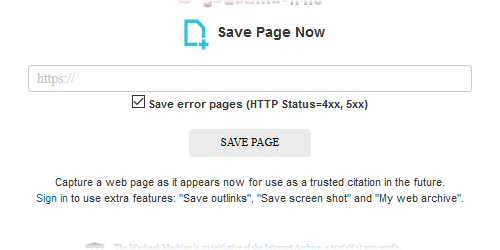
「save page now」を押してもこのチェックボックスがすべて出ず「save error pages」のチェックボックスしか出ないのです
何かアカウント登録とか必要なのでしょうか? >>463
Sign in to use extra features: "Save outlinks", "Save screen shot" and "My web archive".
中学英語でも十分理解できる文章だと思うけどねぇ。
 homepage2.nifty.comってWayback Machineで非表示になってるのか... ↑これどうにかならいあのんかな
homepage2.nifty.comってWayback Machineで非表示になってるのか... ↑これどうにかならいあのんかな
niftyのhomepageなんてもう終わってるのに Wayback Machineで非表示になってるサイトでも、
自前でクローラ動かしてWARC作ってInternet Archiveにアップロードすれば一応アーカイブを残すこと自体は出来るんだけどね...
APIを活用した支援ソフトを作ることや、WARCファイルの取り扱い方を幅広い人に周知することが重要になりそうだ Save outlinksがアカウント必須になったのってどういう事情なのかね
やっぱり容量が逼迫してるから? ■ このスレッドは過去ログ倉庫に格納されています


