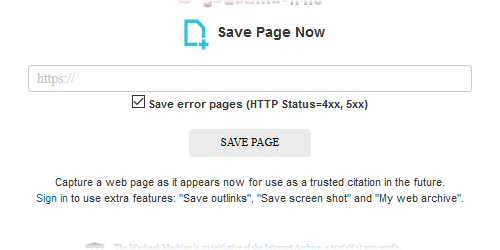
IPアドレスはいわば「準・個人情報」にあたるものだし、 非表示の申請を出すこと自体は企業の対応として真っ当だし当然だとは思うけど、アーカイブできなくなるのは非常に困る https://twitter.com/5chan_nel (5ch newer account) 0455名無しさん@お腹いっぱい。2020/09/03(木) 16:37:29.67 二重投稿になってしまった、すまない 0456名無しさん@お腹いっぱい。2020/09/03(木) 16:43:17.13 非表示にされたサイトでもスクリーンショットで保存できるテクニック、noteでも行けるわ 今試したら問題なく取れた https://web.archive.org/web/20200903074132/http://web.archive.org/screenshot/https://note.com/0457名無しさん@お腹いっぱい。2020/09/05(土) 11:20:03.73 スクショはアーカイブデータとして見ると微妙なのがね・・・(単に見る分には良いけど) 全く取れないよりはましだけども 0458名無しさん@お腹いっぱい。2020/09/05(土) 13:25:56.74 アーカイブ見ようとすると時々出る。いつも出るわけではない。更新で解決するときとしないときがある。 > ページの自動転送設定が正しくありません > web.archive.org への接続中にエラーが発生しました。 > Cookie を無効化したり拒否していることにより、この問題が発生している可能性もあります。 0459名無しさん@お腹いっぱい。2020/09/06(日) 01:34:21.61 ちょくちょく下の画面か503とかになるな… https://i.imgur.com/wFIxonH.png0460名無しさん@お腹いっぱい。2020/09/06(日) 23:16:00.13 すみません、どなたかスクリーンショットでのアーカイブのやり方を教えていただけませんか? ぐぐっても分からずじまいでしたので よろしくお願いいたします 0461名無しさん@お腹いっぱい。2020/09/07(月) 00:10:02.21 Sorry. This snapshot cannot be displayed due to an internal error. 0462名無しさん@お腹いっぱい。2020/09/07(月) 05:00:01.20 noteってアーカイブできない? いくらやってもHrmになっちゃう 0463名無しさん@お腹いっぱい。2020/09/07(月) 08:25:07.14>>460 https://blog.archive.org/wp-content/uploads/2019/10/SPN-1.png 続きです 「save page now」を押してもこのチェックボックスがすべて出ず「save error pages」のチェックボックスしか出ないのです 何かアカウント登録とか必要なのでしょうか? 0464名無しさん@お腹いっぱい。2020/09/07(月) 14:52:00.26>>463 Sign in to use extra features: "Save outlinks", "Save screen shot" and "My web archive". 中学英語でも十分理解できる文章だと思うけどねぇ。 0465名無しさん@お腹いっぱい。2020/09/07(月) 16:27:47.09 homepage2.nifty.comってWayback Machineで非表示になってるのか... 0466名無しさん@お腹いっぱい。2020/09/07(月) 17:20:20.83 ↑これどうにかならいあのんかな niftyのhomepageなんてもう終わってるのに 0467名無しさん@お腹いっぱい。2020/09/07(月) 19:00:05.38>>464 どうもありがとうございます 0468名無しさん@お腹いっぱい。2020/09/07(月) 20:31:13.49 Wayback Machineで非表示になってるサイトでも、 自前でクローラ動かしてWARC作ってInternet Archiveにアップロードすれば一応アーカイブを残すこと自体は出来るんだけどね... APIを活用した支援ソフトを作ることや、WARCファイルの取り扱い方を幅広い人に周知することが重要になりそうだ 0469名無しさん@お腹いっぱい。2020/09/08(火) 14:39:27.94 Save outlinksがアカウント必須になったのってどういう事情なのかね やっぱり容量が逼迫してるから? 0470名無しさん@お腹いっぱい。2020/09/08(火) 21:41:40.80 みんなはスキャンしてみたい本はある? 0471名無しさん@お腹いっぱい。2020/09/08(火) 21:57:00.84>>469 容量というかアーカイブ先サイトへのDOS攻撃っぽくなっちゃうからじゃね? 前は同一URLの保存間隔すら無かったし 0472名無しさん@お腹いっぱい。2020/09/08(火) 23:04:42.17>>470 本は流石に日本の著作権法上難しいからスキャンして上げる勇気はないな 0473名無しさん@お腹いっぱい。2020/09/09(水) 14:34:19.54 青空文庫の対象になっている本だけにしておこう。 0474名無しさん@お腹いっぱい。2020/09/09(水) 16:24:22.16>>471 以前はリンク先辿るのは50個までって制限あった気がするけど今やったら58個辿った もしかして50個制限を解除する代わりに相手先に過負荷を懸念してアカウント必須にしたんかね 0475名無しさん@お腹いっぱい。2020/09/10(木) 18:29:24.96>>472 海外も同じ? 0476名無しさん@お腹いっぱい。2020/09/10(木) 20:53:03.63>>475 アップロード操作が日本で行われる以上は、 フェアユースを認めていない日本法が絡んでくる。 0477名無しさん@お腹いっぱい。2020/09/12(土) 15:50:29.35>>476 そのうち海外でも違法になるし、削除対象になるな。 0478名無しさん@お腹いっぱい。2020/09/12(土) 19:01:28.95>>477 はぁ? アホか 0479名無しさん@お腹いっぱい。2020/09/12(土) 19:15:32.10>>477 頭悪そう 0480名無しさん@お腹いっぱい。2020/09/12(土) 19:54:33.10 多分中国人なんだろ 例の国家保安法みたいに、国外での行為も国内で処罰対象になるとか言うやつ 0481名無しさん@お腹いっぱい。2020/09/16(水) 12:31:27.10 著作権法は「送信元の国」と「送信先の国」どちらの法律を適用するかで見解が分かれること自体は事実だから、あながち間違ってるわけでもない 合ってるわけでもないのが微妙な点だけど 0482名無しさん@お腹いっぱい。2020/09/16(水) 19:20:01.19 【ネット】1000万件以上の研究論文がオンライン上から消失することを防ぐインターネットアーカイブの取り組みとは? [すらいむ★] https://egg.5ch.net/test/read.cgi/scienceplus/1600244016/0483名無しさん@お腹いっぱい。2020/09/18(金) 08:59:11.97 今ってYahoo知恵袋アーカイブできるようになってるんだね 昔はできなかった記憶 0484名無しさん@お腹いっぱい。2020/09/18(金) 09:41:08.71 Yahooの件はさんざん既出 0485名無しさん@お腹いっぱい。2020/09/20(日) 00:05:31.29 Temporarily Offline The Internet Archive's sites are temporarily offline. We apologize for the inconvenience. 0486名無しさん@お腹いっぱい。2020/09/20(日) 07:21:40.11>>473 あとはフリーのWeb小説やWeb漫画だね 0487名無しさん@お腹いっぱい。2020/09/20(日) 11:05:31.96 pixivって閉鎖はされなそうだけど、作品は自主削除が多発するしな。 0488名無しさん@お腹いっぱい。2020/09/20(日) 11:59:03.96 epubファイルをアップロードすると、その場で、ページをめくって内容を確認できるようになった。
便利。 0489名無しさん@お腹いっぱい。2020/09/20(日) 18:26:41.77 pixivをWayback Machineでアーカイブすると英語版が保存されるんだよね Internet Archiveのサーバがアメリカにあるためだと思われる 0490名無しさん@お腹いっぱい。2020/09/20(日) 20:31:33.86 リアリー? 04914892020/09/20(日) 21:54:54.16>>490 試してみたら? 今まで自分がやったやつは全部そうなったし今試してみてもそうなった https://web.archive.org/web/20200920125157/https://www.pixiv.net/en/artworks/84437660 0492名無しさん@お腹いっぱい。2020/09/21(月) 12:54:15.78 こっちの環境だけかな? 今朝から新規の保存をしても反映されない様で… 0493名無しさん@お腹いっぱい。2020/09/21(月) 13:28:38.55 We can't retrieve all the files we need to display that page. Please try again later.
今朝からこのエラーばっかり、時間置いても同じエラー出る 0494名無しさん@お腹いっぱい。2020/09/21(月) 15:08:51.20 俺も保存できてない。 APIもShow Allも反応なし 0495名無しさん@お腹いっぱい。2020/09/21(月) 16:58:59.37 今朝からのエラーまだ直ってないのか 0496名無しさん@お腹いっぱい。2020/09/22(火) 00:15:15.42 おま環かと思ったら俺の他にも取れない人いたのか 0497名無しさん@お腹いっぱい。2020/09/22(火) 01:10:54.32 ブログから Cloudflare and the Wayback Machine, joining forces for a more reliable Web ttps://blog.archive.org/2020/09/17/internet-archive-partners-with-cloudflare-to-help-make-the-web-more-useful-and-reliable/ クラウドフレアと連携